Long Horizon
Long Horizon ist ein agentisches Tool für Frontend-Tests: plant, schreibt und führt Browser-Tests aus und erstellt teilbare Reports mit Logs & Screenshots.
Was ist Long Horizon?
Long Horizon ist ein agentisches Tool für Frontend-Tests, das einen Coding-Agenten plant, Tests für eine Web-Anwendung erstellt und in einem echten Browser ausführt. Sein Kernzweck ist es, Teams dabei zu helfen, Features in einem realen Browser zu überprüfen und Probleme mit überprüfbaren Belegen aufzuzeigen.
Statt nur Tests zu generieren, führt Long Horizon sie in einer echten Browser-Sitzung aus und erzeugt teilbare Ausführungsberichte. Diese Berichte enthalten Ausführungslogs und Anhänge wie Screenshots und Netzwerkdetails, die Debugging und reproduzierbare Testläufe unterstützen.
Wichtige Features
- Agent-gesteuerte Testplanung aus Feature- und Repository-Kontext
- Der Agent entwirft, was getestet werden soll (Kernpfade, Edge-Cases und Fehlszenarien) basierend auf Feature- und Repo-Eingaben.
- Automatisierte Testausführung im Browser
- Tests laufen in einem echten Browser, sodass Assertions echtes UI-Verhalten und Netzwerkinteraktionen widerspiegeln.
- Teilbare Ausführungsberichte mit Logs und Anhängen
- Ausgaben sind für Reviews konzipiert, inklusive Ausführungslogs und Artefakten wie Screenshots.
- Zuverlässige, reproduzierbare Läufe
- Der Workflow betont wiederholbare Sitzungen, damit Fehler nachvollzogen und verstanden werden können.
- Testautorisierung direkt in Projekt-Testdateien
- Der Agent schreibt Tests in Ihr Projekt (Beispiele umfassen mehrere checkout-bezogene Testdateien).
- Debugging-Workflow für fehlgeschlagene Tests
- Bei Fehlern identifiziert der Agent die Ursache und schlägt Änderungen vor; Entwickler können Logs prüfen und bei kniffligen Szenarien helfen.
- Slow Mode / Step Mode für manuelle Inspektion
- Läufe können in Modi ausgeführt werden, die Entwicklern helfen, Verhalten bei Fehlern oder komplexen Flows zu beobachten.
- UI-Feedback zur Steuerung von Agent-Änderungen
- Nutzer können direkt in der UI Feedback geben mit elementbezogenen Kommentaren; der Agent berücksichtigt Kontext wie Screenshots und Element-HTML.
So verwenden Sie Long Horizon
- Starten Sie mit einem Feature in Entwicklung und geben Sie dem Agenten den relevanten Repo-Kontext.
- Lassen Sie den Agenten einen Testplan für das Feature entwerfen (inklusive Happy Paths, Edge-Cases und Fehler-Szenarien).
- Lassen Sie den Agenten die Tests in Ihr Projekt schreiben, dann die Tests in einem echten Browser ausführen.
- Prüfen Sie den generierten Ausführungsbericht inklusive Logs und angehängter Screenshots.
- Bei Testfehlern nutzen Sie den Debugging-Workflow – prüfen Sie die Fehlermeldung, lassen Sie den Agenten Fixes vorschlagen und führen Sie erneut aus.
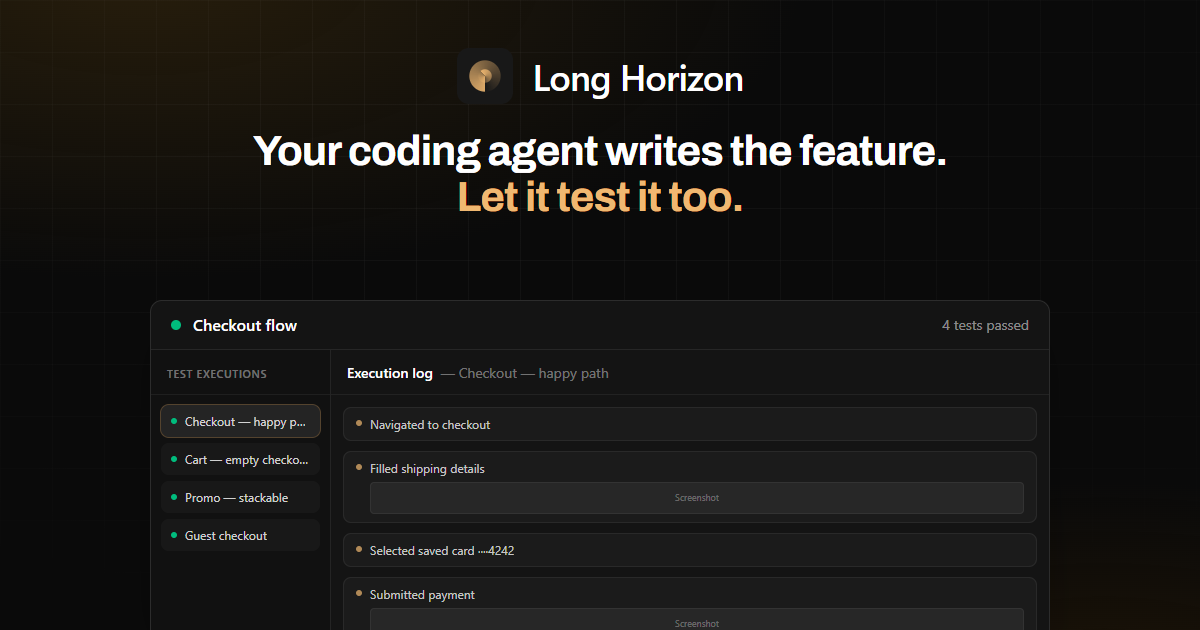
In den Beispielen umfasst der Workflow die Planung von Checkout-Szenarien (z. B. „checkout — happy path“, „cart — empty checkout blocked“ und „payment — decline and retry“), deren Ausführung in einer Browser-Session und die Validierung von Assertions wie Bestätigungs-IDs und DOM-Sichtbarkeit.
Anwendungsfälle
- Checkout Happy-Path-Regression für angemeldete Nutzer
- Führen Sie ein agent-geplantes Szenario aus, in dem ein angemeldeter Nutzer einen Kauf abschließt, und prüfen Sie, ob die Bestätigungsroute erwartete Identifier rendert (z. B. Order-ID und E-Mail im DOM).
- Blockieren von Checkout bei leerem Warenkorb
- Validieren Sie, dass der Checkout-Call-to-Action bei leerem Warenkorb deaktiviert bleibt und keine zahlungsbezogenen Netzwerkaufrufe ausgelöst werden.
- Behandlung von Kartenablehnung und Retry-Flows
- Simulieren Sie eine abgelehnte Karte, bestätigen Sie die Anzeige eines Inline-Fehlers und prüfen Sie, ob Nutzer die Zahlungsmethode ändern und den Auftrag erfolgreich abschließen können.
- Testen von Gast-Checkout und E-Mail-only-Zahlungsflows
- Prüfen Sie ein Checkout-Szenario ohne Account und stellen Sie sicher, dass Vorab-Checks (wie im Quelltext genannte Fraud-Checks) vor der Zahlung erfolgen.
- Debugging und Beheben von Fehlern in komplexen Flows
- Bei Browser-Testfehlern durch unerwartete Blockaden (z. B. Inventar-Sperre beim Checkout) nutzen Sie Logs zur Problemerkennung, aktualisieren Sie Mocks/Stubs (z. B. Lagerbestand) und führen erneut aus.
FAQ
Erstellt Long Horizon Tests oder führt es sie nur aus?
Beides. Der Agent entwirft einen Testplan, schreibt Tests im Projekt und führt diese dann in einem echten Browser aus.
Welche Art von Ausgabe erzeugt Long Horizon nach einem Testlauf?
Ausführungsberichte sind teilbar und enthalten vollständige Ausführungslogs sowie Anhänge wie Screenshots, ergänzt um Details wie Netzwerkinformationen.
Können Entwickler Fehler überprüfen und Szenarien durchlaufen?
Ja. Der Workflow umfasst die Überprüfung von Ausführungslogs durch Entwickler sowie Optionen wie Slow Mode und Step Mode für manuelle Inspektion.
Wie funktioniert das Agent-Debugging?
Bei einem Testfehler erkennt der Agent, was kaputtgegangen ist, und schlägt Fixes vor; Entwickler können mithelfen, z. B. indem sie Mocks (wie Inventory) anpassen und denselben Test neu ausführen.
Wie können Teammitglieder dem Agenten bei Fixes Anleitungen geben?
Es gibt eine UI-Feedback-Schnittstelle, in der Nutzer Kommentare zu UI-Elementen hinterlassen können. Der Agent nutzt Screenshots, Kommentare und Element-HTML.
Alternativen
- Konventionelle Frontend-End-to-End-Test-Frameworks
- Tools der E2E-Kategorie können Browser-Tests ausführen, erfordern aber typischerweise mehr manuelle Testplanung und -erstellung statt agentengetriebener Planung, Erstellung und Ausführung.
- Skriptbasierte QA-Test-Suites mit manueller Triage
- Teams können skriptbasierte Tests schreiben und ausführen und dann mit Logs debuggen; der Unterschied ist, dass Long Horizon einen agentenunterstützten Workflow für Planung, Schreiben und Debugging betont.
- Agentische Workflow-Tools, die Tests ohne echte Browser-Ausführung generieren
- Manche Ansätze konzentrieren sich auf die Generierung von Testcode oder Reports; Long Horizon positioniert sich speziell um echte Browser-Ausführung mit überprüfbaren Ausführungsberichten.
- CI-basierte Browser-Test-Pipelines
- Continuous-Integration-Setups können Browser-Tests wiederholt ausführen; Long Horizon fokussiert auf agentische Test-Erstellung und teilbare Ausführungsberichte zur Unterstützung von Feature-Delivery und Debugging.
Alternativen
PromptLayer
PromptLayer unterstützt Teams dabei, Prompts und AI Agents mit Evals, Tracing und Regression Sets zu versionieren, zu testen und gemeinsam zu bearbeiten.
Evidently AI
Evidently AI ist eine Plattform für KI-Auswertung und LLM-Observability zum Testen und Monitoring von produktiven KI-Systemen mit RAG-Checks, Adversarial-Tests und Tracking.
Crikket
Crikket: Open-Source Bug-Reporting-Tool für Teams. Erfassen & teilen Sie technische Details zur schnelleren Fehlerbehebung. Jetzt entdecken!
Roo Code
Roo Code bietet ein KI-Softwareentwicklungsteam in deinem Editor und als Cloud-Agenten: role-spezifische Modes, steuerbare Aktionen und GitHub-Workflows.
Logic
Logic ist eine spec-basierte Agent-Plattform: aus geschriebenen Spezifikationen werden Production-APIs inkl. Tests, Versionierung, Model-Routing & Logging.
TestLaunch Pro
TestLaunch Pro ist ein bezahltes App-Test-Marktplatz: Entwickler kaufen opted-in Tester für Google Play Closed Testing, Tester laden Apps, geben Feedback und zahlen via PayPal aus.