PinchBench
Vergleiche die OpenClaw Agent-Performance über 100+ LLMs mit Success-Rate-Rankings: automatisierte Checks und LLM-gestufte Bewertungen.
Was ist PinchBench?
PinchBench ist eine OpenClaw-LLM-Modell-Benchmarking-Seite, die KI-Modelle nach Erfolgsrate bei standardisierten Coding-Aufgaben rankt. Ihr Kernzweck ist es, Ihnen zu helfen, mehrere LLMs mit demselben agentenbasierten Testsetup zu vergleichen, damit Sie ein Modell basierend auf gemessenen Ergebnissen statt Annahmen wählen können.
Die Seite zeigt „Success rate by model“-Rankings an und ermöglicht den Zugriff auf weitere Aufgaben und Bewertungsdetails. Sie gibt auch an, dass Bewertung und Scoring automatisiert mit automatisierten Checks und einem LLM-Judge erfolgen.
Wichtige Funktionen
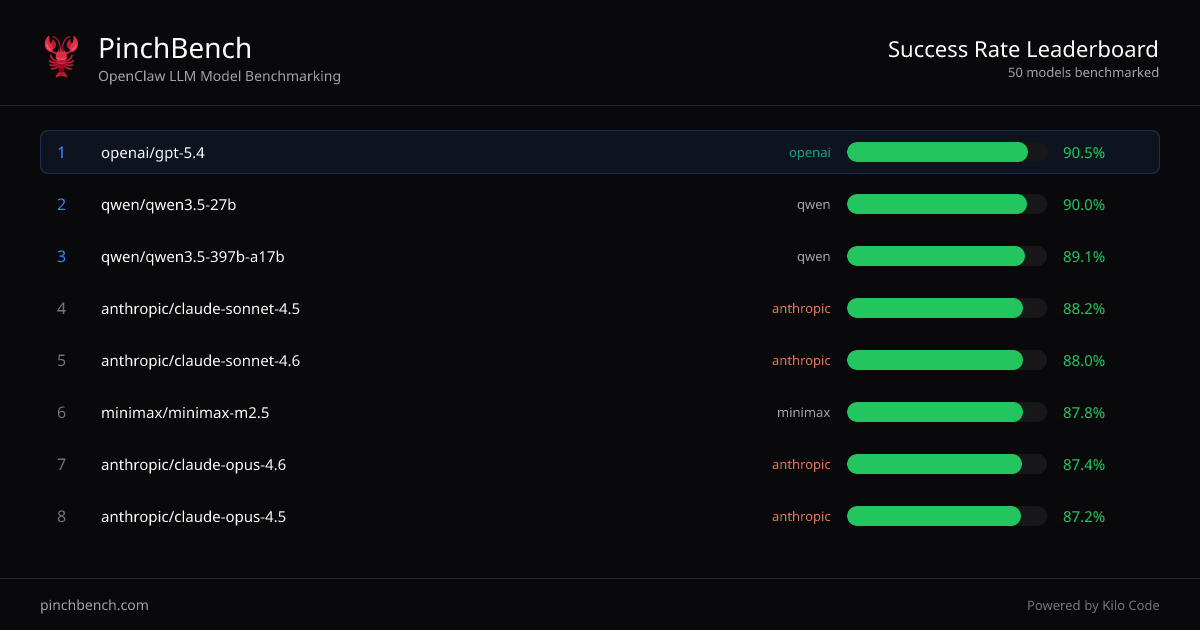
- Success-Rate-Rankings über Modelle hinweg: Zeigt eine sortierte Tabelle mit Modellen und Feldern wie „Best %“, „Avg %“ und verwandten Score-Spalten für konsistente Performance-Vergleiche.
- OpenClaw-Agent-Benchmarking: Bewertet Modelle speziell im Kontext eines „OpenClaw“-Agent-Workflows und spiegelt die Performance bei agentengesteuerten Coding-Aufgaben wider.
- Automatisierte Bewertung mit Checks und LLM-Judge: Scores basieren auf automatisierten Checks und einem LLM-Judge für eine wiederholbare Evaluierungsmethode.
- Budget-Filter (max. $ pro Run): Enthält einen Budget-Filter mit der Bezeichnung „Max $per run“, um Vergleiche innerhalb einer Kosteneinschränkung zu fokussieren, die in der Oberfläche angezeigt wird.
- Transparente Testmaterialien und Kriterien: Hinweis, dass „All tasks and grading criteria are open source“, und eine Möglichkeit, Aufgaben einzusehen.
So verwenden Sie PinchBench
- Navigieren Sie zu PinchBench und nutzen Sie die Model-Ranking-Tabelle, um Modelle nach Erfolgsrate zu vergleichen.
- Optional den Budget-Filter mit der „Max $ per run“-Steuerung anpassen, um Ergebnisse auf Modelle zu beschränken, die in Ihr Kostenlimit passen.
- Aufgabenansichten und Bewertungsdetails (inkl. offener Bewertungskriterien) nutzen, um zu verstehen, was die Scores messen, bevor Sie ein Modell auswählen.
Anwendungsfälle
- Auswahl eines LLMs für einen OpenClaw-Coding-Agent: Kandidatenmodelle nach gemessener Erfolgsrate bei standardisierten Agent-Aufgaben vergleichen und die beste Option für Ihren Anwendungsfall wählen.
- Qualität vs. Durchschnittsperformance bewerten: Tabellenspalten „Best %“ und „Avg %“ nutzen, um Modelle mit hohen Peaks von solchen mit konsistenteren Ergebnissen zu unterscheiden.
- Kostenbewusster Modellvergleich: Den max. $ pro Run-Filter anwenden, um Modelle unter einem Budgetlimit zu vergleichen, bei gleicher Benchmark-Aufgaben.
- Überprüfen, wie Scores berechnet werden: Offene Aufgaben und Bewertungskriterien prüfen, um zu validieren, was „Erfolg“ im Benchmark bedeutet, und ob es zu Ihrem erwarteten Verhalten passt.
- Mehrere Provider in einer Ansicht vergleichen: Konsolidierte Rankings nutzen, um Modelle verschiedener Provider (wie in der Tabelle z. B. OpenAI, Anthropic, Qwen, Minimax und Google-Modelle) zu vergleichen.
FAQ
-
Wie bestimmt PinchBench die Erfolgsrate eines Modells? Die Erfolgsrate wird als Prozentsatz erfolgreich abgeschlossener Aufgaben über standardisierte OpenClaw-Agent-Tests gemessen, mit automatisierten Checks und einem LLM-Judge.
-
Kann ich sehen, was die Benchmark-Tests umfassen? Ja. Die Seite bietet Optionen zum Ansehen der Aufgaben und gibt an, dass Aufgaben und Bewertungskriterien Open Source sind.
-
Welche Metriken werden in den Rankings angezeigt? Die Ranking-Tabelle enthält erfolgsbezogene Prozentfelder wie „Best %“ und „Avg %“ (mit zusätzlichen Score-Spalten in der Oberfläche).
-
Gibt es eine Möglichkeit, Modelle nach Kosten zu filtern? Die Oberfläche enthält einen Budget-Filter mit der Bezeichnung „Max $per run“, den Sie nutzen können, um die angezeigten Ergebnisse einzuschränken.
-
Bewertet PinchBench allgemeine Chat-Qualität? Die Seite benchmarkt Modelle speziell bei OpenClaw-Agent-Coding-Aufgaben, und die angezeigte Erfolgsrate bezieht sich auf diesen standardisierten Benchmark-Kontext.
Alternativen
- Allgemeine LLM-Leaderboards: Breite, nicht-aufgabenspezifische Rankings eignen sich für einen schnellen Überblick, messen aber typischerweise keine Performance bei OpenClaw-Agent-Coding-Aufgaben.
- Eigene Evaluierungs-Harnesses / interne Benchmarks: Ein kuratiertes Set an Coding-Aufgaben ausführen und Ihre Bewertungsmethode anwenden passt besser zu Ihren Anforderungen, erfordert aber Setup und laufende Wartung.
- Provider-spezifische Evals und Benchmarks: Einige Anbieter veröffentlichen Performance-Ergebnisse; diese können in Aufgabendesign und Bewertung von PinchBench abweichen, daher Vergleiche vorsichtig behandeln.
- Agent-Framework-Evaluierungstools: Tools zum Testen von LLMs mit Agent-Workflows liefern workflow-nahe Ergebnisse, bieten aber nicht denselben standardisierten Cross-Model-Benchmark und offene Bewertungskriterien wie PinchBench.
Alternativen
AakarDev AI
AakarDev AI ist eine leistungsstarke Plattform, die die Entwicklung von KI-Anwendungen mit nahtloser Integration von Vektordatenbanken vereinfacht und eine schnelle Bereitstellung und Skalierbarkeit ermöglicht.
BookAI.chat
BookAI ermöglicht es Ihnen, mit Ihren Büchern zu chatten, indem Sie einfach den Titel und den Autor angeben.
skills-janitor
skills-janitor prüft, verfolgt die Nutzung und vergleicht deine Claude Code Skills mit neun Slash-Command-Aktionen – ohne Abhängigkeiten.
FeelFish
FeelFish KI-Roman-Schreib-Agent: PC-Client für Autor:innen zum Planen von Figuren und Settings, Generieren und Überarbeiten von Kapiteln sowie Plot-Fortsetzung mit Kontextkonsistenz.
BenchSpan
BenchSpan führt KI-Agent-Benchmarks parallel aus, erfasst Scores und Fehler in einer geordneten Run-Historie und macht Ergebnisse commit-gebunden reproduzierbar.
ChatBA
ChatBA ist generative KI für Slides: Erstelle mit Chat-Workflow schnell Inhalte für Präsentationsfolien direkt aus deiner Eingabe.