Production-oriented RAG
Agentset is built for production RAG, with a focus on reliable answers, citations, and retrieval quality rather than demo-only workflows.
Agentset is an open-source platform for building AI chat and search on top of private or internal knowledge bases. It helps developers ship production-oriented RAG with citations, multimodal document support, and plans for free, Pro, and enterprise use.
Agentset is an open-source platform for building AI chat and search experiences on top of private or internal knowledge bases. It is positioned for developers who want production-ready RAG without building and maintaining the entire retrieval pipeline themselves.
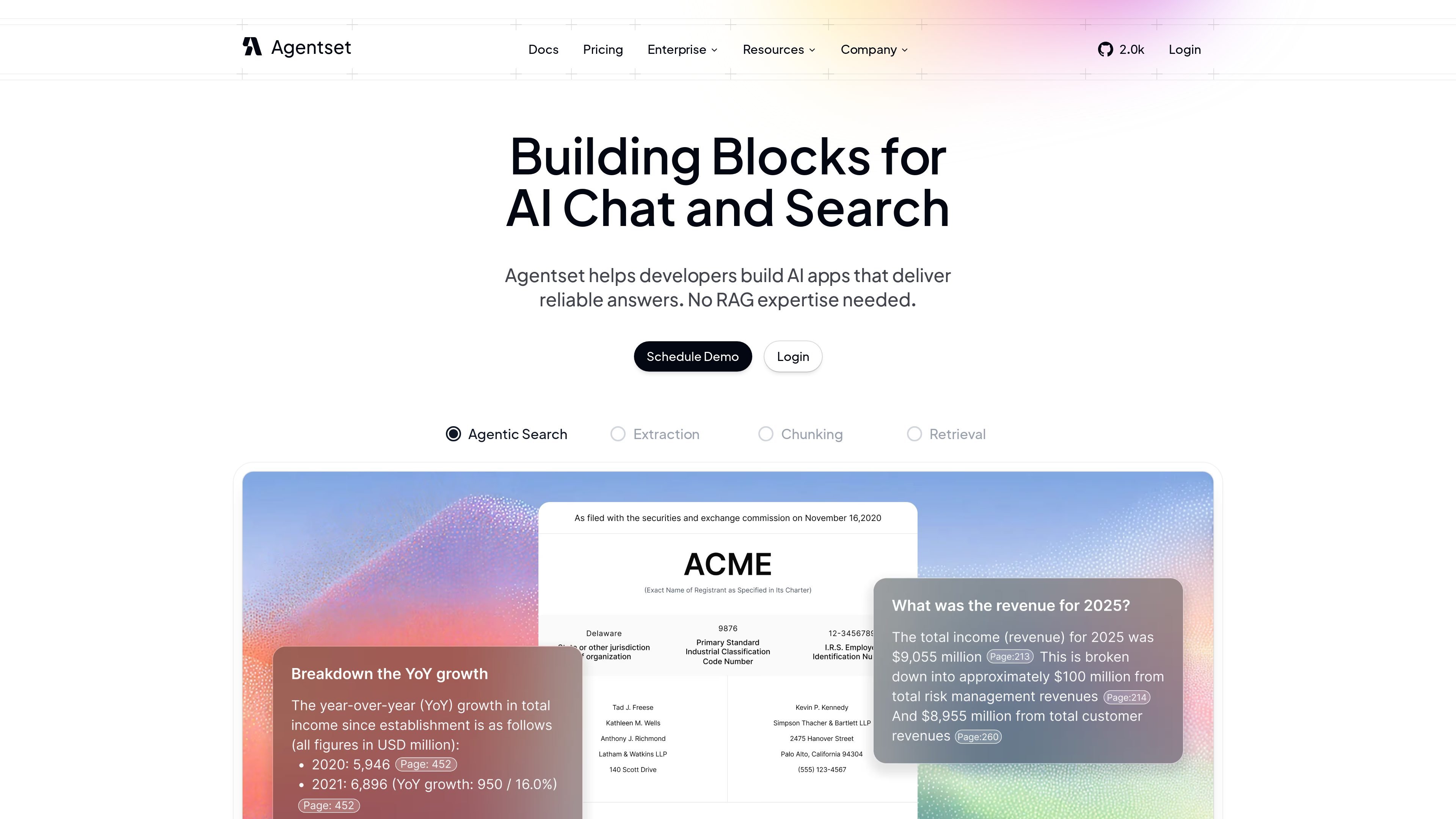
The product emphasizes reliable answers, citations, and support for real-world documents. Its home page highlights multimodal retrieval across text, images, graphs, and tables, while the pricing page shows tiers for free use, production applications, and enterprise deployments.
Agentset is built for production RAG, with a focus on reliable answers, citations, and retrieval quality rather than demo-only workflows.
The platform supports images, graphs, and tables alongside text so users can ask questions across richer document sets.
Answers can include source citations, which lets users inspect where a response came from and review supporting material.
Metadata filters let teams narrow retrieval to a subset of content when they need scoped answers.
Developers can ingest content through JavaScript and Python SDKs, with support for 22+ file formats and an MCP server for external applications.
Agentset can work with an AI SDK integration and lets teams choose their own vector database, embedding model, and LLM.
Build a chat or search layer over internal documents and knowledge bases where answers need citations and controlled retrieval instead of generic chatbot responses.
Index document libraries that include PDFs, HTML pages, office files, and other supported formats, then let users search across them with filtering and source tracing.
Connect external sources such as Google Drive, SharePoint, or Notion so content stays synchronized with the knowledge base as those systems change.
Expose the same knowledge base to other applications through the MCP server or AI SDK integration when you need the retrieval layer inside a larger product.
Use the platform for teams that need production deployment options, custom workflows, or enterprise support rather than a single-purpose prototype.
Agentset is an infrastructure product for developers building production-ready RAG applications. The home page describes it as a platform for search and Q&A inside products, and the pricing page shows plans for personal use, production applications, and enterprise workflows.
The source does not present a detailed setup flow, but it does show JavaScript and Python SDKs, an MCP server, and an AI SDK integration, which suggests it is intended to plug into existing development stacks.
Agentset supports file-based ingestion for many common formats, including text, HTML, PDF, and office-style documents, and it also supports external data connectors for services such as Google Drive, SharePoint, and Notion.
Yes. The pricing page includes a Free plan, a Pro plan for production applications, and an Enterprise plan with custom workflows and deployment options. The site also says plans can be upgraded or downgraded.
The source shows that Agentset can return citations and source references with answers, and it supports metadata filtering, hybrid search, reranking, and multimodal content such as images, graphs, and tables.
AakarDev AI helps teams manage AI provider access, project-level setups, logs, and analytics from one dashboard. It supports BYOK workflows and lists providers including OpenAI, Google Gemini, Anthropic, Groq, Mistral AI, and Perplexity AI.
ByteAsk is a terminal-first AI coding agent for C and C++ that edits repositories and verifies changes with the real compiler, debugger, sanitizers, and tests before showing a diff. It offers a free tier plus paid plans, with editor connectors and zero-retention handling described in the source.
Codex Plugins bundle reusable skills, app integrations, and MCP servers into workflows you can install in the Codex app or use from Codex CLI. They help extend Codex with connected-service tasks, reusable instructions, and shared team workflows.
hob is an independent workspace for coding agents that keeps agent sessions, terminals, history, and follow-up work organized around the tools and providers you already use. It is aimed at developers who want local control over routing, history, and workspace structure rather than a bundled model stack.
Ably Chat is a chat API platform for building custom realtime chat applications. It supports room-based messaging, typing indicators, presence, reactions, and message updates, with usage-based pricing options for different deployment stages.
Wallie is an open-source AI streamer that watches your screen, hears chat, and generates live commentary in a configurable persona. It runs locally on your machine with your own keys and is aimed at faceless content, autonomous streams, and real-time reactions.