Long Horizon
Long Horizon es una herramienta de pruebas frontend agentic que planifica, escribe y ejecuta tests reales en navegador, con informes compartibles de ejecución.
¿Qué es Long Horizon?
Long Horizon es una herramienta de pruebas frontend agentic que permite a un agente de codificación planificar, escribir y ejecutar pruebas basadas en navegador para una aplicación web. Su propósito principal es ayudar a los equipos a verificar funciones en un navegador real y detectar problemas con evidencia revisable.
En lugar de solo generar pruebas, Long Horizon las ejecuta en una sesión real de navegador y produce informes de ejecución compartibles. Esos informes incluyen registros de ejecución y archivos adjuntos como capturas de pantalla y detalles de red, facilitando la depuración y ejecuciones de pruebas reproducibles.
Características clave
- Planificación de pruebas impulsada por agente desde el contexto de tu función y repositorio
- El agente redacta qué probar (rutas principales, casos límite y escenarios de fallo) basado en las entradas de la función y el repositorio.
- Ejecución automatizada de pruebas basadas en navegador
- Las pruebas se ejecutan en un navegador real, por lo que las afirmaciones reflejan el comportamiento real de la UI y las interacciones de red.
- Informes de ejecución compartibles con registros y adjuntos
- Las salidas están diseñadas para revisión, incluyendo registros de ejecución y artefactos como capturas de pantalla.
- Ejecuciones confiables y reproducibles
- El flujo de trabajo enfatiza sesiones repetibles para poder revisitar y entender los fallos.
- Escritura de pruebas en los archivos de pruebas del proyecto
- El agente escribe las pruebas en tu proyecto (los ejemplos mostrados incluyen múltiples archivos de pruebas relacionados con el checkout).
- Flujo de trabajo de depuración para pruebas fallidas
- Cuando una ejecución falla, el agente puede identificar qué falló y proponer cambios; los desarrolladores pueden revisar los registros y ayudar en escenarios complicados.
- Modo lento / modo paso para inspección manual
- Las ejecuciones pueden realizarse en modos diseñados para ayudar a los desarrolladores a observar el comportamiento durante fallos o flujos complejos.
- Retroalimentación en la UI para guiar cambios del agente
- Los usuarios pueden dejar comentarios directamente en la UI a nivel de elemento; el agente incorpora contexto como capturas de pantalla y HTML del elemento.
Cómo usar Long Horizon
- Comienza con una función en desarrollo y proporciona el contexto relevante del repositorio al agente.
- Pide al agente que redacte un plan de pruebas para la función (incluyendo rutas felices, casos límite y escenarios de error).
- Haz que el agente escriba las pruebas en tu proyecto, luego ejecute las pruebas en un navegador real.
- Revisa el informe de ejecución generado, incluyendo registros y capturas de pantalla adjuntas.
- Si una prueba falla, usa el flujo de trabajo de depuración: revisa la salida del fallo y deja que el agente proponga correcciones, luego vuelve a ejecutar.
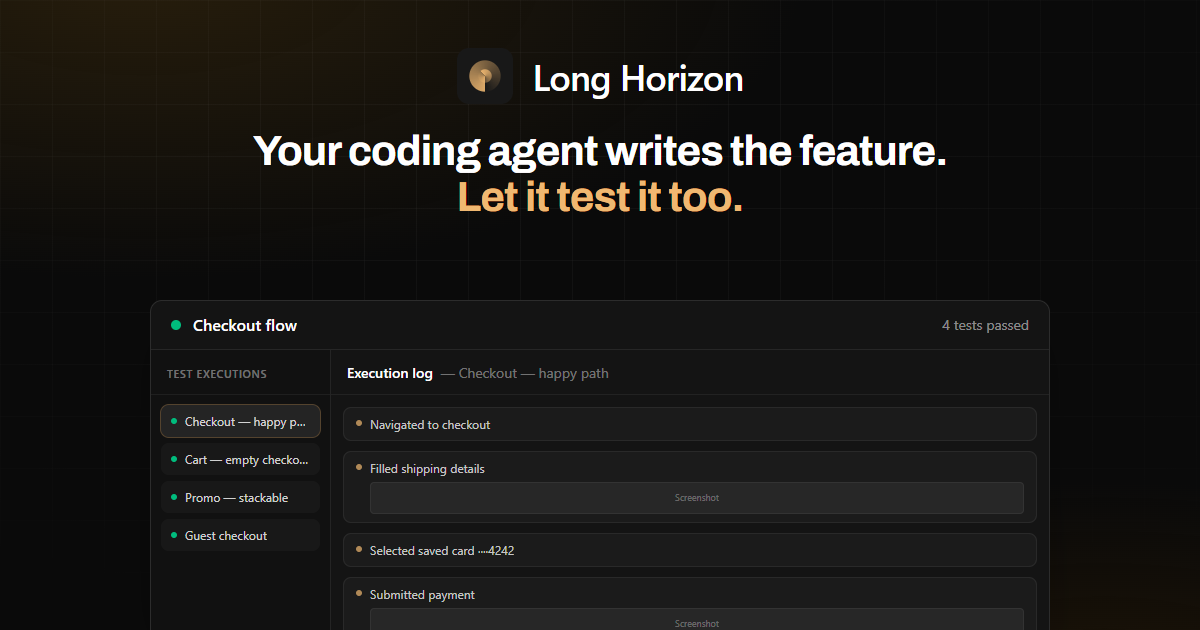
En los ejemplos proporcionados, el flujo de trabajo incluye planificación de escenarios para checkout (p. ej., “checkout — ruta feliz”, “carrito — checkout vacío bloqueado” y “pago — rechazo y reintento”), ejecución de esos en una sesión de navegador y validación de afirmaciones como IDs de confirmación y visibilidad del DOM.
Casos de uso
- Regresión de ruta feliz de checkout para usuarios registrados
- Ejecuta un escenario planificado por agente donde un usuario registrado completa una compra y verifica que la ruta de confirmación renderice identificadores esperados (p. ej., ID de pedido y email en el DOM).
- Prevención de checkout cuando el carrito está vacío
- Valida que la llamada a la acción de checkout permanezca deshabilitada cuando el carrito está vacío y que no se activen llamadas de red relacionadas con pagos.
- Manejo de flujos de rechazo de tarjeta y reintento
- Simula una tarjeta rechazada, confirma que se muestra un error en línea, y verifica que los usuarios puedan cambiar el método de pago y completar el pedido exitosamente.
- Pruebas de checkout de invitado y flujos de pago solo con email
- Verifica un escenario de checkout donde un usuario procede sin cuenta y asegura que ocurran verificaciones previas al pago (como las de fraude mencionadas en la fuente) antes del pago.
- Depuración y corrección de fallos en flujos complejos
- Cuando una prueba de navegador falla por una condición bloqueante inesperada (p. ej., control de inventario que bloquea el checkout), usa los registros para identificar el problema, actualiza mocks/stubs (como disponibilidad de stock) y vuelve a ejecutar.
Preguntas frecuentes
¿Long Horizon genera tests o solo los ejecuta?
Ambos. El agente elabora un plan de tests, crea tests en el proyecto y luego los ejecuta en un navegador real.
¿Qué tipo de salida produce Long Horizon después de una ejecución de tests?
Los informes de ejecución son compartibles e incluyen registros completos de ejecución y archivos adjuntos como capturas de pantalla, con detalles adicionales como información de red.
¿Pueden los desarrolladores revisar fallos y avanzar paso a paso en los escenarios?
Sí. El flujo de trabajo incluye revisión por parte de desarrolladores de los registros de ejecución y opciones como modo lento y modo paso para inspección manual.
¿Cómo funciona la depuración del agente?
Cuando un test falla, el agente puede identificar qué falló y sugerir correcciones; los desarrolladores también pueden ayudar, por ejemplo ajustando mocks (como inventario) y reejecutando el mismo test.
¿Cómo pueden los miembros del equipo proporcionar orientación al agente durante las correcciones?
Se describe una interfaz de retroalimentación en la UI donde los usuarios pueden dejar comentarios en elementos de la UI. El agente usa la captura de pantalla, comentarios y HTML del elemento.
Alternativas
- Frameworks convencionales de pruebas end-to-end frontend
- Las herramientas de la categoría E2E pueden ejecutar tests en navegador, pero suelen requerir más planificación y creación manual de tests en lugar de planificación, creación y ejecución impulsadas por agente.
- Suites de tests QA scriptificados con triaje manual
- Los equipos pueden escribir y ejecutar tests scriptificados y depurar usando registros; la diferencia es que Long Horizon enfatiza un flujo de trabajo asistido por agente para planificación, escritura y depuración.
- Herramientas de flujos de trabajo agentic que generan tests sin ejecuciones en navegador real
- Algunos enfoques se centran en generar código de tests o informes; la propuesta de Long Horizon se basa específicamente en ejecución en navegador real con informes de ejecución revisables.
- Pipelines de pruebas en navegador basados en CI
- Las configuraciones de integración continua pueden ejecutar tests en navegador repetidamente; Long Horizon se centra en creación agentic de tests e informes de ejecución compartibles para apoyar la entrega de funciones y depuración.
Alternativas
PromptLayer
PromptLayer ayuda a versionar y probar prompts y agentes de IA con evals, tracing y conjuntos de regresión, además de un editor visual para colaborar.
Evidently AI
Evidently AI es una plataforma de evaluación y observabilidad LLM para probar y supervisar sistemas de IA en producción. Basada en Evidently.
Crikket
Crikket: plataforma de código abierto para reportar errores. Captura detalles técnicos al instante para resolver incidencias más rápido. Alternativa a jam.dev.
Roo Code
Roo Code ofrece un equipo de ingeniería con IA dentro del editor y agentes en la nube, con Modes por rol y flujos conectados a GitHub.
Logic
Logic es una plataforma de agentes basada en especificaciones que convierte specs en APIs listas para producción, con pruebas, versionado y logging.
TestLaunch Pro
TestLaunch Pro es un marketplace de pruebas de apps de pago: ayuda a desarrolladores a conseguir testers opt-in en Google Play y a testers a cobrar por PayPal.