PinchBench
Compara el rendimiento de agentes de OpenClaw en 100+ LLMs con rankings por tasa de éxito, verificaciones automatizadas y evaluación con LLM.
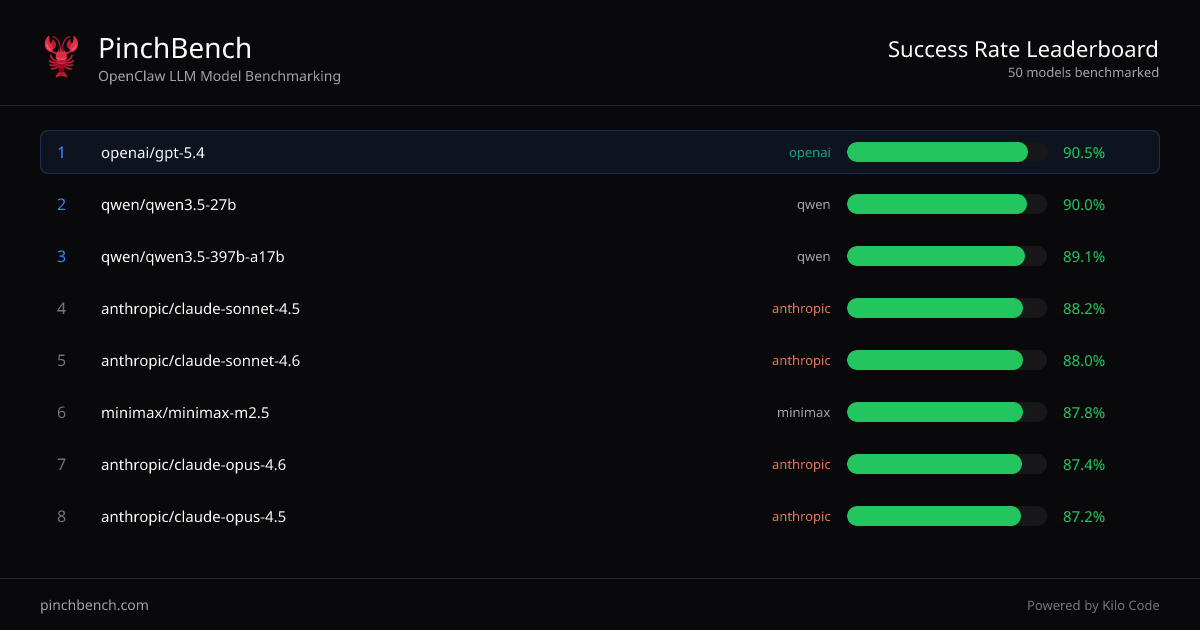
¿Qué es PinchBench?
PinchBench es un sitio de benchmarking de modelos LLM de OpenClaw que clasifica modelos de IA por tasa de éxito en tareas de codificación estandarizadas. Su propósito principal es ayudarte a comparar múltiples LLMs usando la misma configuración de pruebas basada en agentes, para que elijas un modelo según resultados medidos en lugar de suposiciones.
El sitio presenta rankings de “Tasa de éxito por modelo” y te permite ver más tareas y detalles de evaluación. También indica que la evaluación y puntuación son automatizadas mediante verificaciones automáticas y un juez LLM.
Características clave
- Rankings por tasa de éxito entre modelos: Muestra una tabla ordenada de modelos con campos como “Best %,” “Avg %” y columnas de puntuación relacionadas para comparar el rendimiento de forma consistente.
- Benchmarking de agentes OpenClaw: Evalúa modelos específicamente en el contexto de un flujo de trabajo de agente “OpenClaw”, reflejando cómo funcionan en tareas de codificación impulsadas por agentes.
- Evaluación automatizada con verificaciones y un juez LLM: Las puntuaciones se derivan de verificaciones automáticas y un juez LLM, proporcionando un método de evaluación repetible.
- Filtro de presupuesto (máx. $ por ejecución): Incluye un filtro de presupuesto etiquetado como “Max $per run”, que te permite centrar las comparaciones dentro de un límite de costo mostrado por la interfaz.
- Materiales y criterios de prueba transparentes: Indica que “All tasks and grading criteria are open source” y proporciona una forma de ver las tareas.
Cómo usar PinchBench
- Ve a PinchBench y usa la tabla de ranking de modelos para comparar modelos por tasa de éxito.
- Opcionalmente, ajusta el filtro de presupuesto con el control “Max $ per run” para reducir los resultados a modelos que se ajusten a tu límite de costo especificado.
- Usa las vistas de tareas y detalles de evaluación (incluyendo criterios de evaluación abiertos) para entender qué miden las puntuaciones antes de seleccionar un modelo.
Casos de uso
- Seleccionar un LLM para un agente de codificación OpenClaw: Compara modelos candidatos por tasa de éxito medida en tareas de agente estandarizadas, luego elige la mejor opción para tu caso de uso.
- Evaluar calidad vs. rendimiento promedio: Usa las columnas “Best %” y “Avg %” de la tabla para diferenciar modelos que destacan bien frente a aquellos con resultados más consistentes.
- Comparación de modelos consciente del costo: Aplica el filtro max $ per run para comparar modelos bajo un techo presupuestario, manteniendo las mismas tareas de benchmark.
- Revisar cómo se computan las puntuaciones: Verifica tareas abiertas y criterios de evaluación para entender qué significa “éxito” en el benchmark y si se alinea con tu comportamiento esperado.
- Comparar múltiples proveedores en una vista: Usa los rankings consolidados para comparar modelos de diferentes proveedores (como se muestra en la tabla, p. ej., OpenAI, Anthropic, Qwen, Minimax y modelos de Google).
Preguntas frecuentes
-
¿Cómo determina PinchBench la tasa de éxito de un modelo? La tasa de éxito se mide como el porcentaje de tareas completadas exitosamente en pruebas de agente OpenClaw estandarizadas, usando verificaciones automáticas y un juez LLM.
-
¿Puedo ver qué incluye las pruebas de benchmark? Sí. La página ofrece opciones para ver tareas, y afirma que las tareas y criterios de evaluación son de código abierto.
-
¿Qué métricas se muestran en los rankings? La tabla de ranking incluye campos de porcentaje relacionados con el éxito como “Best %” y “Avg %” (con columnas de puntuación adicionales visibles en la interfaz).
-
¿Hay forma de filtrar modelos por costo? La interfaz incluye un filtro de presupuesto etiquetado como “Max $per run”, que puedes usar para restringir los resultados mostrados.
-
¿Evalúa PinchBench la calidad general de chat? El sitio benchmarkea específicamente modelos en tareas de codificación de agente OpenClaw, y la tasa de éxito mostrada corresponde a ese contexto de benchmark estandarizado.
Alternativas
- Leaderboards generales de LLM: Rankings amplios y no específicos de tareas pueden ser útiles para un vistazo rápido, pero típicamente no miden rendimiento en tareas de codificación de agente OpenClaw.
- Harness de evaluación propio / benchmarks internos: Ejecutar un conjunto curado de tareas de codificación y aplicar tu enfoque de evaluación puede ajustarse mejor a tus requisitos, pero requiere configuración y mantenimiento continuo.
- Evals y benchmarks específicos de proveedores: Algunos proveedores publican resultados de rendimiento en benchmarks; estos pueden diferir en diseño de tareas y evaluación de PinchBench, por lo que las comparaciones deben tratarse con precaución.
- Herramientas de evaluación de frameworks de agentes: Herramientas que te permiten probar LLMs con flujos de trabajo de agentes pueden ofrecer resultados alineados con workflows, pero no necesariamente el mismo benchmark estandarizado entre modelos y criterios de evaluación abiertos que PinchBench.
Alternativas
AakarDev AI
AakarDev AI es una plataforma poderosa que simplifica el desarrollo de aplicaciones de IA con integración fluida de bases de datos vectoriales, permitiendo un despliegue y escalabilidad rápidos.
BookAI.chat
BookAI te permite chatear con tus libros usando IA simplemente proporcionando el título y el autor.
skills-janitor
skills-janitor audita y registra el uso de tus habilidades de Claude Code, comparándolas con 9 acciones de slash y sin dependencias.
FeelFish
FeelFish AI Novel Writing Agent para PC ayuda a planificar personajes y escenarios, generar y editar capítulos y continuar tramas con consistencia.
BenchSpan
BenchSpan ejecuta benchmarks de agentes con IA en paralelo, registra puntuaciones y fallos en un historial organizado y ayuda a reproducir resultados por commit.
ChatBA
ChatBA es IA generativa para crear presentaciones: redacta el contenido con un flujo tipo chat y genera diapositivas a partir de tu idea.