Long Horizon
Long Horizon est un outil de tests front agentic : il planifie, écrit et exécute de vrais tests navigateur, avec rapports partageables (logs & captures).
Qu'est-ce que Long Horizon ?
Long Horizon est un outil de tests frontend agentic qui permet à un agent de codage de planifier, rédiger et exécuter des tests basés sur navigateur pour une application web. Son objectif principal est d’aider les équipes à vérifier les fonctionnalités dans un vrai navigateur et à mettre en évidence les problèmes avec des preuves vérifiables.
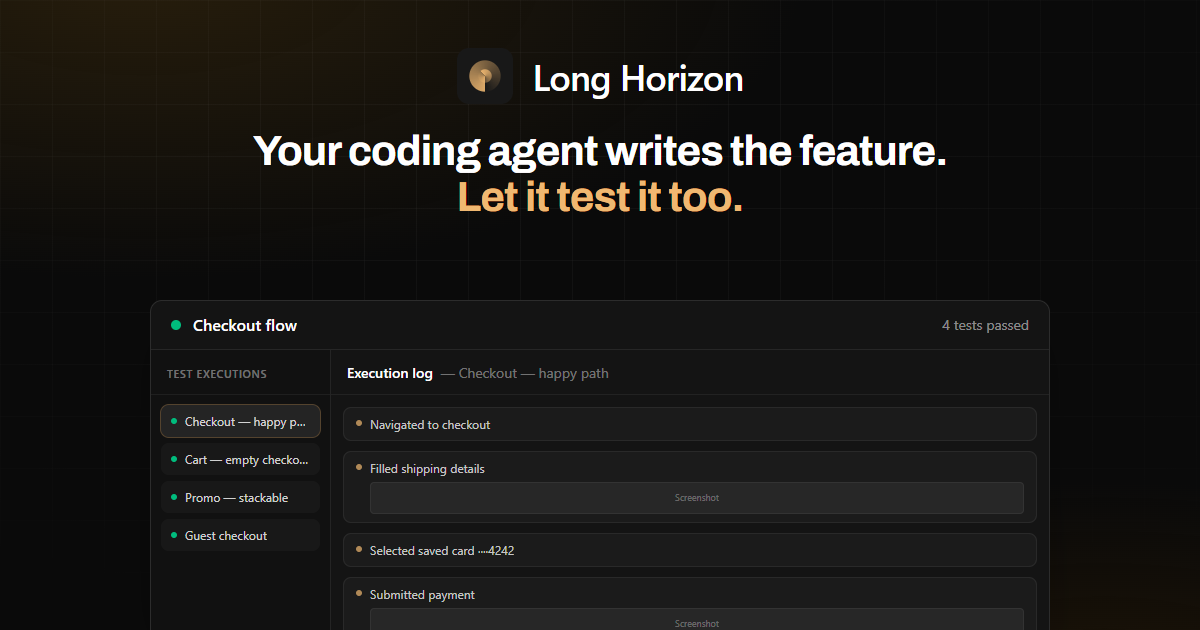
Au lieu de seulement générer des tests, Long Horizon les exécute dans une vraie session navigateur et produit des rapports d’exécution partageables. Ces rapports incluent des logs d’exécution et des pièces jointes telles que des captures d’écran et des détails réseau, facilitant le débogage et les exécutions reproductibles.
Fonctionnalités clés
- Planification de tests pilotée par agent à partir du contexte de votre fonctionnalité et de votre dépôt
- L’agent rédige ce qu’il faut tester (chemins principaux, cas limites et scénarios d’échec) en se basant sur les entrées de la fonctionnalité et du dépôt.
- Exécution automatisée de tests basés sur navigateur
- Les tests s’exécutent dans un vrai navigateur, de sorte que les assertions reflètent le vrai comportement UI et les interactions réseau.
- Rapports d’exécution partageables avec logs et pièces jointes
- Les sorties sont conçues pour révision, incluant logs d’exécution et artefacts comme des captures d’écran.
- Exécutions fiables et reproductibles
- Le workflow met l’accent sur des sessions répétables pour revisiter et comprendre les échecs.
- Rédaction de tests intégrée dans les fichiers de tests du projet
- L’agent écrit les tests dans votre projet (exemples montrés incluent plusieurs fichiers de tests liés au checkout).
- Workflow de débogage pour les tests en échec
- En cas d’échec, l’agent identifie ce qui a cassé et propose des changements ; les développeurs peuvent examiner les logs et assister sur les scénarios complexes.
- Mode lent / mode étape pour inspection manuelle
- Les exécutions peuvent se faire en modes aidant les développeurs à observer le comportement lors d’échecs ou de flux complexes.
- Retours UI pour guider les changements de l’agent
- Les utilisateurs peuvent laisser des retours directement dans l’UI avec commentaires au niveau élément ; l’agent intègre le contexte comme captures d’écran et HTML d’élément.
Comment utiliser Long Horizon
- Partez d’une fonctionnalité en développement et fournissez le contexte repo pertinent à l’agent.
- Demandez à l’agent de rédiger un plan de tests pour la fonctionnalité (incluant chemins heureux, cas limites et scénarios d’erreur).
- Faites rédiger les tests dans votre projet par l’agent, puis exécutez-les dans un vrai navigateur.
- Examinez le rapport d’exécution généré, incluant logs et captures d’écran jointes.
- Si un test échoue, utilisez le workflow de débogage — examinez la sortie d’échec et laissez l’agent proposer des correctifs, puis relancez.
Dans les exemples fournis, le workflow inclut la planification de scénarios pour checkout (ex. « checkout — chemin heureux », « panier — checkout vide bloqué », et « paiement — refus et retry »), leur exécution dans une session navigateur, et la validation d’assertions comme IDs de confirmation et visibilité DOM.
Cas d’usage
- Régression chemin heureux checkout pour utilisateurs connectés
- Exécutez un scénario planifié par agent où un utilisateur connecté finalise un achat et vérifiez que la route de confirmation affiche les identifiants attendus (ex. ID commande et email dans le DOM).
- Empêcher le checkout quand le panier est vide
- Validez que l’appel à l’action checkout reste désactivé quand le panier est vide et que les appels réseau liés au paiement ne sont pas déclenchés.
- Gérer les flux de refus carte et retry
- Simulez une carte refusée, confirmez qu’une erreur inline s’affiche, et vérifiez que les utilisateurs peuvent changer le moyen de paiement et finaliser la commande.
- Tester checkout invité et flux paiement email seulement
- Vérifiez un scénario checkout où un utilisateur avance sans compte et assurez que les vérifications pré-paiement (telles que contrôles fraude mentionnés dans la source) ont lieu avant paiement.
- Déboguer et corriger échecs dans flux complexes
- Quand un test navigateur échoue à cause d’une condition bloquante inattendue (ex. verrouillage inventaire sur checkout), utilisez les logs pour identifier le problème, mettez à jour mocks/stubs (comme disponibilité stock), et relancez.
FAQ
Long Horizon génère-t-il des tests ou les exécute-t-il seulement ?
Les deux. L’agent élabore un plan de test, rédige les tests dans le projet, puis les exécute dans un vrai navigateur.
Quel type de sortie produit Long Horizon après un test ?
Les rapports d’exécution sont partageables et incluent des logs complets d’exécution et des pièces jointes comme des captures d’écran, avec des détails supplémentaires comme les informations réseau.
Les développeurs peuvent-ils examiner les échecs et parcourir les scénarios étape par étape ?
Oui. Le workflow inclut l’examen des logs d’exécution par les développeurs et des options comme le mode lent et le mode étape pour une inspection manuelle.
Comment fonctionne le débogage de l’agent ?
Lors d’un échec de test, l’agent identifie ce qui a cassé et suggère des correctifs ; les développeurs peuvent aussi assister, par exemple en ajustant les mocks (comme l’inventaire) et en relançant le même test.
Comment les membres de l’équipe peuvent-ils guider l’agent pendant les correctifs ?
La source décrit une interface de feedback UI où les utilisateurs peuvent laisser des commentaires sur les éléments UI. L’agent utilise la capture d’écran, les commentaires et le HTML de l’élément.
Alternatives
- Frameworks conventionnels de tests end-to-end frontend
- Les outils de la catégorie E2E peuvent exécuter des tests navigateur, mais ils nécessitent généralement plus de planification et de rédaction manuelles des tests plutôt qu’une planification, rédaction et exécution pilotées par agent.
- Suites de tests QA scriptés avec triage manuel
- Les équipes peuvent écrire et exécuter des tests scriptés puis déboguer via les logs ; la différence est que Long Horizon met l’accent sur un workflow assisté par agent pour la planification, la rédaction et le débogage.
- Outils de workflow agentic générant des tests sans exécution en vrai navigateur
- Certaines approches se concentrent sur la génération de code de test ou de rapports ; le positionnement de Long Horizon porte spécifiquement sur l’exécution en vrai navigateur avec des rapports d’exécution examinables.
- Pipelines de tests navigateur basés sur CI
- Les setups d’intégration continue peuvent exécuter des tests navigateur de manière répétée ; Long Horizon se centre sur la création agentique de tests et des rapports d’exécution partageables pour soutenir la livraison de fonctionnalités et le débogage.
Alternatives
PromptLayer
PromptLayer aide les équipes à versionner et tester les prompts et agents IA avec des evals, du tracing et des jeux de régression, plus un éditeur visuel.
Evidently AI
Evidently AI est une plateforme d’évaluation IA et d’observabilité LLM pour tester et surveiller vos systèmes IA en production.
Crikket
Crikket : plateforme open-source de signalement de bugs. Capturez et partagez instantanément les détails techniques pour résoudre les problèmes plus vite.
Roo Code
Roo Code intègre une équipe d’ingénierie logicielle IA dans votre éditeur et via des agents cloud, avec Modes par rôle et workflows GitHub.
Logic
Logic est une plateforme d’agents pilotée par des spécifications : vos specs deviennent des API de production, avec tests, versioning, routage modèles et logs.
TestLaunch Pro
TestLaunch Pro est un marketplace payant de tests d’apps : trouvez des testeurs inscrits Google Play en closed testing, et les testeurs téléchargent, donnent du feedback puis encaissent via PayPal.