Long Horizon
Long Horizon è uno strumento di testing frontend agentico: pianifica, scrive ed esegue test reali in browser con report condivisibili, log e screenshot.
Cos'è Long Horizon?
Long Horizon è uno strumento di testing frontend agentico che permette a un agente di coding di pianificare, scrivere ed eseguire test basati su browser per un'applicazione web. Il suo scopo principale è aiutare i team a verificare le funzionalità in un browser reale e a evidenziare i problemi con evidenze esaminabili.
Invece di generare solo test, Long Horizon li esegue in una sessione browser reale e produce report di esecuzione condivisibili. Questi report includono log di esecuzione e allegati come screenshot e dettagli di rete, supportando il debugging e le esecuzioni di test riproducibili.
Caratteristiche Principali
- Pianificazione dei test agent-driven dal contesto della feature e del repository
- L'agente redige cosa testare (percorsi principali, casi limite e scenari di errore) in base agli input della feature e del repo.
- Esecuzione automatizzata dei test in browser
- I test vengono eseguiti in un browser reale, così le asserzioni riflettono il comportamento UI effettivo e le interazioni di rete.
- Report di esecuzione condivisibili con log e allegati
- Gli output sono progettati per la revisione, inclusi log di esecuzione e artefatti come screenshot.
- Esecuzioni affidabili e riproducibili
- Il workflow enfatizza sessioni ripetibili per poter rivedere e comprendere i fallimenti.
- Scrittura dei test nei file di test del progetto
- L'agente scrive i test nel tuo progetto (esempi mostrati includono file di test multipli relativi al checkout).
- Workflow di debugging per test falliti
- Quando un'esecuzione fallisce, l'agente identifica cosa si è rotto e propone cambiamenti; gli sviluppatori possono rivedere i log e assistere in scenari complessi.
- Modalità lenta / modalità step per ispezione manuale
- Le esecuzioni possono avvenire in modalità pensate per aiutare gli sviluppatori a osservare il comportamento durante fallimenti o flussi complessi.
- Feedback UI per guidare i cambiamenti dell'agente
- Gli utenti possono lasciare feedback direttamente sull'UI con commenti a livello di elemento; l'agente incorpora contesto come screenshot e HTML dell'elemento.
Come Usare Long Horizon
- Parti da una feature in sviluppo e fornisci all'agente il contesto repo rilevante.
- Chiedi all'agente di redigere un piano di test per la feature (includendo percorsi felici, casi limite e scenari di errore).
- Fai scrivere all'agente i test nel tuo progetto, poi esegui i test in un browser reale.
- Rivedi il report di esecuzione generato, inclusi log e screenshot allegati.
- Se un test fallisce, usa il workflow di debugging: rivedi l'output del fallimento, lascia che l'agente proponga fix, poi riesegui.
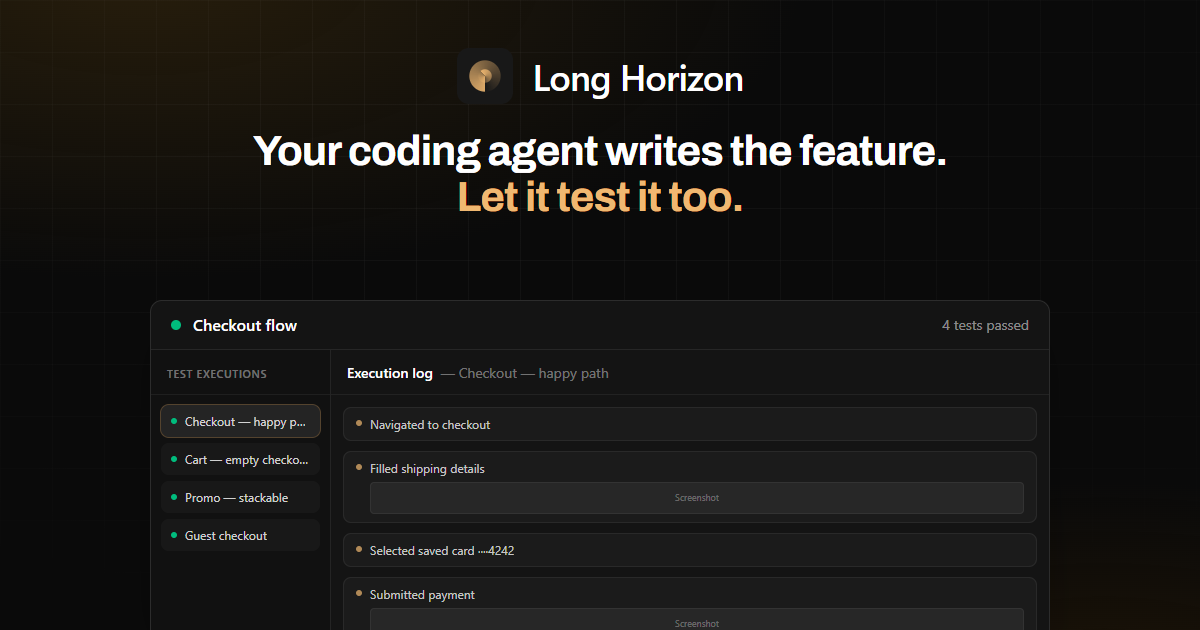
Negli esempi forniti, il workflow include la pianificazione di scenari per il checkout (es. “checkout — happy path,” “cart — empty checkout blocked,” e “payment — decline and retry”), l'esecuzione in una sessione browser e la validazione di asserzioni come ID di conferma e visibilità DOM.
Casi d'Uso
- Regressione happy-path checkout per utenti loggati
- Esegui uno scenario agent-planned in cui un utente loggato completa un acquisto e verifica che la rotta di conferma renderizzi identificatori attesi (es. order id e email nel DOM).
- Prevenire checkout con carrello vuoto
- Valida che la call-to-action del checkout rimanga disabilitata con carrello vuoto e che le chiamate di rete relative al pagamento non vengano attivate.
- Gestione flussi di declino carta e retry
- Simula una carta declinata, conferma che un errore inline venga mostrato e verifica che gli utenti possano cambiare metodo di pagamento e completare l'ordine con successo.
- Testing checkout guest e flussi pagamento solo email
- Controlla uno scenario checkout in cui un utente procede senza account e assicurati che i controlli pre-pagamento (come i fraud check menzionati nella sorgente) avvengano prima del pagamento.
- Debugging e fix di fallimenti in flussi complessi
- Quando un test browser fallisce per una condizione bloccante inaspettata (es. inventory gating checkout), usa i log per identificare il problema, aggiorna mock/stub (come disponibilità stock) e riesegui.
FAQ
Long Horizon genera test o li esegue soltanto?
Entrambi. L'agente elabora un piano di test, crea i test nel progetto e poi li esegue in un browser reale.
Che tipo di output produce Long Horizon dopo l'esecuzione di un test?
I report di esecuzione sono condivisibili e includono log completi di esecuzione e allegati come screenshot, con dettagli aggiuntivi come informazioni di rete.
Gli sviluppatori possono rivedere i fallimenti e procedere passo-passo negli scenari?
Sì. Il workflow include la revisione degli sviluppatori dei log di esecuzione e opzioni come modalità lenta e modalità step per l'ispezione manuale.
Come funziona il debug dell'agente?
Quando un test fallisce, l'agente identifica cosa si è rotto e suggerisce fix; gli sviluppatori possono assistere, ad esempio regolando i mock (come inventory) e rieseguendo lo stesso test.
Come possono i membri del team fornire indicazioni all'agente durante i fix?
La fonte descrive un'interfaccia UI per feedback dove gli utenti possono lasciare commenti su elementi UI. L'agente usa screenshot, commenti e HTML dell'elemento.
Alternative
- Framework convenzionali di testing end-to-end frontend
- Gli strumenti della categoria E2E possono eseguire test in browser, ma richiedono tipicamente più pianificazione e authoring manuale dei test anziché pianificazione, authoring ed esecuzione guidati da agente.
- Suite di test QA scriptate con triage manuale
- I team possono scrivere ed eseguire test scriptati e poi debuggarli usando i log; la differenza è che Long Horizon enfatizza un workflow assistito da agente per pianificazione, scrittura e debug.
- Strumenti di workflow agentici che generano test senza esecuzioni in browser reale
- Alcuni approcci si concentrano sulla generazione di codice di test o report; il posizionamento di Long Horizon è specificamente intorno all'esecuzione in browser reale con report di esecuzione rivedibili.
- Pipeline di testing browser basate su CI
- Le configurazioni di continuous integration possono eseguire test in browser ripetutamente; Long Horizon si centra sulla creazione agentica di test e report di esecuzione condivisibili per supportare la consegna di feature e il debug.
Alternative
PromptLayer
PromptLayer aiuta i team a versionare e testare prompt e agent AI con eval, tracing e regression sets. Editor visuale per collaborare.
Evidently AI
Evidently AI è una piattaforma per valutare e osservare LLM: test e monitoraggio dei sistemi AI in produzione, incluse valutazioni, RAG e metriche.
Crikket
Crikket: piattaforma open-source per segnalare bug. Cattura dettagli tecnici per risolvere problemi più velocemente. Alternativa a jam.dev.
Roo Code
Roo Code porta un team AI di ingegneria del software nel tuo editor e in agenti cloud: Modus per ruolo, controllo configurabile e workflow GitHub.
Logic
Logic è una piattaforma di agenti basata su specifiche: trasforma definizioni in API di produzione con test, versioning, model routing e log esecuzione.
TestLaunch Pro
TestLaunch Pro è un marketplace di test a pagamento: i developer trovano tester opt-in per la chiusura su Google Play e i tester scaricano, feedback e incassano via PayPal.