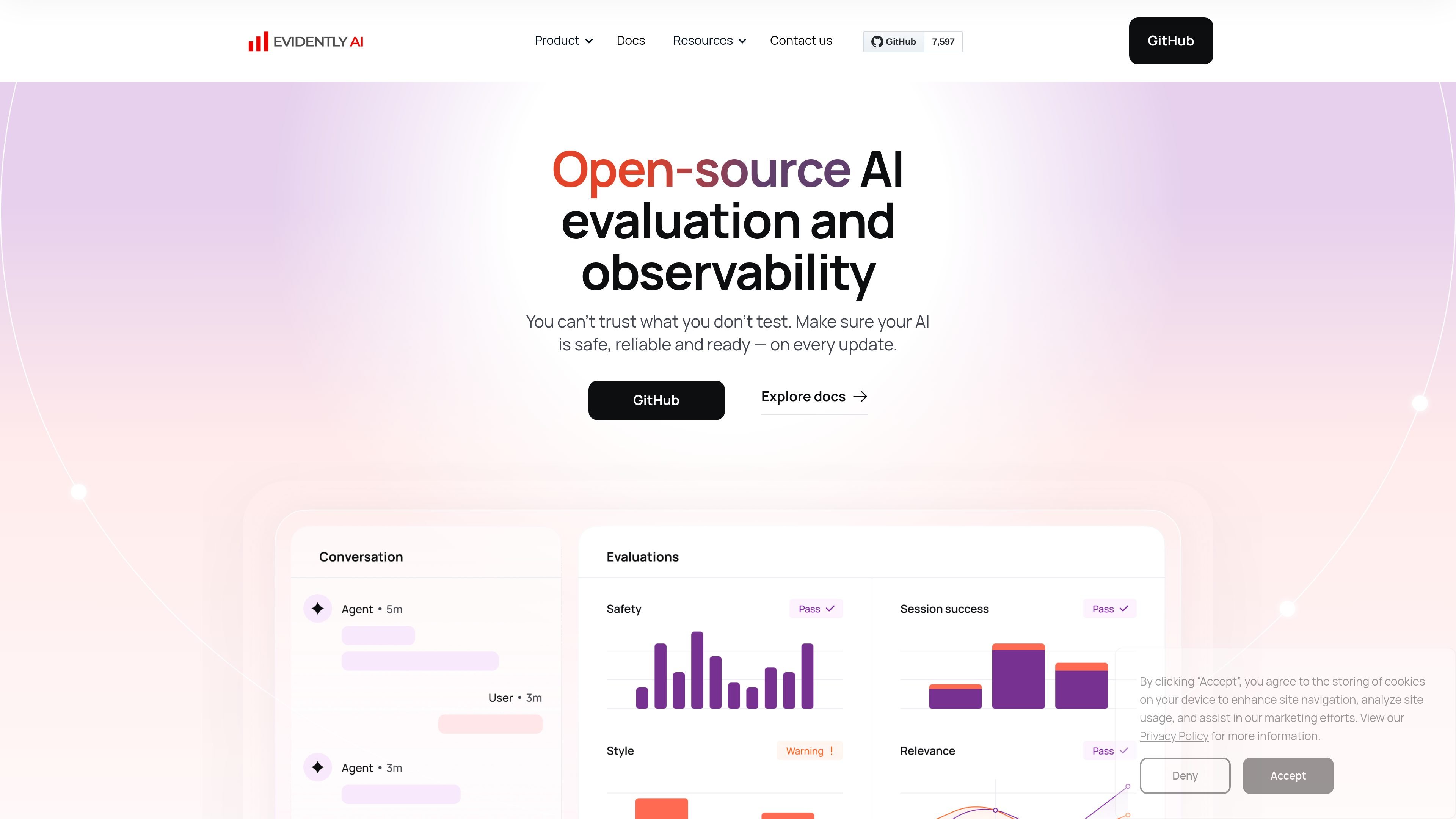
自動評価
出力の品質、安全性、信頼性を測る自動チェックを実行し、共有可能なビジュアルレポートで結果を確認できます。
Evidently AIは、LLM、RAGアプリケーション、AIエージェント、予測MLモデル向けのオープンソースAI評価・オブザーバビリティプラットフォームです。サイトでは、開発から本番までのAIシステムを評価、テスト、監視するための単一フレームワークとして紹介されています。
その主な目的は、更新後にAIが安全で、信頼性が高く、導入準備が整っているかをチームが確認できるようにすることです。製品は、自動評価、合成データ生成、継続的監視を組み合わせており、ビジュアルレポート、ダッシュボード、組み込みおよびカスタムメトリクスのライブラリを備えています。
出力の品質、安全性、信頼性を測る自動チェックを実行し、共有可能なビジュアルレポートで結果を確認できます。
本番前または本番中のプロンプトやワークフローをテストするために、現実的な入力、エッジケース、敵対的な入力を生成できます。
ライブダッシュボードで評価結果と品質チェックを時系列で追跡し、ドリフト、回帰、新たなリスクを可視化できます。
100以上の組み込みメトリクスのライブラリを使用するか、ルール、分類器、LLMベースの評価を組み合わせてカスタム品質システムを構築できます。
ガイドラインへの準拠、幻覚と事実性、PII検出、検索品質、文脈の関連性、感情、毒性、トーン、トリガーワードを評価できます。
任意のプロンプト、モデル、ルールを使ってカスタム評価を作成でき、チームごとに異なるAI製品へフレームワークを適応できます。
品質、安全性、事実性をカバーするテンプレートとメトリクスを使って、チャットボット、コパイロット、その他のLLM搭載製品を評価します。
RAGシステムの検索品質と文脈の関連性を測定し、グラウンディングの問題や回答品質の課題を特定するのに役立つチェックを含みます。
本番モデルに継続的監視を実行し、デプロイ後のドリフト、回帰、データ品質の問題を検知します。
プロンプト処理、安全境界、脱獄耐性を厳しく検証する必要がある場合に、エッジケースや敵対的なテスト入力を生成します。
固定的なダッシュボード専用製品ではなく、カスタムのテスト、メトリクス、レポートを求めるチーム向けに、社内評価ワークフローを構築します。
Evidently AIは、LLM、RAGアプリケーション、AIエージェント、予測MLモデルを単一のオープンソースフレームワークで評価・監視するためのものとして位置づけられています。サイトでは、AIオブザーバビリティとMLOpsを学ぶチーム向けのガイドやコースも紹介しています。
ホームページでは、自動評価、合成データ生成、継続的監視が説明されています。また、100以上の組み込みメトリクスのライブラリと、任意のプロンプト、モデル、ルールを使ったカスタム評価のサポートにも触れています。
ソース資料では、Apache 2.0のオープンソース提供であることが示されており、価格は掲載されていません。料金ページは製品、リソース、問い合わせ方法を案内していますが、収集したテキストには具体的なプラン詳細は含まれていません。
はい。サイトでは、チャットボット、RAGアプリケーション、AIエージェント、コパイロットなどのLLM搭載システムに加え、予測MLシステムの評価も明記されています。
収集したページには、対応する統合マトリクスは記載されていません。ある推薦文でMLflowに言及がありますが、対象範囲のサイトテキストには、統合ページやAPI一覧の完全な情報はありません。
Benchspanは、AIエージェントの検出、プロンプトインジェクションとデータ流出のリアルタイム防御、リリース前のレッドチーミングを備えたAI agent security platformです。PythonとTypeScript SDKsに対応。
ByteAskは、C/C++向けのターミナル起点AIコーディングエージェント。リポジトリを編集し、コンパイラやデバッガ、サニタイザ、テストで変更を検証してから差分を表示。無料枠あり。
PromptScoutは、ChatGPT、Gemini、Google AI Overviews、Perplexityで自社や競合がどう言及されるかを追跡し、ソース分析とサイト監査を組み合わせて、次に直すべき内容・訴求・サイト対応を判断できます。
Sleek Analyticsは、Cookieバナー不要で導入も簡単なプライバシー重視のWeb解析ツール。リアルタイム訪問者追跡、Core Web Vitals、収益アトリビューションに対応。
MacSpoofはmacOSのMACアドレス変更ツール。Wi‑FiのMACを変更/ランダム化して再接続し、公衆Wi‑Fiでの端末記録を抑えるのに役立ちます。
Manta AIは、URLからアプリの挙動を把握し、回帰を検出し、スクリプトやセレクタ管理なしでテストを生成できる自律型Webアプリテストツールです。