SQLite-compatible, region-expandable database
Create a SQLite-compatible database on bunny.net’s network and start in a single region, then add more regions later without changing your application design.
Bunny Database is a SQLite-compatible DBaaS from bunny.net for read-heavy applications that need low-latency access across regions. It supports libSQL SDKs, HTTP access, and usage-based pricing with a free public preview.
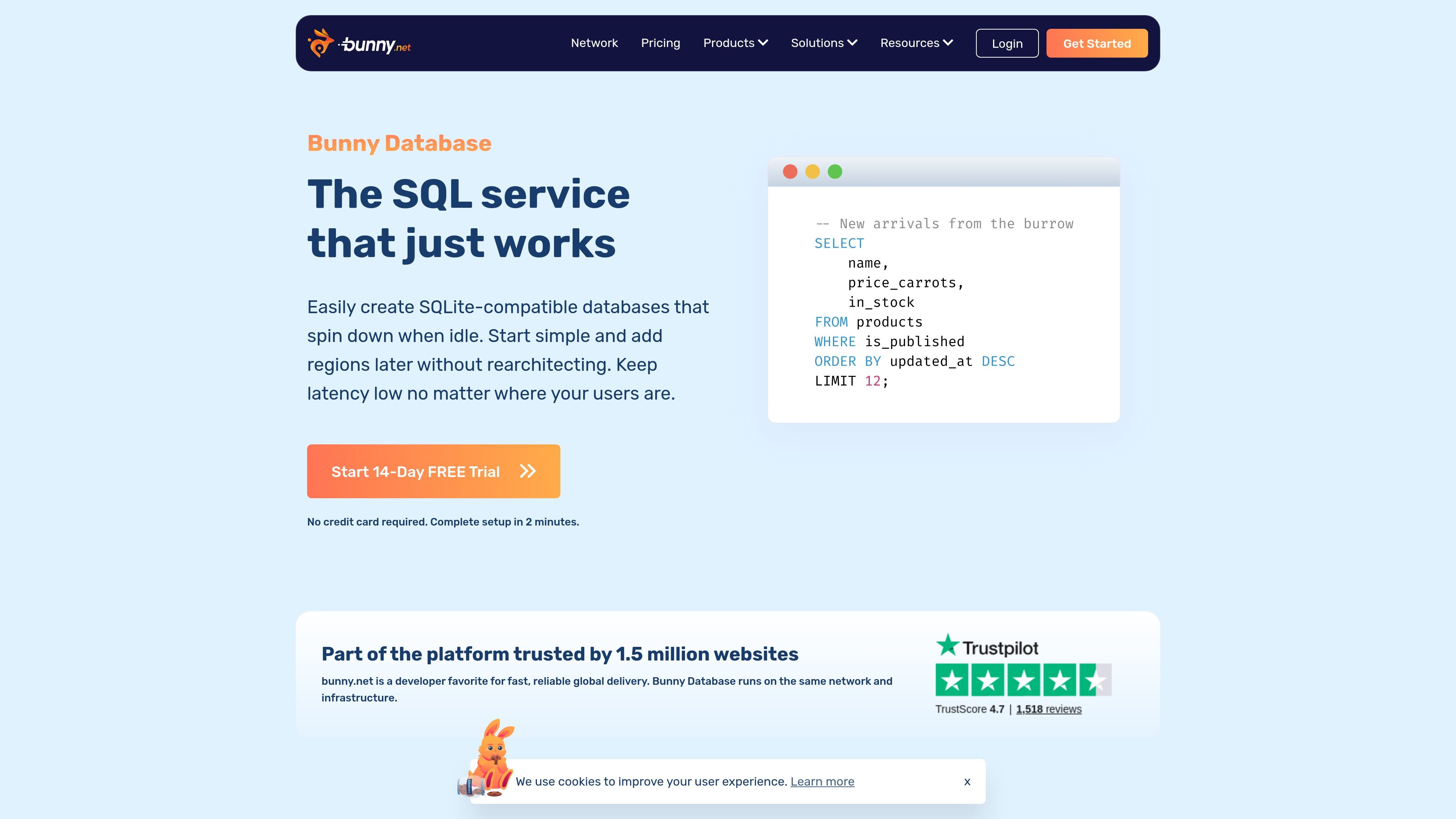
Bunny Database is a SQLite-compatible database service from bunny.net. It is designed to spin down when idle, start in one region, and expand to more regions later without forcing a rearchitecture.
The product is positioned as a simple DBaaS for read-heavy applications that need low latency across geographies. It runs on bunny.net’s global network and exposes familiar libSQL SDKs for TS/JS, Go, Rust, and .NET, with HTTP access also available when needed.
Create a SQLite-compatible database on bunny.net’s network and start in a single region, then add more regions later without changing your application design.
Choose from 41 regions and serve reads closer to users to keep round-trip times low across distributed audiences.
Use official libSQL SDKs for TS/JS, Go, Rust, and .NET, or connect over HTTP when you need a more general interface.
Inspect tables, run SQL, and check data directly from the product experience, instead of jumping between separate admin tools.
Track latency, traffic, and storage as the database scales so you can watch how usage changes over time.
When the database is idle, the source says it only incurs storage costs, with read replicas adding storage costs only when serving traffic.
Store structured catalog data, location lists, or directory content that users browse more often than they update.
Keep tags, categories, and other lookup data available for filtering and sorting without heavy database overhead.
Serve account settings, preferences, and lightweight per-user state for applications that need simple relational storage.
Centralize low-churn settings for an application, tenant, or environment and expand regions later as traffic spreads.
Support teams that want to inspect SQL and track latency, traffic, and storage without moving to a separate operational stack.
Bunny Database is a SQLite-compatible database service on bunny.net’s global network. The source says it is built for low-latency access, can be started in one region, and expanded to more regions later without rearchitecting.
The source says you can connect with familiar libSQL SDKs for TS/JS, Go, Rust, and .NET, or use HTTP when needed. Access tokens can be used as environment variables, which fits typical app and script setups.
It is positioned for read-heavy workloads such as catalogs and directories, metadata and filtering, user profiles, and app configuration. The page explicitly says it works best for read-heavy use cases.
The pricing section says usage is charged continuously and invoiced monthly, and that reads, writes, and storage are billed separately. It also says Bunny Database is free while in public preview.
The page mentions 41 available regions, read replicas, and metrics for latency, traffic, and storage. It also says Bunny Database runs standalone and can be paired with Edge Scripting or Magic Containers.
NodeDB is a universal database engine that combines relational, vector, graph, document, columnar, and scientific array data in one Rust binary. It claims PostgreSQL client compatibility and shows a GraphRAG-style workflow that fuses vector search with graph expansion in a single query.
Metabase Data Studio is a semantic layer and analytics workbench for cleaning, defining, and publishing reusable data inside Metabase. It helps teams keep metrics, dependencies, and curated datasets consistent for self-service and embedded analytics.
NewsCatcher Platform is a web app for generating custom news datasets and monitoring stories from web search results. It helps users build structured, citation-backed records for analysis and AI workflows.
Happenstance is an AI-powered network search tool for finding people, mutual connections, and warm introductions across connected accounts. It supports individual use, shared team groups, and developer workflows through API, MCP, Slack, and other integrations.
Veerexa’s YouTube Comments Exporter extracts comments from a YouTube video in the browser and lets you analyze or export them as CSV or JSON. It is aimed at users who need a fast way to review comment activity without server-side processing.
AnySearch provides AI search infrastructure for agents, with structured results delivered through MCP, Skill, or a REST API. It helps developers build search into automated workflows that need current, machine-readable information.