Multiple generation modes
Generate speech in Single Speaker, Multi Speaker, or Instant Speech mode depending on whether you are working with monologues, dialogue, or quick conversions.
FlowSpeech is a context-aware text-to-speech studio that turns scripts and uploaded files into human-like audio. It offers multiple generation modes, pause and emotion control, and a free plan alongside paid tiers.
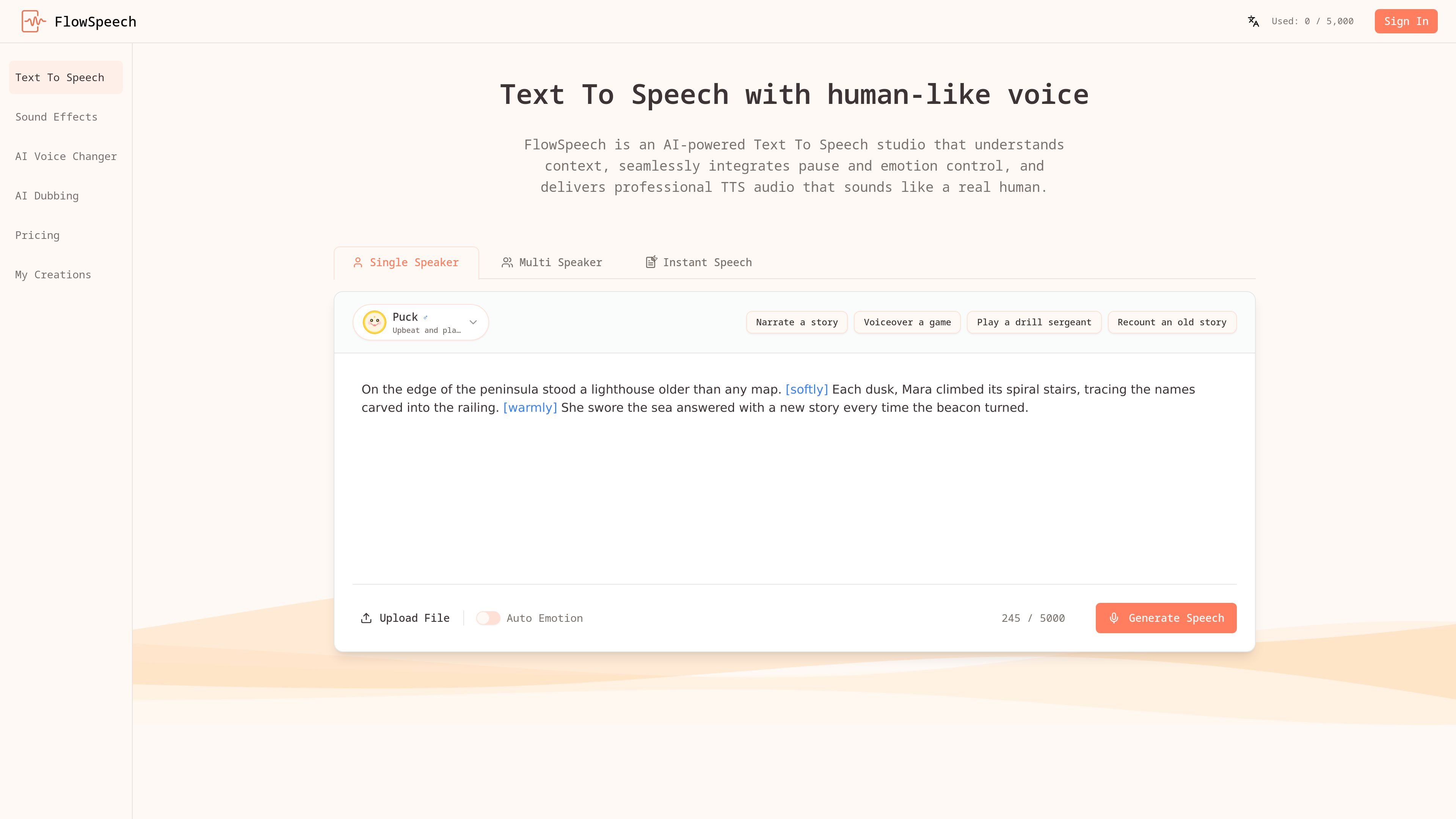
FlowSpeech is an AI text-to-speech studio that converts scripts and uploaded documents into lifelike audio. It is built around context-aware speech generation, so the output can reflect sentiment, timing, and nuance instead of sounding mechanically read.
The product centers on three workflows: Single Speaker for monologues, Multi Speaker for conversations, and Instant Speech for quick generation. Users can also add bracketed instructions for pauses, emotion, and accent changes, making the tool useful when the delivery of the narration matters as much as the words themselves.
The site positions FlowSpeech for creators, marketers, educators, and anyone producing long-form or multi-voice audio. It supports direct text entry as well as common document and image formats, and the homepage also highlights audiobook narration, video voiceovers, and podcast-style dialogue as typical applications.
Generate speech in Single Speaker, Multi Speaker, or Instant Speech mode depending on whether you are working with monologues, dialogue, or quick conversions.
Let the system analyze the script’s tone and timing so the output reflects context, sentiment, and nuance instead of reading each line flatly.
Insert tags such as [whisper], [shout], [strong British accent], or [⌛1.0s] to guide emotion, accent, and pauses directly in the script.
Upload PDF, DOC, DOCX, PPT, PPTX, TXT, RTF, EPUB, or image files and have FlowSpeech extract the text for conversion.
Choose from 30 voices across news, marketing, narrative, and character styles, with support for 70+ languages.
Render long-form projects up to 200k characters at once, which helps when working with chapters, scripts, or extended narration.
Turn books, articles, and study material into long-form narration where pacing and emotional delivery need to stay consistent across extended audio.
Create spoken tracks for clips, explainers, and product demos, with voice and pause control that lets the audio match the edit.
Build dialogue, podcast segments, and multi-character scenes by splitting scripts across speakers and assigning suitable voices automatically.
Convert classroom materials into spoken audio for lessons and presentations, especially when you want to ingest documents rather than retype scripts.
Use the tool for fast script-to-audio generation when you need a polished result without moving into a DAW for manual timing edits.
FlowSpeech is a text-to-speech studio that turns scripts and uploaded files into human-like audio with context-aware delivery, emotion control, and pause tags.
The site says FlowSpeech supports Single Speaker, Multi Speaker, and Instant Speech modes, plus manual emotion, accent, and pause tags for finer control over delivery.
Yes. The pricing page includes a Free plan alongside paid Basic, Pro, and Scale plans, so there is a no-cost entry point for trying the product.
The homepage FAQ asks about commercial use, but the public page text provided does not spell out the license terms, so you should confirm usage rights before publishing generated audio commercially.
The homepage FAQ includes a question about data safety, but the collected text does not provide the answer, so privacy and retention details are not confirmed here.
Gemini 3.1 Flash TTS is Google’s preview text-to-speech model for generating expressive AI speech with fine-grained control over style and delivery. It is available across the Gemini API, Google AI Studio, Vertex AI, and Google Vids.
蓝藻AI是一款在线AI配音与语音合成产品,可将文字转成语音,并支持自助声音克隆。页面信息显示它面向短视频、有声书等需要配音的内容场景。
Ondoku 是一款基于浏览器的文字转语音软件,可将文本转换为可下载的 .mp3 语音,并提供免费额度与付费方案。它支持多语言朗读、图片朗读以及按规则商用。
Typecast is an online AI voice generator that turns text into life-like speech with emotional delivery and a selection of hyper-realistic voices. It is a browser-based tool for creating spoken audio from written content.
Noiz AI is an AI text-to-speech, voice cloning, and voice design tool for creating lifelike speech from text. It also lets users shape voice delivery, including emotion, within the same workflow.
魔音工坊 (Moying Gongfang) é uma plataforma inteligente de texto para fala (TTS) online que converte texto escrito em narrações de voz de alta qualidade usando vozes humanas realistas com vários sotaques.