Long Horizon
Long Horizon é uma ferramenta de testes de frontend agentic que planeja, escreve e executa testes reais no navegador, gerando relatórios compartilháveis.
O que é Long Horizon?
Long Horizon é uma ferramenta de testes de frontend agentic que permite que um agente de codificação planeje, crie e execute testes baseados em navegador para uma aplicação web. Seu propósito principal é ajudar equipes a verificar recursos em um navegador real e expor problemas com evidências revisáveis.
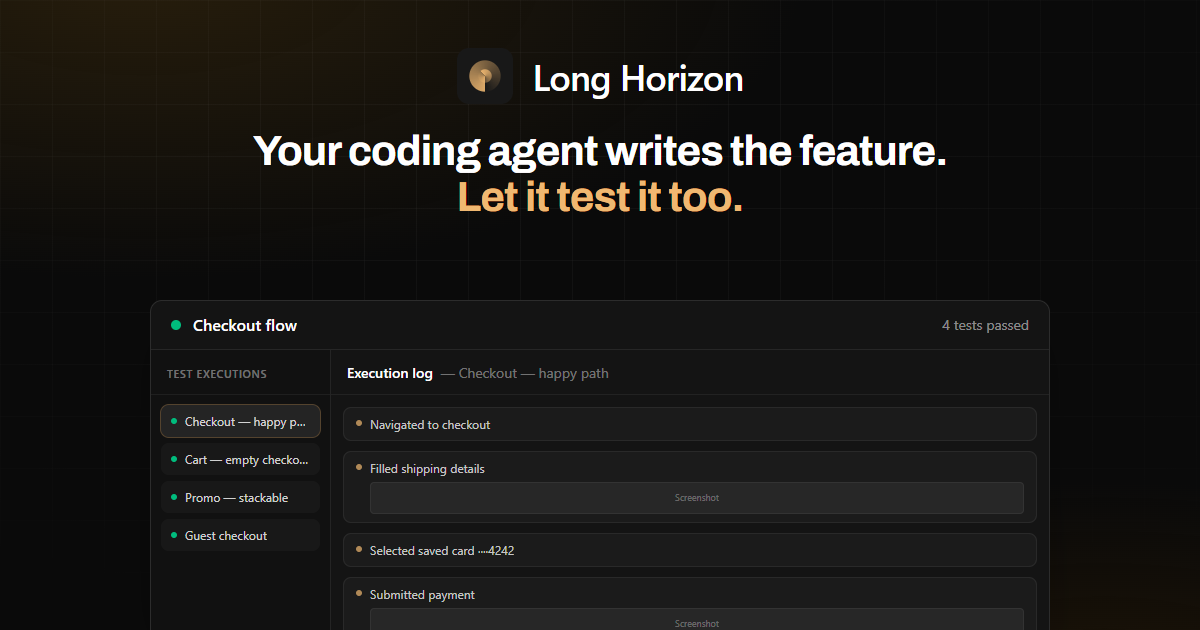
Em vez de apenas gerar testes, o Long Horizon os executa em uma sessão real de navegador e produz relatórios de execução compartilháveis. Esses relatórios incluem logs de execução e anexos como capturas de tela e detalhes de rede, suportando depuração e execuções de testes reproduzíveis.
Principais Recursos
- Planejamento de testes impulsionado por agente a partir do contexto do seu recurso e repositório
- O agente cria o que testar (caminhos principais, casos de borda e cenários de falha) com base nos inputs do recurso e repositório.
- Execução automatizada de testes baseados em navegador
- Os testes são executados em um navegador real, então as asserções refletem o comportamento real da UI e interações de rede.
- Relatórios de execução compartilháveis com logs e anexos
- As saídas são projetadas para revisão, incluindo logs de execução e artefatos como capturas de tela.
- Execuções confiáveis e reproduzíveis
- O fluxo de trabalho enfatiza sessões repetíveis para que falhas possam ser revisadas e compreendidas.
- Criação de testes escrita nos arquivos de teste do projeto
- O agente escreve testes no seu projeto (exemplos mostrados incluem múltiplos arquivos de teste relacionados ao checkout).
- Fluxo de depuração para testes com falha
- Quando uma execução falha, o agente pode identificar o que quebrou e propor mudanças; desenvolvedores podem revisar logs e ajudar em cenários complicados.
- Modo lento / modo passo para inspeção manual
- Execuções podem ser realizadas em modos para ajudar desenvolvedores a observar o comportamento durante falhas ou fluxos complexos.
- Feedback de UI para guiar mudanças do agente
- Usuários podem deixar feedback diretamente na UI com comentários em nível de elemento; o agente incorpora contexto como capturas de tela e HTML do elemento.
Como Usar Long Horizon
- Comece com um recurso em desenvolvimento e forneça o contexto relevante do repositório ao agente.
- Peça ao agente para criar um plano de testes para o recurso (incluindo caminhos felizes, casos de borda e cenários de erro).
- Tenha o agente escrever os testes no seu projeto, depois execute os testes em um navegador real.
- Revise o relatório de execução gerado, incluindo logs e capturas de tela anexadas.
- Se um teste falhar, use o fluxo de depuração — revise a saída da falha e deixe o agente propor correções, depois reexecute.
Nos exemplos fornecidos, o fluxo de trabalho inclui planejamento de cenários para checkout (ex.: “checkout — happy path”, “cart — empty checkout blocked” e “payment — decline and retry”), execução deles em uma sessão de navegador e validação de asserções como IDs de confirmação e visibilidade do DOM.
Casos de Uso
- Regressão de caminho feliz de checkout para usuários logados
- Execute um cenário planejado por agente onde um usuário logado completa uma compra e verifique que a rota de confirmação renderiza identificadores esperados (ex.: ID do pedido e email no DOM).
- Prevenção de checkout quando o carrinho está vazio
- Valide que o call-to-action de checkout permaneça desabilitado quando o carrinho está vazio e que chamadas de rede relacionadas a pagamento não sejam acionadas.
- Tratamento de fluxos de declínio de cartão e retry
- Simule um cartão declinado, confirme que um erro inline é exibido e verifique que usuários podem alterar o método de pagamento e completar o pedido com sucesso.
- Teste de checkout como convidado e fluxos de pagamento só com email
- Verifique um cenário de checkout onde um usuário prossegue sem conta e garanta que verificações pré-pagamento (como checagens de fraude mencionadas na fonte) ocorram antes do pagamento.
- Depuração e correção de falhas em fluxos complexos
- Quando um teste de navegador falha devido a uma condição de bloqueio inesperada (ex.: gating de inventário no checkout), use logs para identificar o problema, atualize mocks/stubs (como disponibilidade de estoque) e reexecute.
FAQ
O Long Horizon gera testes ou apenas os executa?
Ambos. O agente cria um plano de teste, escreve os testes no projeto e depois executa esses testes em um navegador real.
Que tipo de saída o Long Horizon produz após a execução de um teste?
Relatórios de execução compartilháveis que incluem logs completos de execução e anexos como capturas de tela, com detalhes adicionais como informações de rede.
Desenvolvedores podem revisar falhas e avançar passo a passo nos cenários?
Sim. O fluxo inclui revisão pelos desenvolvedores dos logs de execução e opções como modo lento e modo passo para inspeção manual.
Como funciona a depuração do agente?
Quando um teste falha, o agente identifica o que quebrou e sugere correções; desenvolvedores também podem ajudar, por exemplo, ajustando mocks (como de inventário) e reexecutando o mesmo teste.
Como os membros da equipe podem fornecer orientação ao agente durante as correções?
Há uma interface de feedback na UI onde usuários deixam comentários em elementos da UI. O agente usa a captura de tela, comentários e HTML do elemento.
Alternativas
- Frameworks convencionais de testes end-to-end de frontend
- Ferramentas da categoria E2E podem executar testes no navegador, mas geralmente exigem mais planejamento e escrita manual de testes em vez de planejamento, escrita e execução impulsionados por agente.
- Conjuntos de testes QA scriptados com triagem manual
- Equipes podem escrever e executar testes scriptados e depurar usando logs; a diferença é que o Long Horizon enfatiza um fluxo assistido por agente para planejamento, escrita e depuração.
- Ferramentas de fluxo agentic que geram testes sem execuções em navegador real
- Algumas abordagens focam em gerar código de teste ou relatórios; o posicionamento do Long Horizon é especificamente em torno de execução em navegador real com relatórios de execução revisáveis.
- Pipelines de testes no navegador baseados em CI
- Configurações de integração contínua podem executar testes no navegador repetidamente; o Long Horizon centra-se na criação agentic de testes e relatórios de execução compartilháveis para apoiar a entrega de funcionalidades e depuração.
Alternativas
PromptLayer
O PromptLayer ajuda equipes a versionar e testar prompts e agentes de IA com evals, tracing e conjuntos de regressão, além de editor visual para colaboração.
Evidently AI
Evidently AI é uma plataforma de avaliação de IA e observabilidade LLM para testar e monitorar sistemas de IA em produção.
Crikket
Crikket: plataforma open-source para relatar bugs. Capture e compartilhe detalhes técnicos para resolver problemas mais rápido. Alternativa a jam.dev.
Roo Code
Roo Code oferece um time de engenharia de software com IA no editor e via agentes em nuvem, com Modes por função e fluxos ligados ao GitHub.
Logic
Logic é uma plataforma de agentes orientada por especificações que transforma descrições em APIs de produção, com testes, versionamento e logs.
TestLaunch Pro
TestLaunch Pro é um marketplace pago de testes de apps: encontre testers opt-in para o Google Play, faça download, envie feedback e receba via PayPal.