Nirixa
Nirixa é uma ferramenta de observabilidade de IA e inteligência de custos que rastreia tokens, custo, latência e risco de alucinação por chamada.
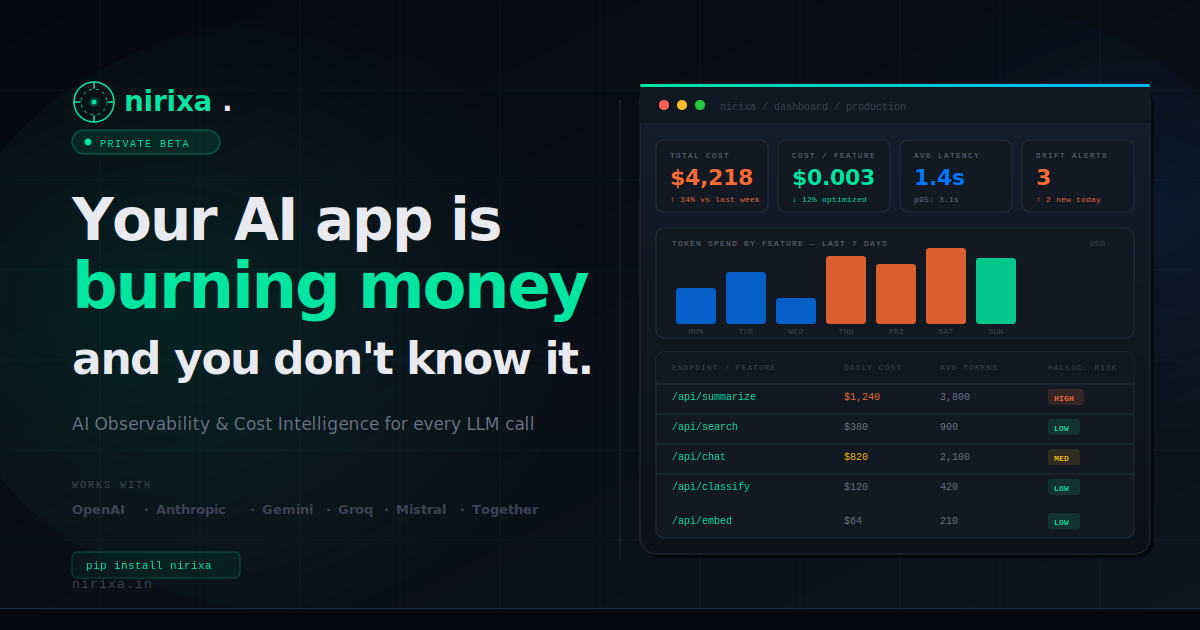
O que é Nirixa?
Nirixa é uma solução de observabilidade de IA e inteligência de custos para equipes que constroem com grandes modelos de linguagem. Ela foi projetada para ajudar você a rastrear e entender os tokens, custo e latência de cada chamada de LLM, além de avaliar o risco de alucinação.
O propósito principal é dar aos desenvolvedores e operadores visibilidade sobre o comportamento do uso do modelo em produção, para que possam monitorar o desempenho e gerenciar os gastos em provedores de LLM.
Principais Recursos
- Rastreamento de tokens e custo por chamada de LLM: registra o uso de tokens e o custo associado para tornar os gastos do modelo atribuíveis a requisições específicas.
- Visibilidade de latência: captura informações de tempo para cada chamada, permitindo identificar lentidões e padrões de desempenho.
- Detecção de risco de alucinação: fornece uma forma de estimar a probabilidade de alucinação junto com outras métricas de chamada.
- SDK drop-in para múltiplos provedores de LLM: suporta integração com OpenAI, Anthropic, Gemini e outros provedores por meio de uma abordagem de SDK.
Como Usar o Nirixa
- Comece com o Nirixa e adicione o SDK drop-in fornecido à sua aplicação onde você faz requisições de LLM.
- Configure-o para que as requisições sejam capturadas automaticamente para os provedores suportados.
- Use a visibilidade no nível de chamada do Nirixa para revisar tokens, custo, latência e risco de alucinação no seu tráfego de LLM.
- Itere em prompts ou lógica da aplicação com base nas métricas de chamada e sinais de risco observados.
Casos de Uso
- Monitore tráfego de LLM em produção: rastreie tokens, custo e latência por requisição para entender o comportamento do sistema em uso real.
- Controle e investigue gastos: identifique quais fluxos de trabalho ou endpoints estão gerando o maior uso de tokens e custo.
- Diagnostique regressões de desempenho: compare padrões de latência entre requisições para detectar chamadas de modelo lentas ou entradas problemáticas.
- Reduza saídas não confiáveis: use estimativas de risco de alucinação para encontrar casos em que respostas geradas podem ser menos confiáveis, e ajuste prompts ou guardrails conforme necessário.
- Valide comportamento multi-provedor: ao usar OpenAI, Anthropic, Gemini (e mais), compare métricas no nível de chamada entre provedores para entender diferenças em padrões de uso.
Perguntas Frequentes
O que o Nirixa mede para cada requisição de LLM?
O Nirixa foca no uso de tokens, custo, latência e um sinal de risco de alucinação para chamadas de LLM.
Quais provedores de modelos o Nirixa suporta?
A página afirma que o Nirixa fornece um SDK drop-in para OpenAI, Anthropic, Gemini e mais.
Preciso reescrever meu código de LLM para usar o Nirixa?
O site descreve o Nirixa como um “SDK drop-in”, o que implica que você pode integrá-lo sem reescritas significativas, mas os passos exatos dependem do seu cliente de LLM atual e de como você o chama.
O Nirixa é só para observabilidade ou também para gerenciamento de custos?
Ele é posicionado como observabilidade de IA e inteligência de custos, combinando rastreamento de custos com sinais relacionados a desempenho e qualidade.
Alternativas
- Plataformas gerais de monitoramento/telemetria (APM/logging): adequadas para rastrear métricas no nível de serviço, mas geralmente não fornecem detalhes específicos de chamadas de LLM como tokens, custo e risco de alucinação prontos para uso.
- Painéis de uso de LLM integrados a frameworks de orquestração: podem oferecer visibilidade de tokens/custo dentro de um framework específico, mas podem não generalizar entre provedores ou oferecer a mesma perspectiva de risco de alucinação.
- Ferramentas de observabilidade de modelos focadas em logging de prompt/resposta: podem ajudar a debugar saídas e monitorar comportamento de geração, mas podem enfatizar rastreabilidade em vez de inteligência de custos ou métricas padronizadas no nível de chamada entre provedores.
Alternativas
BenchSpan
BenchSpan executa benchmarks de agentes de IA em paralelo, registra scores e falhas em um histórico organizado e facilita reprodutibilidade por commit.
PromptScout
PromptScout monitora menções à sua marca, recomendações de concorrentes e fontes citadas em respostas de IA no ChatGPT, Gemini, Google AI Overviews e Perplexity.
Sleek Analytics
Analítica leve e focada na privacidade com rastreamento em tempo real: veja de onde vêm os visitantes, o que acessam e por quanto tempo.
MacSpoof
MacSpoof é um alterador de MAC no macOS que permite trocar ou randomizar o endereço Wi‑Fi para reconectar e reduzir o registro da identidade.
ClawTick
ClawTick é uma plataforma de automação de agentes com IA e CLI para agendar tarefas via webhooks em cron, com monitoramento, alertas e logs.
OpenFlags
OpenFlags é um sistema de feature flags open source e self-hosted para progressive delivery, com avaliação local via SDKs e control plane.