PinchBench
Compare o desempenho do agente OpenClaw em 100+ LLMs com rankings de taxa de sucesso, usando verificações automatizadas e avaliação por LLM.
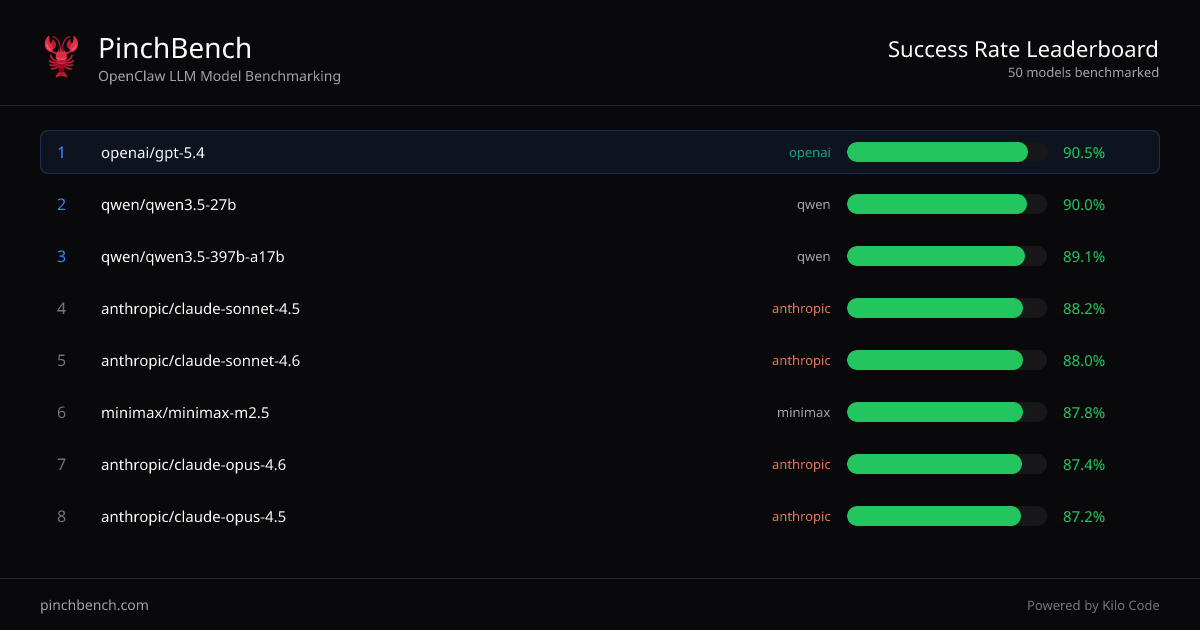
O que é o PinchBench?
O PinchBench é um site de benchmarking de modelos LLM OpenClaw que classifica modelos de IA por taxa de sucesso em tarefas de codificação padronizadas. Seu propósito principal é ajudar você a comparar vários LLMs usando a mesma configuração de testes baseada em agente, para que possa escolher um modelo com base em resultados mensuráveis em vez de suposições.
O site apresenta rankings de “Taxa de sucesso por modelo” e permite visualizar mais tarefas e detalhes de avaliação. Ele também indica que a avaliação e pontuação são automatizadas usando verificações automatizadas e um juiz LLM.
Principais Recursos
- Rankings de taxa de sucesso entre modelos: Exibe uma tabela ordenada de modelos com campos para “Best %,” “Avg %” e colunas de pontuação relacionadas para comparar o desempenho de forma consistente.
- Benchmarking de agente OpenClaw: Avalia modelos especificamente no contexto de um fluxo de trabalho de agente “OpenClaw”, refletindo como os modelos se saem em tarefas de codificação impulsionadas por agente.
- Avaliação automatizada com verificações e juiz LLM: As pontuações são derivadas de verificações automatizadas e um juiz LLM, fornecendo um método de avaliação repetível.
- Filtro de orçamento (máx $ por execução): Inclui um filtro de orçamento rotulado “Max $per run”, permitindo focar as comparações dentro de uma restrição de custo exibida pela interface.
- Materiais e critérios de teste transparentes: Nota que “All tasks and grading criteria are open source,” e fornece uma forma de visualizar tarefas.
Como Usar o PinchBench
- Navegue até o PinchBench e use a tabela de ranking de modelos para comparar modelos por taxa de sucesso.
- Opcionalmente, ajuste o filtro de orçamento usando o controle “Max $ per run” para restringir os resultados a modelos que se encaixem no seu limite de custo especificado.
- Use as visualizações de tarefas e detalhes de avaliação (incluindo critérios de avaliação abertos) para entender o que as pontuações medem antes de selecionar um modelo.
Casos de Uso
- Selecionar um LLM para um agente de codificação OpenClaw: Compare modelos candidatos por taxa de sucesso mensurável em tarefas de agente padronizadas, depois escolha a melhor opção para o seu caso de uso.
- Avaliar qualidade vs. desempenho médio: Use as colunas “Best %” e “Avg %” da tabela para diferenciar modelos que podem atingir picos altos versus aqueles com resultados mais consistentes.
- Comparação de modelos com consciência de custo: Aplique o filtro max $ per run para comparar modelos sob um teto de orçamento enquanto ainda se baseia nas mesmas tarefas de benchmark.
- Revisar como as pontuações são calculadas: Verifique tarefas abertas e critérios de avaliação para confirmar o que significa “sucesso” no benchmark, e avaliar se isso se alinha ao comportamento esperado.
- Comparar vários provedores em uma única visualização: Use os rankings consolidados para comparar modelos de diferentes provedores (como mostrado na tabela, ex.: modelos OpenAI, Anthropic, Qwen, Minimax e Google).
FAQ
-
Como o PinchBench determina a taxa de sucesso de um modelo? A taxa de sucesso é medida como a porcentagem de tarefas concluídas com sucesso em testes de agente OpenClaw padronizados, usando verificações automatizadas e um juiz LLM.
-
Posso ver o que os testes de benchmark incluem? Sim. A página oferece opções para visualizar tarefas, e afirma que tarefas e critérios de avaliação são open source.
-
Quais métricas são exibidas nos rankings? A tabela de ranking inclui campos de porcentagem relacionados ao sucesso, como “Best %” e “Avg %” (com colunas de pontuação adicionais visíveis na interface).
-
Há uma forma de filtrar modelos por custo? A interface inclui um filtro de orçamento rotulado “Max $per run”, que você pode usar para restringir os resultados exibidos.
-
O PinchBench avalia qualidade geral de chat? O site faz benchmark específico de modelos em tarefas de codificação de agente OpenClaw, e a taxa de sucesso exibida corresponde a esse contexto de benchmark padronizado.
Alternativas
- Leaderboards gerais de LLM: Rankings amplos e não específicos de tarefas podem ser úteis para uma verificação rápida, mas geralmente não medem desempenho em tarefas de codificação de agente OpenClaw.
- Harness de avaliação própria / benchmarks internos: Executar um conjunto curado de tarefas de codificação e aplicar sua abordagem de avaliação pode se adequar melhor às suas necessidades, mas exige configuração e manutenção contínua.
- Evals e benchmarks específicos de provedores: Alguns fornecedores publicam resultados de desempenho em benchmarks; estes podem diferir em design de tarefas e avaliação do PinchBench, então comparações devem ser tratadas com cautela.
- Ferramentas de avaliação de frameworks de agente: Ferramentas que permitem testar LLMs com fluxos de trabalho de agente podem fornecer resultados alinhados ao workflow, mas podem não oferecer o mesmo benchmark padronizado entre modelos e critérios de avaliação abertos do PinchBench.
Alternativas
AakarDev AI
AakarDev AI é uma plataforma poderosa que simplifica o desenvolvimento de aplicações de IA com integração perfeita de banco de dados vetorial, permitindo implantação rápida e escalabilidade.
BookAI.chat
BookAI permite que você converse com seus livros usando IA, simplesmente fornecendo o título e o autor.
skills-janitor
skills-janitor audita, rastreia e compara suas skills do Claude Code com nove ações focadas por comandos slash, sem dependências.
FeelFish
FeelFish AI Novel Writing Agent para PC ajuda a criar personagens e cenários, gerar e editar capítulos e continuar tramas com consistência.
BenchSpan
BenchSpan executa benchmarks de agentes de IA em paralelo, registra scores e falhas em um histórico organizado e facilita reprodutibilidade por commit.
ChatBA
ChatBA é uma IA generativa para criar apresentações em slides com um fluxo de chat: gere rascunhos rapidamente a partir das suas ideias.