SemanticGuard
SemanticGuard é um AI gateway com cache autovalidável para APIs LLM da OpenAI, Anthropic e Google. Mede poupanças e mantém pedidos em fluxo.
O que é SemanticGuard?
SemanticGuard é um AI gateway e um cache autovalidável para APIs LLM. Fica no caminho da requisição para fornecedores como OpenAI, Anthropic e Google, armazenando respostas em cache enquanto usa verificação em múltiplas camadas para confirmar se uma resposta em cache ainda está correta.
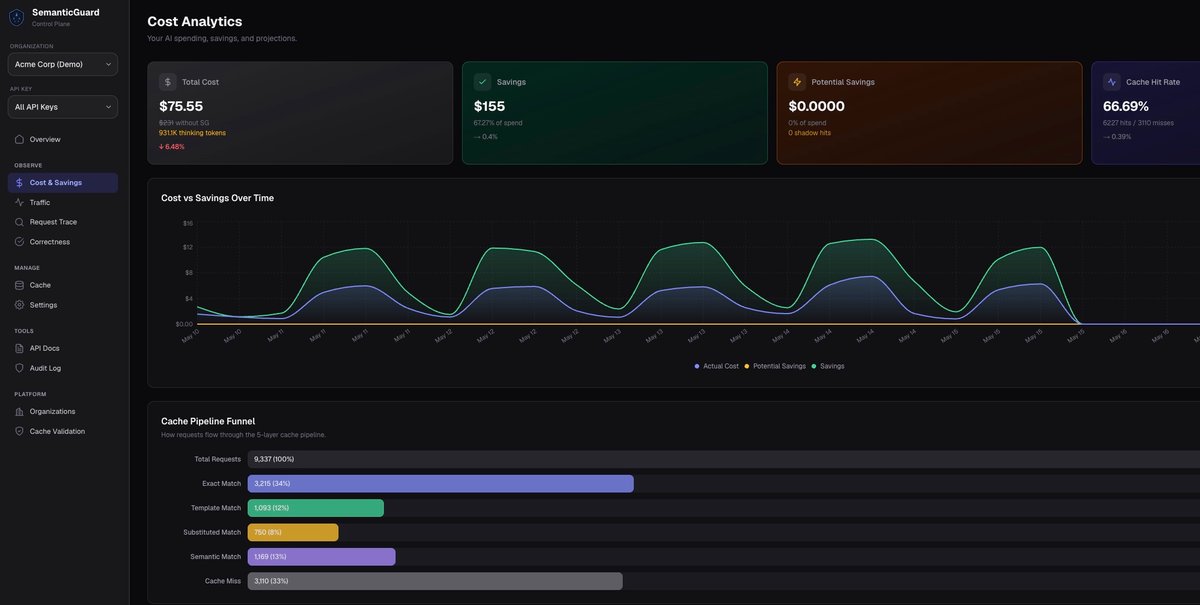
O produto foi criado para reduzir os gastos com APIs LLM sem obrigar os utilizadores a alterar prompts ou a gerir objetos de cache manualmente. Também inclui um Shadow Mode que mede poupanças potenciais antes de o cache ser ativado e suporta um design fail-open para que os pedidos continuem para o fornecedor upstream se o cache ficar indisponível.
Principais funcionalidades
- Integração SDK numa só linha via
fetch: withSemanticGuard()no AI SDK, permitindo às equipas adicionar cache sem reescrever a lógica da aplicação. - Medição em Shadow Mode que mostra o custo por pedido, poupanças projetadas, tipos de hit e onde o tráfego seria armazenado em cache antes de servir quaisquer respostas em cache.
- Cache autovalidável com verificação em múltiplas camadas, com hits amostrados também julgados por IA quanto à correção e falhas assinaladas.
- Suporte multi-fornecedor em OpenAI, Anthropic, Google e outros fornecedores listados, como Azure, Bedrock e Mistral.
- Comportamento de cache ajustado para correspondências semânticas, para que pedidos com nomes, datas ou IDs diferentes ainda possam dar hit quando a პასუხa é, na prática, a mesma.
- Tratamento fail-open de pedidos, que envia o tráfego diretamente para o fornecedor se o cache estiver em baixo.
- Controlos de segurança referidos no site, incluindo encriptação em trânsito e em repouso, armazenamento opcional de prompts e chaves API upstream passadas no momento do pedido em vez de serem guardadas.
Como usar o SemanticGuard
Os programadores adicionam o SemanticGuard à configuração do AI SDK envolvendo a camada fetch com withSemanticGuard() e depois enviam os pedidos normalmente. O fluxo mostrado no site começa com Shadow Mode para medir poupanças e observar como o tráfego seria classificado.
Quando a equipa estiver confortável com os resultados, o cache pode ser ativado. Nessa altura, os cache hits são devolvidos automaticamente e o dashboard pode ser usado para rever poupanças, taxa de hits e resultados de validação.
Casos de uso
- Reduzir gastos em aplicações LLM de alto volume, onde muitos utilizadores fazem perguntas sobrepostas e respostas repetidas podem ser reutilizadas.
- Medir a economia do cache antes do rollout, especialmente para equipas que querem quantificar poupanças sem servir output em cache de imediato.
- Servir pedidos semanticamente semelhantes que diferem em detalhes superficiais como nomes, datas ou IDs, onde o cache por bytes idênticos do fornecedor não daria hit.
- Suportar stacks de IA multi-fornecedor que precisam de uma única camada de cache entre diferentes vendors de modelos.
- Manter a disponibilidade em apps de produção que precisam de um caminho alternativo se a camada de cache ficar indisponível.
FAQ
O SemanticGuard requer alterações nos prompts? Não. O site descreve uma integração SDK numa só linha e diz que não é necessário alterar prompts.
Posso testar poupanças antes de ativar cache hits? Sim. O SemanticGuard inclui Shadow Mode, que mede o que pouparia antes de as respostas em cache serem servidas.
Funciona com mais de um fornecedor de modelos? Sim. A página lista OpenAI, Anthropic, Google e também menciona compatibilidade com outros fornecedores como Azure, Bedrock e Mistral.
O que acontece se o cache ficar indisponível? O produto é descrito como fail-open, o que significa que os pedidos vão diretamente para o fornecedor.
O produto é apenas para caching de correspondência exata? Não. A página apresenta o SemanticGuard como semantic caching, orientado para pedidos que significam a mesma coisa mesmo quando detalhes como nomes, datas ou IDs mudam.
Alternativas
- Prompt caching nativo do fornecedor, como caching integrado da OpenAI ou de vendors semelhantes. Normalmente é limitado à reutilização de prefixos exatos ou quase exatos no sistema do próprio fornecedor e é mais adequado a segmentos estáticos de prompt.
- Camadas de cache manuais integradas numa aplicação ou proxy. Podem ser personalizadas, mas geralmente exigem mais trabalho de engenharia para definir cache keys, gerir invalidação e verificar correção.
- AI gateways gerais sem validação semântica. Podem tratar de routing, observabilidade ou aplicação de políticas, mas não se focam necessariamente em caching com verificações de correção.
- Uso direto do fornecedor sem camada de cache. É a configuração mais simples, mas não acrescenta reutilização entre pedidos semelhantes nem um fluxo de medição de poupanças antes do lançamento.
Alternativas
AakarDev AI
AakarDev AI é uma plataforma poderosa que simplifica o desenvolvimento de aplicações de IA com integração perfeita de banco de dados vetorial, permitindo implantação rápida e escalabilidade.
Ably Chat
Ably Chat é uma API de chat e SDKs para criar apps de mensagens em tempo real com reações, presença e edição/remoção de mensagens.
BookAI.chat
BookAI permite que você converse com seus livros usando IA, simplesmente fornecendo o título e o autor.
DeepMotion
DeepMotion é uma plataforma de body-tracking e motion capture com IA para gerar animações 3D a partir de vídeo (ou texto) no navegador, com Animate 3D API.
skills-janitor
skills-janitor audita, rastreia e compara suas skills do Claude Code com nove ações focadas por comandos slash, sem dependências.
Arduino VENTUNO Q
Arduino VENTUNO Q é um computador edge AI para robótica, unindo inferência e microcontrolador para controle determinístico. Desenvolva no Arduino App Lab.