Long Horizon
Long Horizon — агентный инструмент для тестирования фронтенда: планирует, пишет и запускает реальные браузерные тесты, формируя отчёты со скриншотами и логами.
Что такое Long Horizon?
Long Horizon — агентный инструмент для тестирования фронтенда, который позволяет кодовому агенту планировать, создавать и запускать браузерные тесты для веб-приложения. Его основная цель — помогать командам проверять функции в реальном браузере и выявлять проблемы с доказательствами для анализа.
В отличие от простого создания тестов, Long Horizon запускает их в реальной браузерной сессии и генерирует отчёты об исполнении для совместного использования. Эти отчёты включают логи выполнения и вложения, такие как скриншоты и детали сети, что поддерживает отладку и воспроизводимые запуски тестов.
Ключевые возможности
- Планирование тестов агентом на основе контекста функции и репозитория
- Агент составляет план тестирования (основные пути, крайние случаи и сценарии сбоев) на основе данных о функции и репозитории.
- Автоматический запуск браузерных тестов
- Тесты выполняются в реальном браузере, поэтому проверки отражают реальное поведение UI и сетевые взаимодействия.
- Отчёты об исполнении с логами и вложениями для совместного использования
- Выводы предназначены для анализа, включая логи выполнения и артефакты, такие как скриншоты.
- Надёжные и воспроизводимые запуски
- Рабочий процесс акцентирует повторяемые сессии, чтобы сбои можно было пересмотреть и понять.
- Создание тестов с записью в файлы проекта
- Агент пишет тесты в проекте (примеры включают несколько файлов тестов, связанных с оформлением заказа).
- Рабочий процесс отладки для неудачных тестов
- При сбое запуска агент определяет причину и предлагает изменения; разработчики могут анализировать логи и помогать в сложных сценариях.
- Режим замедления / пошаговый режим для ручного анализа
- Запуски можно выполнять в режимах для наблюдения за поведением при сбоях или сложных потоках.
- Обратная связь в UI для корректировки агента
- Пользователи могут оставлять комментарии прямо в UI на уровне элементов; агент учитывает контекст, такой как скриншоты и HTML элементов.
Как использовать Long Horizon
- Начните с функции в разработке и предоставьте агенту релевантный контекст репозитория.
- Попросите агента составить план тестов для функции (включая счастливые пути, крайние случаи и сценарии ошибок).
- Пусть агент напишет тесты в проекте, затем запустит их в реальном браузере.
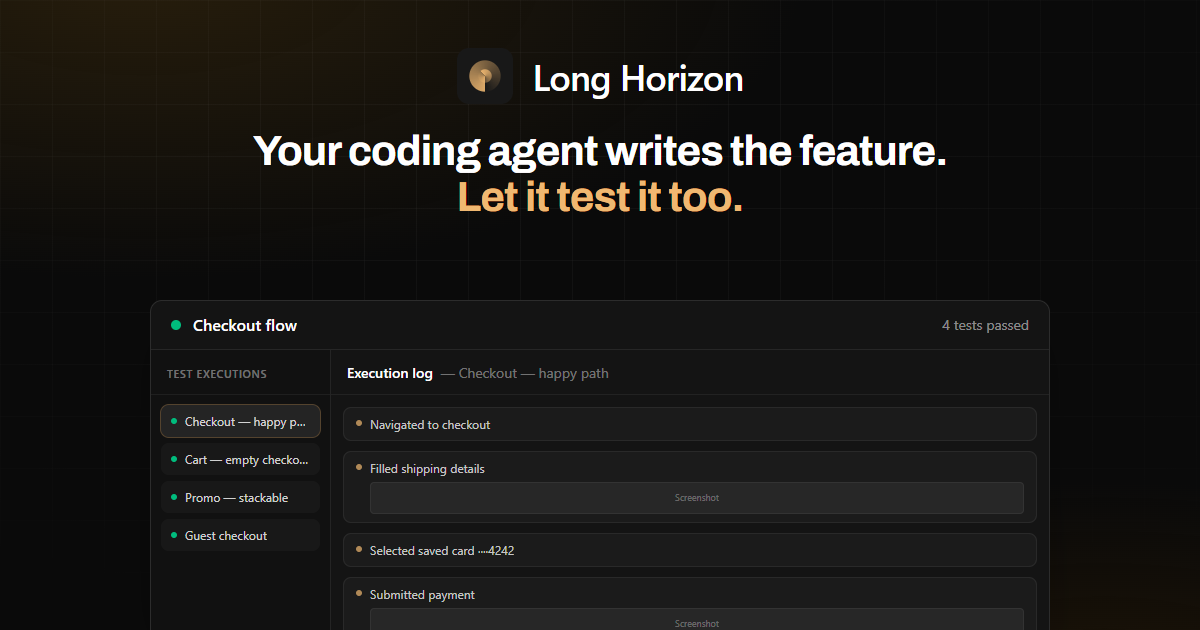
- Проанализируйте сгенерированный отчёт об исполнении, включая логи и прикреплённые скриншоты.
- Если тест не прошёл, используйте процесс отладки — изучите вывод сбоя, позвольте агенту предложить исправления, затем перезапустите.
В приведённых примерах рабочий процесс включает планирование сценариев для оформления заказа (например, «checkout — happy path», «cart — empty checkout blocked» и «payment — decline and retry»), запуск их в браузерной сессии и проверку утверждений, таких как ID подтверждения и видимость DOM.
Сценарии использования
- Регрессионное тестирование счастливого пути оформления заказа для авторизованных пользователей
- Запустите сценарий, спланированный агентом, где авторизованный пользователь завершает покупку, и проверьте, что маршрут подтверждения отображает ожидаемые идентификаторы (например, ID заказа и email в DOM).
- Блокировка оформления заказа при пустой корзине
- Проверьте, что кнопка оформления заказа остаётся неактивной при пустой корзине и что сетевые вызовы, связанные с оплатой, не запускаются.
- Обработка сценариев отклонения карты и повторной попытки
- Смоделируйте отклонение карты, убедитесь, что отображается встроенная ошибка, и проверьте, что пользователи могут сменить способ оплаты и успешно завершить заказ.
- Тестирование оформления заказа без регистрации и оплаты только по email
- Проверьте сценарий оформления заказа без аккаунта и убедитесь, что предоплатные проверки (такие как проверки на мошенничество, упомянутые в источнике) выполняются перед оплатой.
- Отладка и исправление сбоев в сложных потоках
- Когда браузерный тест не проходит из-за неожиданного блока (например, ограничение по наличию на складе), используйте логи для выявления проблемы, обновите моки/заглушки (такие как наличие товара) и перезапустите.
Часто задаваемые вопросы
Генерирует ли Long Horizon тесты или только запускает их?
И то, и другое. Агент составляет план теста, пишет тесты в проекте, а затем выполняет их в реальном браузере.
Какой вывод производит Long Horizon после запуска теста?
Отчёты о выполнении — это общедоступные материалы с полными логами выполнения, вложениями вроде скриншотов и дополнительными деталями, такими как информация о сети.
Могут ли разработчики просматривать сбои и пошагово проходить сценарии?
Да. Рабочий процесс включает обзор логов выполнения разработчиком, а также режимы медленного выполнения и пошагового режима для ручной инспекции.
Как работает отладка агента?
При сбое теста агент выявляет проблему и предлагает исправления; разработчики также могут помочь, например, скорректировав моки (такие как inventory) и перезапустив тест.
Как члены команды могут давать указания агенту при исправлениях?
Предусмотрен интерфейс обратной связи в UI, где пользователи оставляют комментарии к элементам интерфейса. Агент использует скриншот, комментарии и HTML элемента.
Альтернативы
- Традиционные фреймворки для end-to-end тестирования фронтенда
- Инструменты категории E2E запускают браузерные тесты, но обычно требуют больше ручного планирования и написания тестов, а не агентного планирования, написания и выполнения.
- Скриптовые наборы тестов QA с ручным триажем
- Команды пишут и запускают скриптовые тесты, затем отлаживают по логам; отличие Long Horizon — в агентном рабочем процессе для планирования, написания и отладки.
- Агентные инструменты рабочих процессов, генерирующие тесты без реальных запусков в браузере
- Некоторые подходы фокусируются на генерации кода тестов или отчётов; позиционирование Long Horizon — именно вокруг реального выполнения в браузере с проверяемыми отчётами.
- Пайплайны тестирования браузера на базе CI
- Настройки непрерывной интеграции повторно запускают браузерные тесты; Long Horizon акцентирует агентное создание тестов и общедоступные отчёты для поддержки доставки фич и отладки.
Альтернативы
PromptLayer
PromptLayer помогает командам версионировать и тестировать промпты и AI-агентов с evals, трассировкой и regression sets, а также в визуальном редакторе.
Evidently AI
Evidently AI — платформа для оценки и LLM observability: тестирование, мониторинг продакшн AI, RAG-оценка, синтетические adversarial тесты и трекинг качества.
Crikket
Crikket: бесплатная open-source платформа для отчетов об ошибках. Мгновенно фиксируйте и делитесь техническими деталями для быстрого исправления багов.
Roo Code
Roo Code — ИИ-команда для разработки в редакторе и через облачные агенты: роли, контролируемые действия и GitHub-процессы для кода, отладки и тестов.
Logic
Logic — платформа для агентства по спецификациям: превращает описания в готовые production API, с тестами, версионированием и логированием выполнения.
TestLaunch Pro
TestLaunch Pro — платформа платного тестирования приложений: привлекайте opted-in тестеров для Google Play закрытого теста, а тестеры скачивают и делятся фидбеком.