PinchBench
Сравнивайте производительность агентов OpenClaw на 100+ LLM по рейтингу успешности: автоматические проверки и оценка LLM судья.
Что такое PinchBench?
PinchBench — это сайт для бенчмаркинга моделей LLM OpenClaw, который ранжирует ИИ-модели по успешности на стандартизированных задачах кодирования. Основная цель — помочь сравнить несколько LLM в одинаковых условиях тестирования на базе агентов, чтобы выбрать модель по реальным результатам, а не предположениям.
Сайт показывает рейтинги «Успешность по моделям» и позволяет просматривать дополнительные задачи и детали оценки. Также указано, что оценка и скоринг автоматизированы с использованием автоматических проверок и судьи LLM.
Ключевые возможности
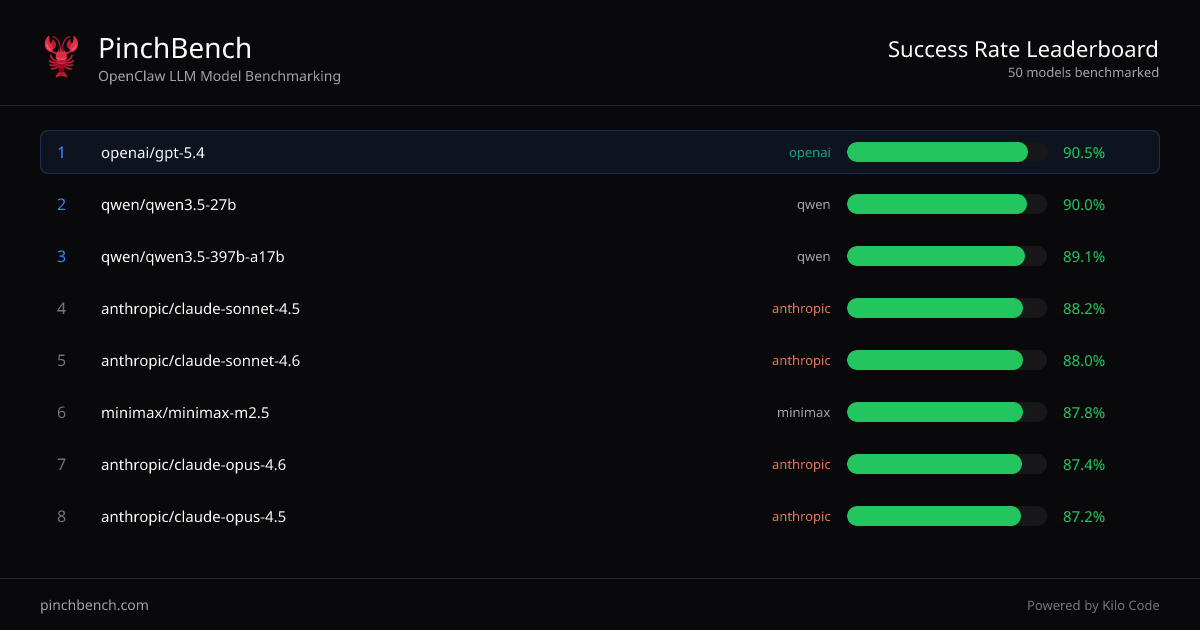
- Рейтинги успешности по моделям: Отображает отсортированную таблицу моделей с полями «Best %», «Avg %» и связанными колонками оценок для последовательного сравнения производительности.
- Бенчмаркинг агентов OpenClaw: Оценивает модели именно в контексте рабочего процесса агента «OpenClaw», отражая их производительность на задачах кодирования с участием агента.
- Автоматизированная оценка с проверками и судьей LLM: Оценки получаются из автоматических проверок и судьи LLM, обеспечивая повторяемый метод оценки.
- Фильтр по бюджету (макс. $ за запуск): Включает фильтр бюджета «Max $per run», позволяющий сосредоточить сравнения в пределах стоимостных ограничений, отображаемых интерфейсом.
- Прозрачные тестовые материалы и критерии: Указано, что «Все задачи и критерии оценки с открытым исходным кодом», и предоставлен способ просмотра задач.
Как использовать PinchBench
- Перейдите на PinchBench и используйте таблицу рейтинга моделей, чтобы сравнить модели по успешности.
- При необходимости настройте фильтр по бюджету с помощью элемента управления «Max $ per run», чтобы сузить результаты до моделей, подходящих под ваш лимит затрат.
- Используйте просмотр задач и детали оценки (включая открытые критерии оценки), чтобы понять, что измеряют оценки, перед выбором модели.
Сценарии использования
- Выбор LLM для агента кодирования OpenClaw: Сравните кандидатов по измеренной успешности на стандартизированных задачах агента, затем выберите лучший вариант для вашего случая.
- Оценка пиковой vs. средней производительности: Используйте колонки «Best %» и «Avg %» в таблице, чтобы отличить модели с высокими пиками от тех, что дают более стабильные результаты.
- Сравнение моделей с учетом затрат: Примените фильтр max $ per run, чтобы сравнить модели в пределах бюджетного потолка, опираясь на одни и те же бенчмарк-задачи.
- Проверка вычисления оценок: Просмотрите открытые задачи и критерии оценки, чтобы убедиться, что «успешность» соответствует бенчмарку и вашим ожиданиям.
- Сравнение провайдеров в одном представлении: Используйте консолидированные рейтинги для сравнения моделей от разных провайдеров (как показано в таблице, например, OpenAI, Anthropic, Qwen, Minimax и модели Google).
FAQ
-
Как PinchBench определяет успешность модели? Успешность измеряется как процент успешно завершенных задач в стандартизированных тестах агентов OpenClaw с использованием автоматических проверок и судьи LLM.
-
Можно ли увидеть, что входит в бенчмарк-тесты? Да. Страница предоставляет опции просмотра задач, и указано, что задачи и критерии оценки имеют открытый исходный код.
-
Какие метрики показаны в рейтингах? Таблица рейтинга включает процентные поля, связанные с успешностью, такие как «Best %» и «Avg %» (с дополнительными колонками оценок, видимыми в интерфейсе).
-
Есть ли способ фильтровать модели по стоимости? Интерфейс включает фильтр бюджета с меткой «Max $per run», который можно использовать для ограничения отображаемых результатов.
-
Оценивает ли PinchBench общее качество чата? Сайт специально бенчмаркит модели на задачах кодирования агентов OpenClaw, и показанная успешность соответствует этому стандартизированному контексту бенчмарка.
Альтернативы
- Общие лидерборды LLM: Широкие рейтинги без привязки к задачам полезны для быстрого обзора, но обычно не измеряют производительность на задачах кодирования агентов OpenClaw.
- Собственный evaluation harness / внутренние бенчмарки: Запуск куративного набора задач кодирования с вашей методикой оценки лучше соответствует требованиям, но требует настройки и постоянного обслуживания.
- Evals и бенчмарки от провайдеров: Некоторые вендоры публикуют результаты по бенчмаркам; они могут отличаться по дизайну задач и оценке от PinchBench, поэтому сравнения требуют осторожности.
- Инструменты оценки agent-framework: Инструменты для тестирования LLM с рабочими процессами агентов дают результаты, aligned с workflow, но могут не предлагать такой же стандартизированный кросс-модельный бенчмарк и открытые критерии оценки, как PinchBench.
Альтернативы
AakarDev AI
AakarDev AI — это мощная платформа, которая упрощает разработку приложений ИИ с бесшовной интеграцией векторных баз данных, позволяя быстрое развертывание и масштабируемость.
BookAI.chat
BookAI позволяет вам общаться с вашими книгами, просто предоставив название и автора.
skills-janitor
skills-janitor для Claude Code: аудит и учет навыков, сравнение с девятью командами /janitor-* и поиск дублей без зависимостей.
FeelFish
FeelFish AI Novel Writing Agent — клиент для ПК: планируйте персонажей и мир, генерируйте и редактируйте главы, продолжайте сюжет с сохранением контекста.
BenchSpan
BenchSpan запускает AI agent бенчмарки параллельно, фиксирует результаты и ошибки в истории прогонов, помогает воспроизводить их по commit hash.
ChatBA
ChatBA — генеративный AI для создания слайд‑деков в чат‑формате: быстро набросайте контент для презентации из ваших идей.