专用模型路由
将可重复的 AI 任务路由到面向特定任务的小型和纳米模型,而不是对每个请求都使用前沿模型。
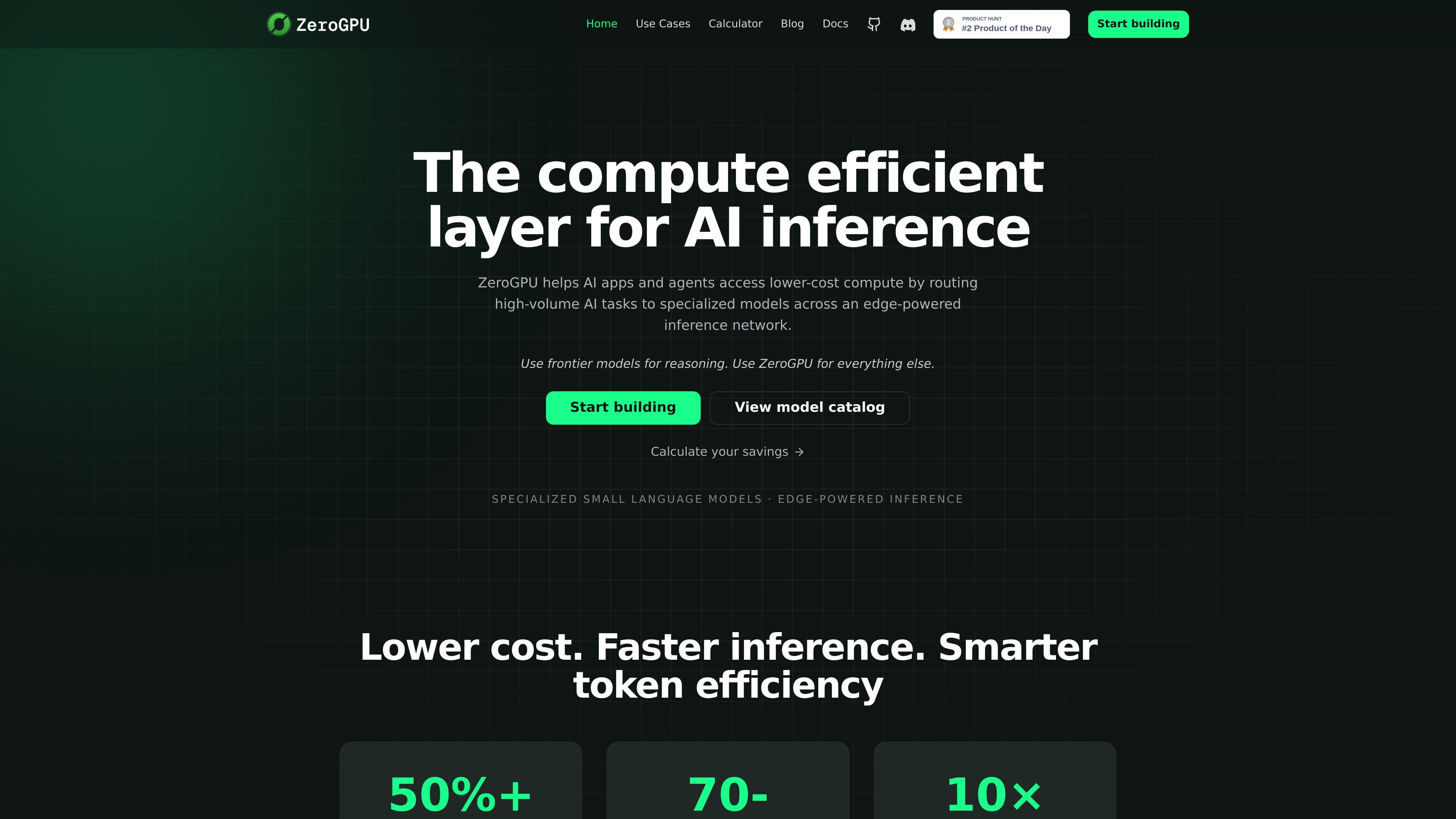
ZeroGPU 是一个面向 AI 应用的分布式推理层,旨在通过将高频任务路由到专门的小型和纳米语言模型来降低计算成本。它不会把每个请求都发送到前沿模型,而是将分类、摘要、信号提取、审核、路由和 PII 检测等常规工作转移到更适合这些任务、成本更低的模型上。
该平台结合了专用模型与边缘驱动执行、优化服务器、已批准的边缘设备以及云端回退。它面向构建生产级 AI 系统的开发者,包括智能体、文档 AI、广告技术、合规、安全和欺诈工作流,并提供兼容 OpenAI 的 API,方便团队将其集成到现有技术栈中。
将可重复的 AI 任务路由到面向特定任务的小型和纳米模型,而不是对每个请求都使用前沿模型。
根据性能和可用性,在优化服务器、已批准的边缘容量和云端回退之间运行推理。
提供兼容 OpenAI 的聊天与响应 API,方便团队无需重新设计应用流程即可集成。
提供项目级 API 密钥,以及使用情况、延迟和节省情况分析,用于追踪运营影响。
支持模型目录和面向工作负载的输出,适用于分类、摘要、PII 检测、审核和路由等任务。
提供一种变现路径,符合条件的应用可将用户设备的空闲时间转化为付费推理能力。
在不把每一步都发送到前沿模型的情况下,对意图进行分类、提取信号并路由重复的智能体任务。
对文档进行摘要、分类页面、提取结构化字段,并在文档流水线中检测 PII。
审核内容、检测政策违规,并实时标记有风险或受监管的材料。
对邮件意图进行分类、对会话进行分流,并将请求路由到合适的团队或队列。
对欺诈和风险信号进行评分,然后只将高风险案例升级到更重的系统。
ZeroGPU 是一个面向 AI 应用的推理层,它会将部分工作负载路由到专门的小型和纳米模型,而不是把每个请求都发送到前沿模型。
网站说明,开发者可以通过兼容 OpenAI 的聊天和响应 API、项目级 API 密钥以及模型目录来集成 ZeroGPU,然后将合适的任务路由到专用模型。
ZeroGPU 主要面向高频任务,例如摘要、分类、信号提取、PII 检测、审核、路由以及类似的结构化 AI 工作负载。
网站描述了适用于集成 SDK 的应用可在设备端参与的变现模式,但仅允许设备处于健康状态,并且一次只运行一个推理请求。
ByteAsk 是面向 C 和 C++ 的终端优先 AI 编码 agent,可直接编辑仓库,并在展示 diff 前用真实编译器、调试器、sanitizers 和测试验证修改。提供免费版与付费方案。
CreateOS Sandbox 是基于 Firecracker 微型虚拟机的隔离计算环境,用于运行代码和 agent 工作负载,支持私有网络、SDK、CLI 和 MCP 程序化控制。
hob 是面向编码 agent 的独立工作区,可将 agent 会话、终端、历史记录和后续工作围绕你已在用的工具与提供商有序管理,适合重视本地路由、历史和工作区结构控制的开发者。
Ably Chat 是用于构建自定义实时聊天应用的 chat API 平台,支持房间消息、输入指示、在线状态、表情回应与消息更新,并提供按使用量计费选项。
Manta AI 是面向团队的自治式网页应用测试工具,可从 URL 自动探索应用、映射行为、捕捉回归,并用自然语言生成测试,无需脚本或维护选择器。
SonOf 连接你的代码仓库和 PM 工具,审计代码库与产品上下文,将已批准工作转为可交付工单,并由资深工程复审,适合缺少完整团队的创始人和技术负责人。