PinchBench 是什麼?
PinchBench 是一個 OpenClaw LLM 模型基準測試網站,依據標準化程式碼任務的成功率來排名 AI 模型。其核心目的是讓您使用相同的代理基測試設定來比較多個 LLM,以便根據實際測量結果而非假設來選擇模型。
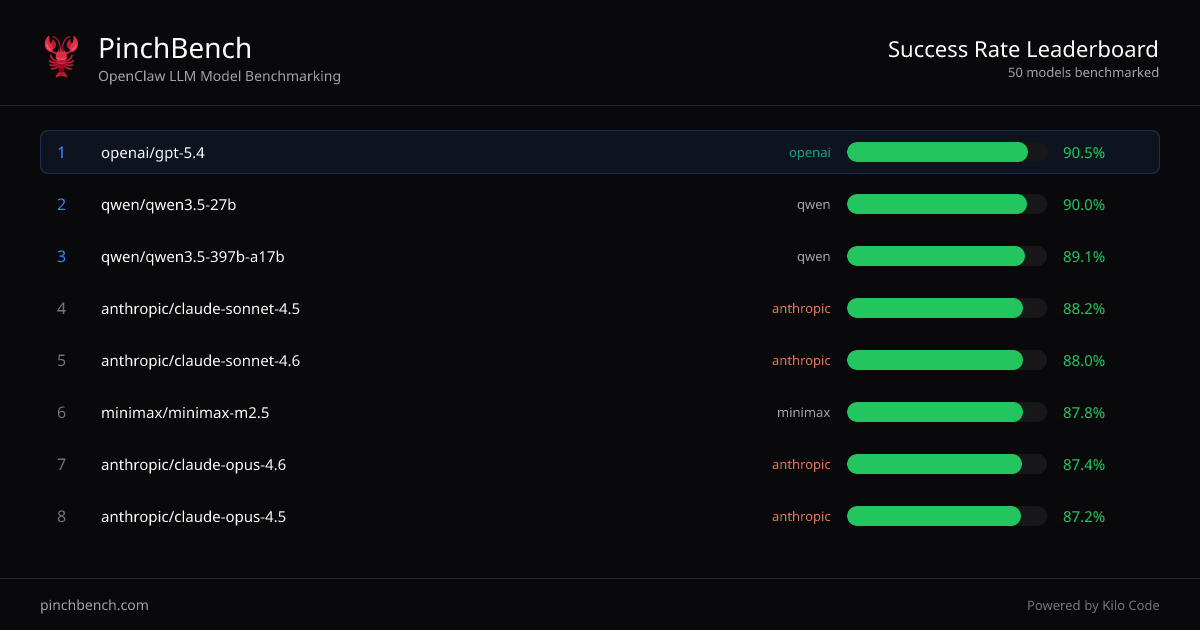
網站呈現「模型成功率」排名,並讓您查看更多任務與評分細節。它也標明評分與計分是使用自動檢查與 LLM 評審自動化進行。
主要功能
- 跨模型成功率排名:顯示模型排序表格,包含「最佳 %」、「平均 %」及相關計分欄位,以便一致比較效能。
- OpenClaw 代理基準測試:特別在「OpenClaw」代理工作流程中評估模型,反映模型在代理驅動程式碼任務上的表現。
- 自動評分結合檢查與 LLM 評審:計分來自自動檢查與 LLM 評審,提供可重複的評估方法。
- 預算篩選(每次執行最高 $):包含標示為「Max $per run」的預算篩選,讓您在介面顯示的成本限制內聚焦比較。
- 透明測試材料與標準:註明「所有任務與評分標準皆為開源」,並提供查看任務的方式。
如何使用 PinchBench
- 前往 PinchBench,使用模型排名表格依成功率比較模型。
- 選擇性調整預算篩選,使用「Max $ per run」控制來縮小結果至符合您指定成本限制的模型。
- 使用任務檢視與評分細節(包含開放評分標準)來了解計分測量內容,再選擇模型。
使用情境
- 為 OpenClaw 程式碼代理選擇 LLM:依標準化代理任務的測量成功率比較候選模型,然後挑選最適合您情境的最佳表現者。
- 評估峰值品質 vs. 平均效能:使用表格的「最佳 %」與「平均 %」欄位,區分峰值表現佳的模型與一致性更高的模型。
- 考量成本的模型比較:套用**每次執行最高 $**篩選,在預算上限下比較模型,同時依賴相同基準任務。
- 檢視計分計算方式:檢查開放任務與評分標準,驗證基準中的「成功」定義,並評估是否符合您預期行為。
- 單一檢視比較多供應商:使用整合排名比較不同供應商模型(如表格所示,例如 OpenAI、Anthropic、Qwen、Minimax 及 Google 模型)。
常見問題
-
PinchBench 如何決定模型成功率? 成功率是依標準化 OpenClaw 代理測試中成功完成的任務百分比,使用自動檢查與 LLM 評審測量。
-
我能看到基準測試包含什麼嗎? 可以。頁面提供檢視任務的選項,並說明任務與評分標準為開源。
-
排名顯示哪些指標? 排名表格包含成功相關百分比欄位,如「最佳 %」與「平均 %」(介面中可见額外計分欄位)。
-
有方式依成本篩選模型嗎? 介面包含標示為「Max $per run」的預算篩選,可用來限制顯示結果。
-
PinchBench 評估一般對話品質嗎? 網站專門基準測試模型在 OpenClaw 代理程式碼任務上的表現,顯示的成功率對應該標準化基準情境。
替代方案
- 一般 LLM 排行榜:廣泛、非任務特定的排名適合快速瀏覽,但通常不測量 OpenClaw 代理程式碼任務效能。
- 自建評估框架 / 內部基準:執行精選程式碼任務並套用您的評分方式,能更符合需求,但需設定與持續維護。
- 供應商特定評估與基準:部分供應商發布跨基準效能結果;這些在任務設計與評分上可能與 PinchBench 不同,比較時應謹慎。
- 代理框架評估工具:允許使用代理工作流程測試 LLM 的工具,能提供工作流程對齊結果,但可能不提供 PinchBench 同樣的標準化跨模型基準與開放評分標準。
替代品
AakarDev AI
AakarDev AI 是一個強大的平台,通過無縫的向量資料庫整合簡化 AI 應用程式的開發,實現快速部署和可擴展性。
BookAI.chat
BookAI允許您透過簡單提供書名和作者與您的書籍進行AI聊天。
skills-janitor
skills-janitor 可審核並追蹤 Claude Code 技能用量,與 9 個聚焦指令做比較,幫你找重複與缺失資訊,無需依賴。
FeelFish
FeelFish AI小說寫作代理 PC 端用戶端,協助規劃角色與世界觀、生成與編輯章節,並以內容脈絡延續劇情一致性。
BenchSpan
BenchSpan 以並行方式執行 AI agent 基準測試,記錄分數與失敗,並以 commit 標記可重現結果,降低失敗重跑的 token 浪費。
ChatBA
ChatBA 用聊天式工作流程,從你的輸入快速生成簡報內容,輕鬆把想法轉成投影片套件。