Unified multimodal inputs
Supports text, image, audio, and video inputs in a single multimodal generation architecture, allowing the model to combine different kinds of reference material.
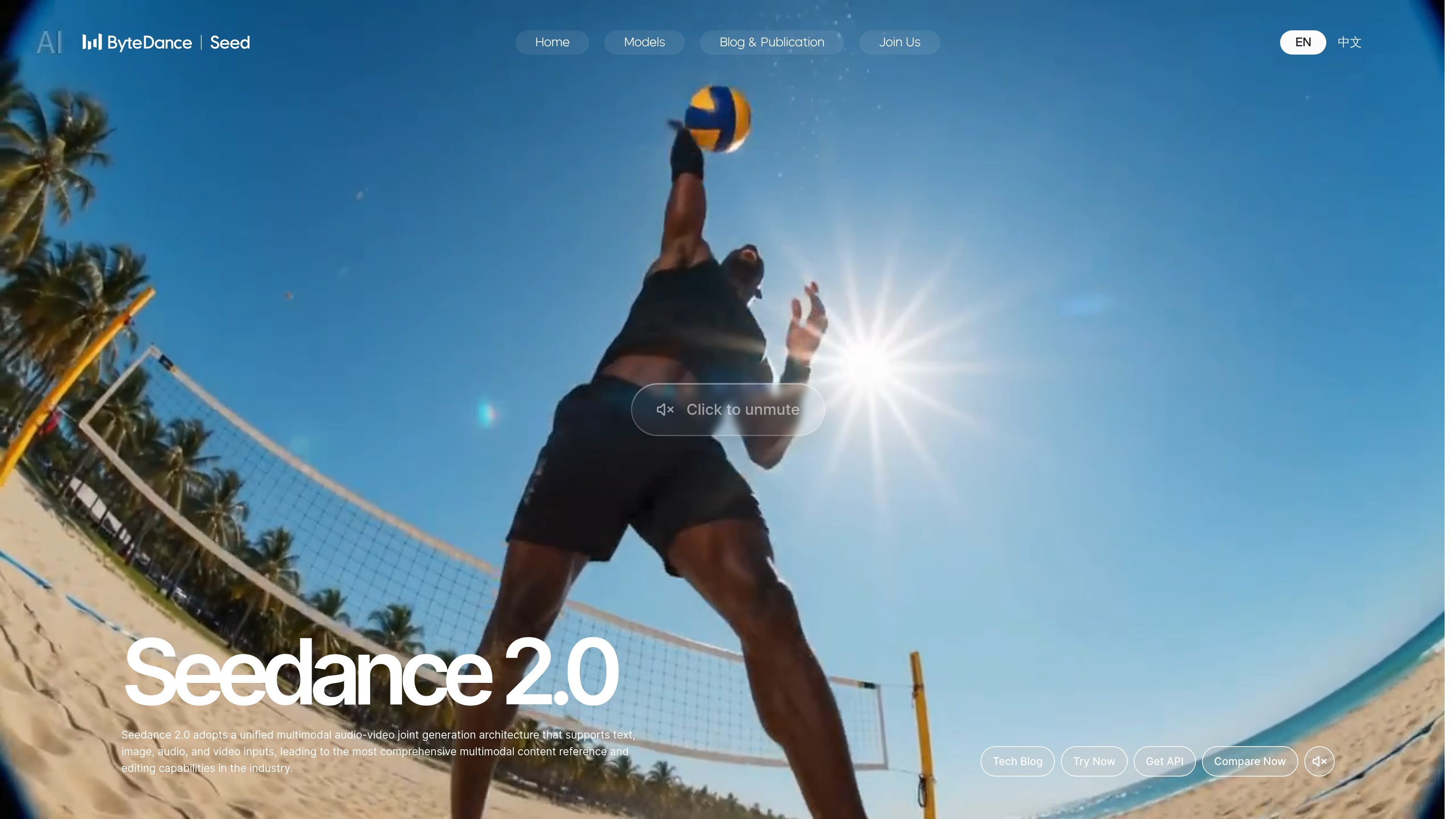
Seedance 2.0 is a multimodal audio-video generation model from ByteDance Seed. The product page describes it as using a unified multimodal audio-video joint generation architecture that accepts text, image, audio, and video inputs.
Its public positioning centers on multimodal content reference and editing for video-related tasks. The page highlights evaluation views for text-to-video, image-to-video, and multimodal tasks, and links to Try Now, Get API, and comparison pages.
Supports text, image, audio, and video inputs in a single multimodal generation architecture, allowing the model to combine different kinds of reference material.
Designed around audio-video joint generation, which frames the model as a system for generating and editing video with multimodal context rather than a single-input tool.
Highlights multimodal content reference and editing capabilities, suggesting the model can use multiple inputs to guide or modify generated output.
The homepage and model index point to text-to-video, image-to-video, and multimodal task evaluation views, indicating support for several generation workflows.
The product page links to a Try Now flow and a Get API option, making the model accessible through interactive use and programmatic access.
Generate video from text prompts when the goal is to create a first draft or concept video from a written brief.
Use image inputs as visual references when turning a still asset into video content or building from an existing design direction.
Combine speech or ambient sound with video inputs for tasks that need joint audio-visual understanding and editing.
Work on multimodal content tasks where several references need to be interpreted together, such as structured content reference or editing guidance.
Seedance 2.0 is presented as a multimodal audio-video generation model that accepts text, image, audio, and video inputs. The public page does not document a full setup guide or usage limits.
The source page links to a Try Now flow, a Get API option, and a comparison page. That suggests both web access and API access are available, but the public sources do not publish pricing or detailed access terms.
The page positions Seedance 2.0 for multimodal content reference and editing, with examples that include text-to-video, image-to-video, and multimodal tasks. It is aimed at users working with generated video content and multimodal inputs.
The public sources mention a unified multimodal audio-video joint generation architecture and point to evaluation charts, but they do not publish supported file formats, resolution limits, or output duration details.
AI Song Maker is a web-based AI music generator that creates songs from text or lyrics and includes related tools such as vocal removal, track extension, and section replacement. It offers free and paid plans with credits, downloads, and commercial-use terms described on the pricing page.
一個集成圖像、視頻、語音、寫作和聊天工具的全能AI平台,以增強創造力和協作。
Slidesgo 是適用於 Google Slides、PowerPoint 與部分 Canva 工作流程的簡報範本平台,提供免費與 Premium 範本,並支援 AI 輔助簡報製作與團隊存取。
VIDEOAI.ME 是一款 AI 影片生成器,可依腳本製作代言人風格影片、廣告、解說影片與社群內容,適合不想拍攝即可產出影片的創業者、行銷人員、代理商與創作者。
Grok 是由 xAI 開發的一款免費 AI 助理,旨在優先考慮真實性和客觀性,同時提供即時資訊存取和圖像生成等進階功能。
Creativly 是一款以網頁為基礎的 AI 創意工作室,能用簡短輸入快速生成視覺概念、產品 mockup 與風格化圖像,特別適合設計師、創作者與創業者進行快速視覺發想。