Loading...
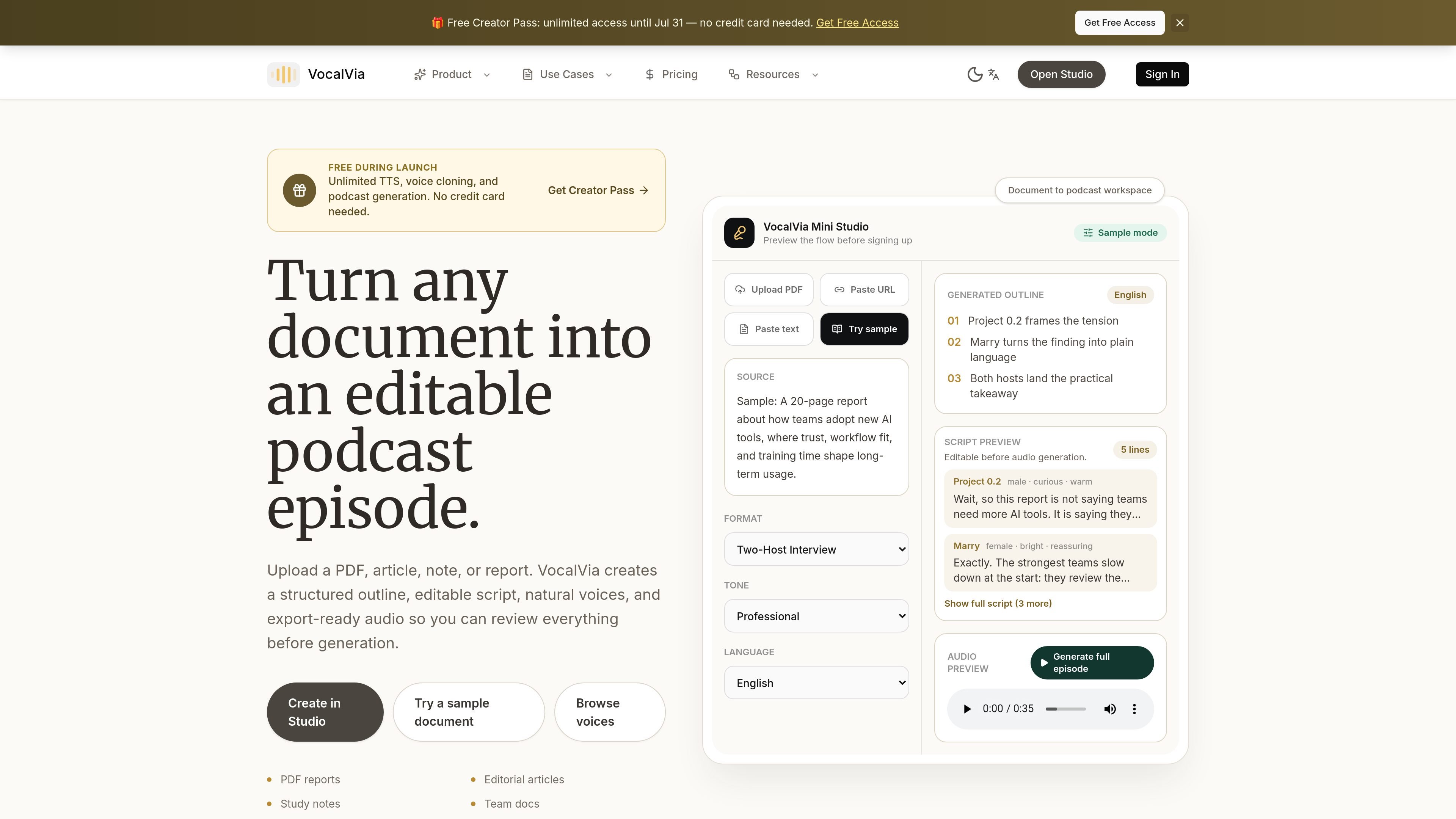
VocalVia is a document-to-podcast tool that converts PDFs, articles, notes, Markdown, and web sources into editable podcast drafts and audio. It is aimed at people who want to review the outline and script before generating the final file.
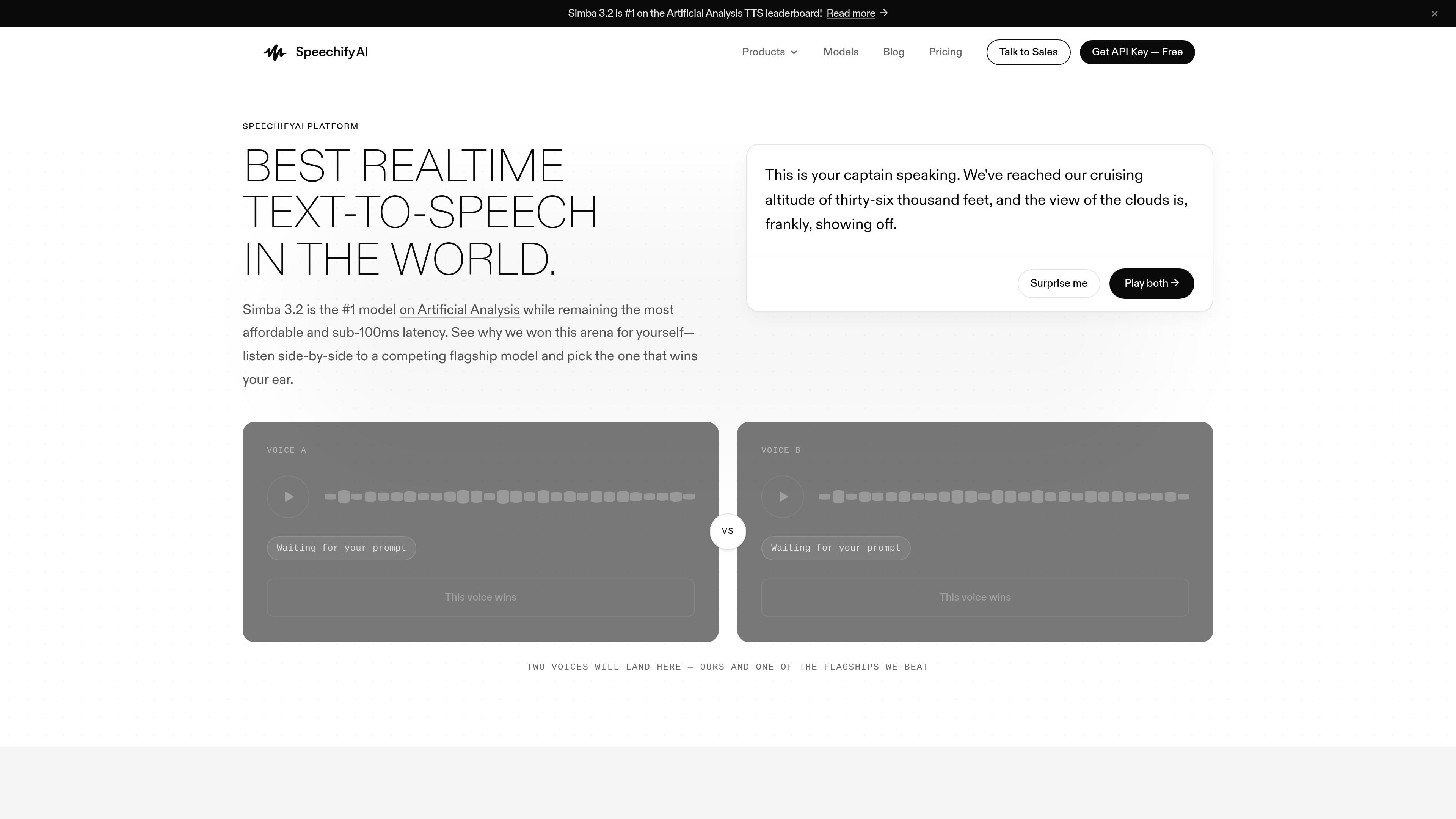
SpeechifyAI is a voice AI platform for generating speech, cloning voices, and building voice agents. It serves developers who need text-to-speech, multilingual audio, and calling workflows through a single API.
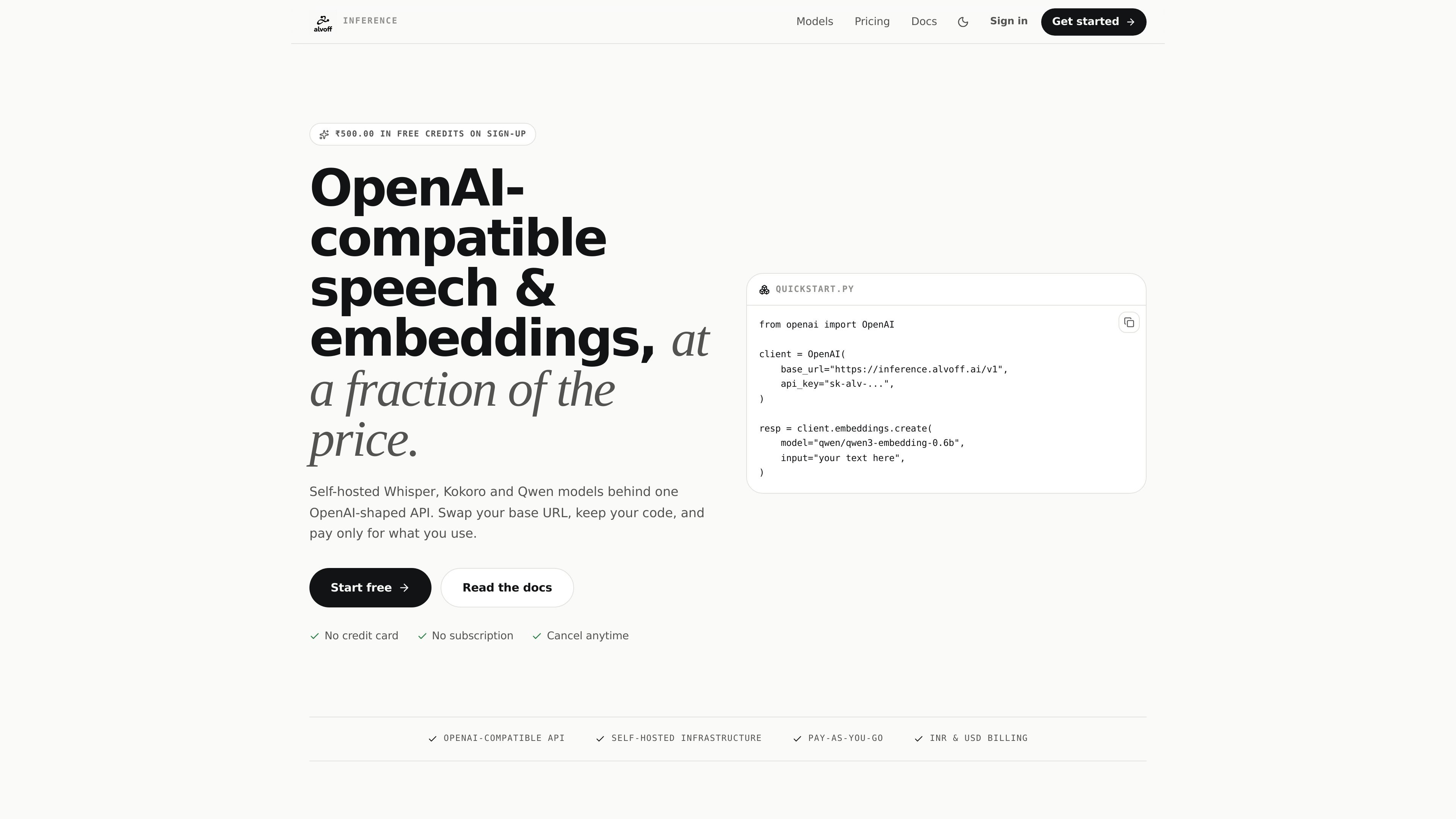
Alvoff Inference is an OpenAI-compatible API for speech-to-text, text-to-speech, embeddings, and chat/code generation. It is built for developers who want to swap in a different base URL, use familiar SDKs, and pay per request.
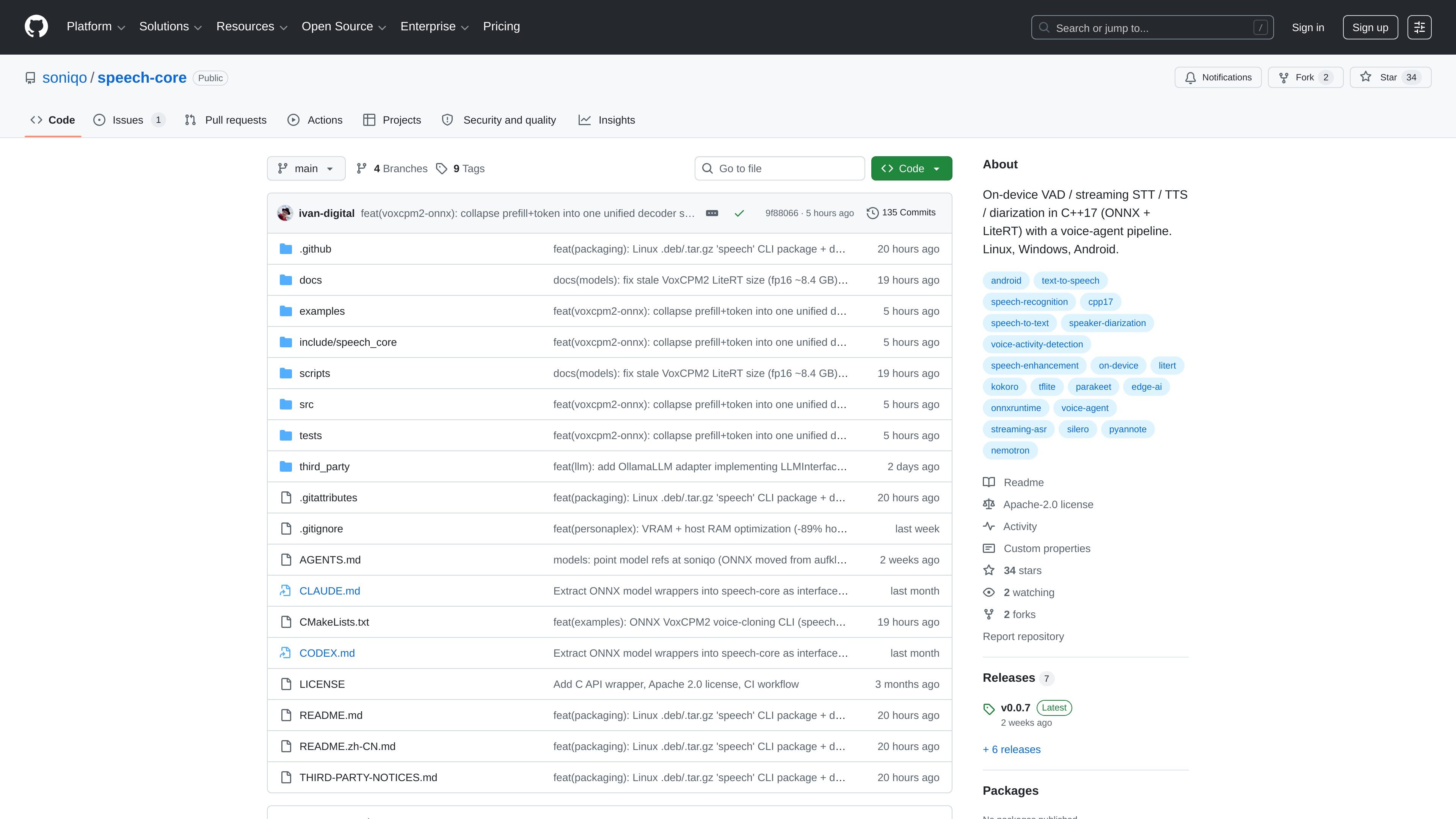
speech-core is a C++17 library for on-device speech orchestration, including VAD, streaming and batch STT, diarization, TTS, and a voice-agent pipeline. It runs locally and uses optional ONNX Runtime or LiteRT backends for model inference.

Voiser AI Voiceover turns text into spoken audio for voiceovers, with multilingual voice options and style controls for different narration needs. It supports a web studio workflow and shows free, paid, and enterprise paths on the site.
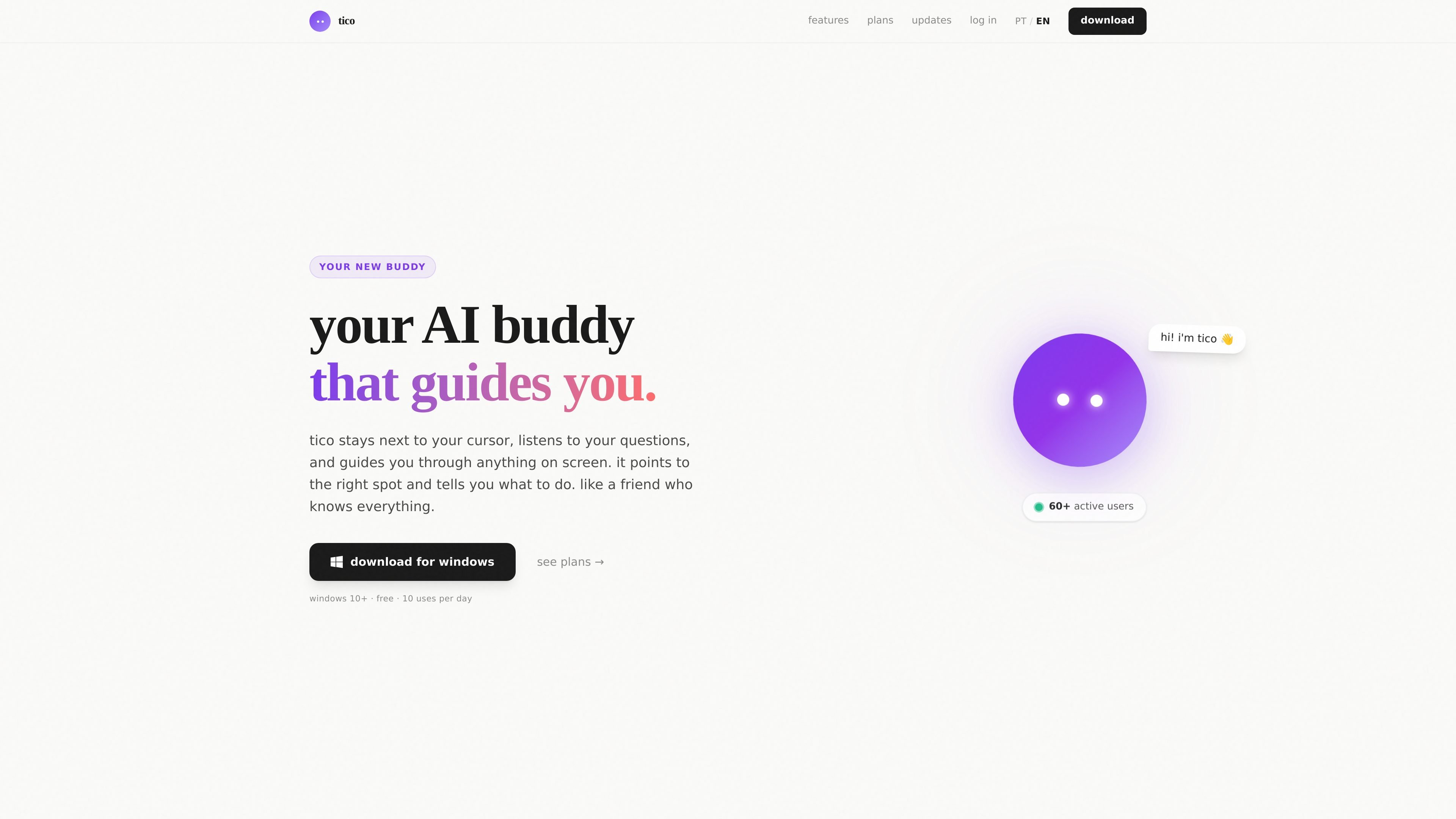
Tico é um assistente de IA para Windows que acompanha o cursor, entende o que está na tela e orienta o usuário por voz. A página indica uso gratuito com limite diário e planos pagos com mais usos e suporte prioritário.
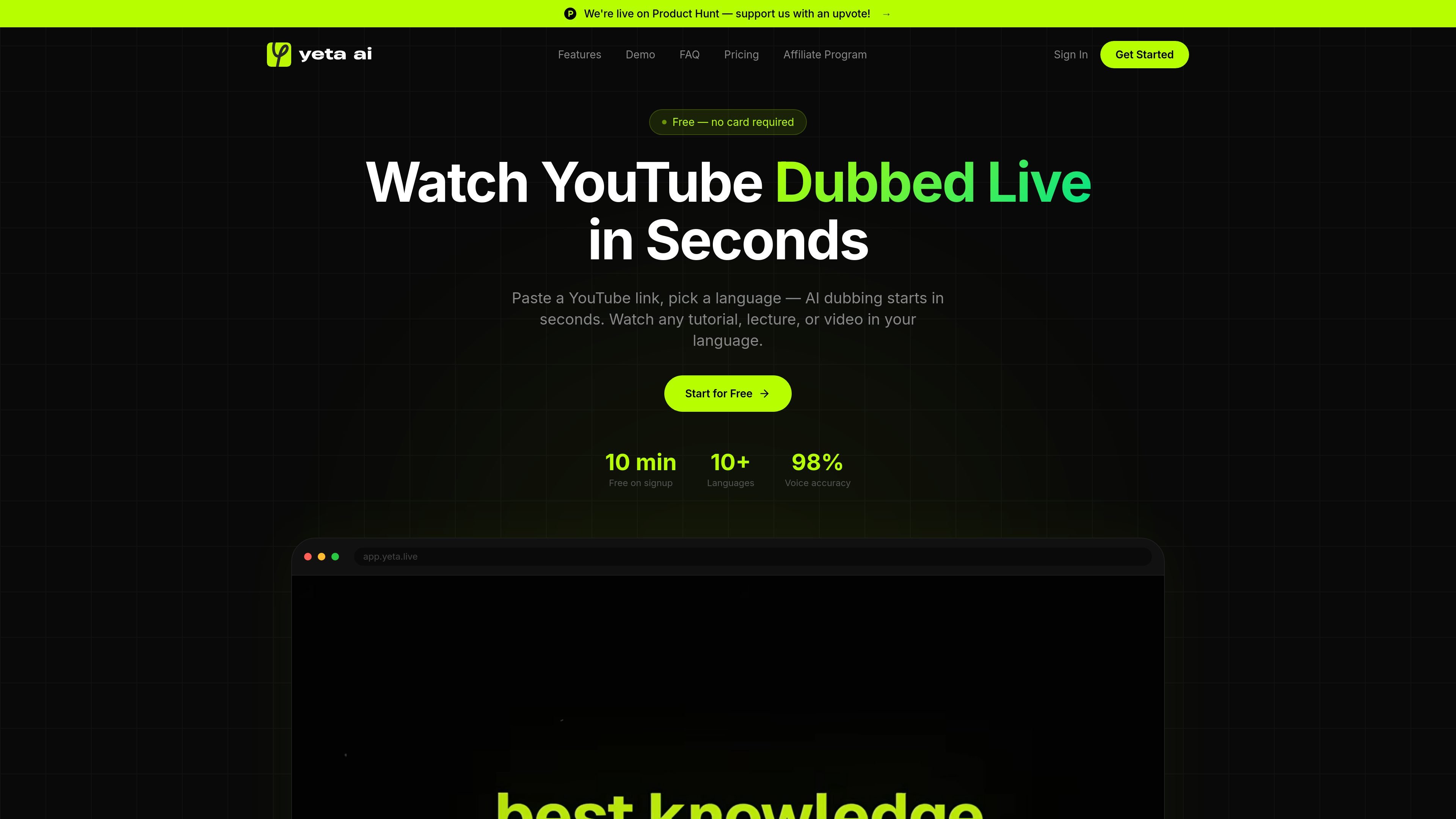
Yeta AI is a browser-based tool that translates and dubs public YouTube videos in real time using AI voices. It is designed for watching tutorials, lectures, and other long-form videos in more than 10 languages without relying on subtitles.

Morph is a web-based reading platform for public-domain classics that combines text, synced narration, and an AI assistant. It helps readers switch between reading and listening, browse a curated library, and get book-specific help without leaving the page.
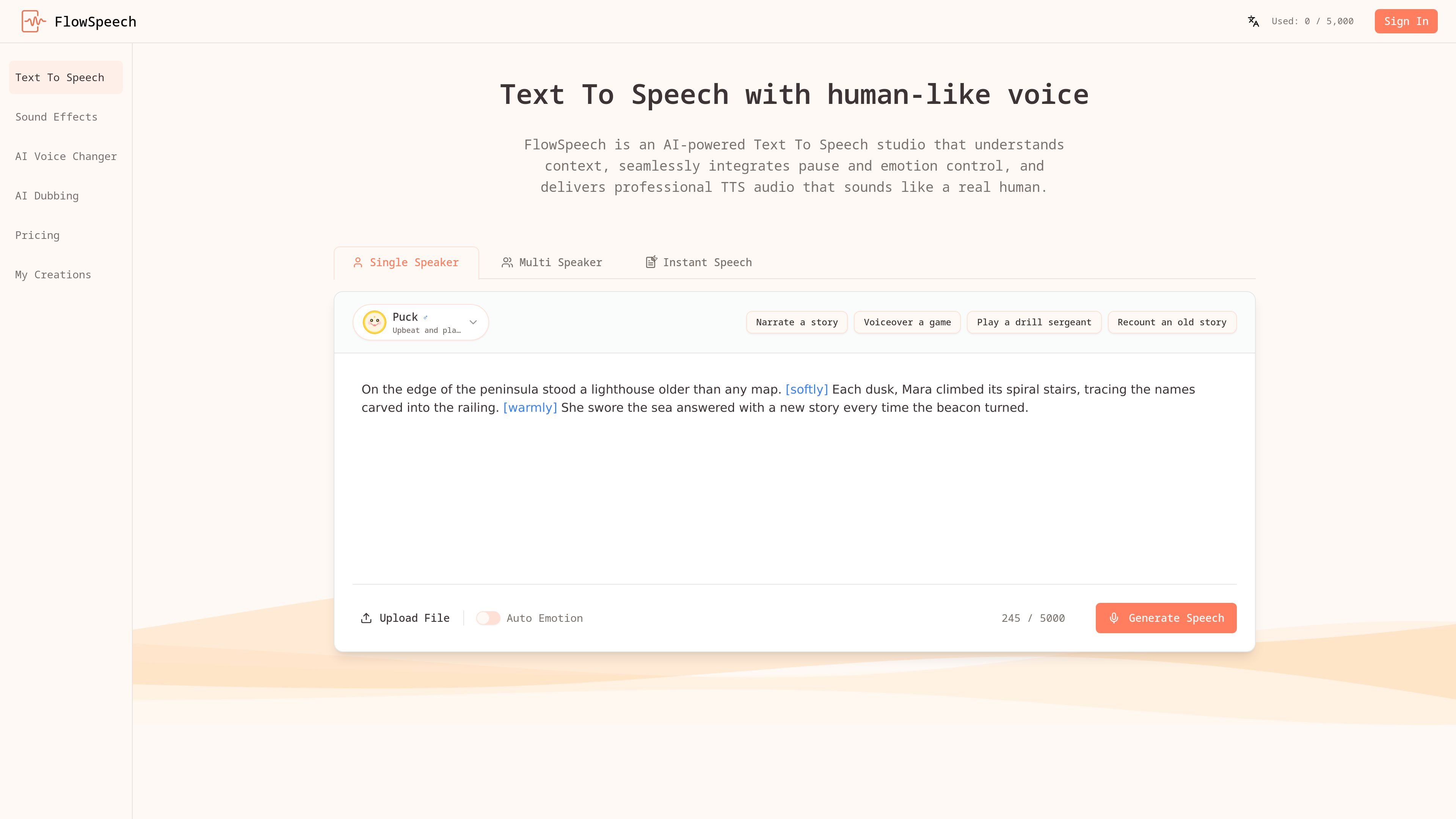
FlowSpeech is a context-aware text-to-speech studio that turns scripts and uploaded files into human-like audio. It offers multiple generation modes, pause and emotion control, and a free plan alongside paid tiers.
xAI’s Grok Speech to Text and Text to Speech APIs let developers add transcription and speech generation to apps through REST and WebSocket endpoints. The product supports multilingual STT, expressive TTS, and usage-based pricing.

Gemini 3.1 Flash TTS is Google’s preview text-to-speech model for generating expressive AI speech with fine-grained control over style and delivery. It is available across the Gemini API, Google AI Studio, Vertex AI, and Google Vids.
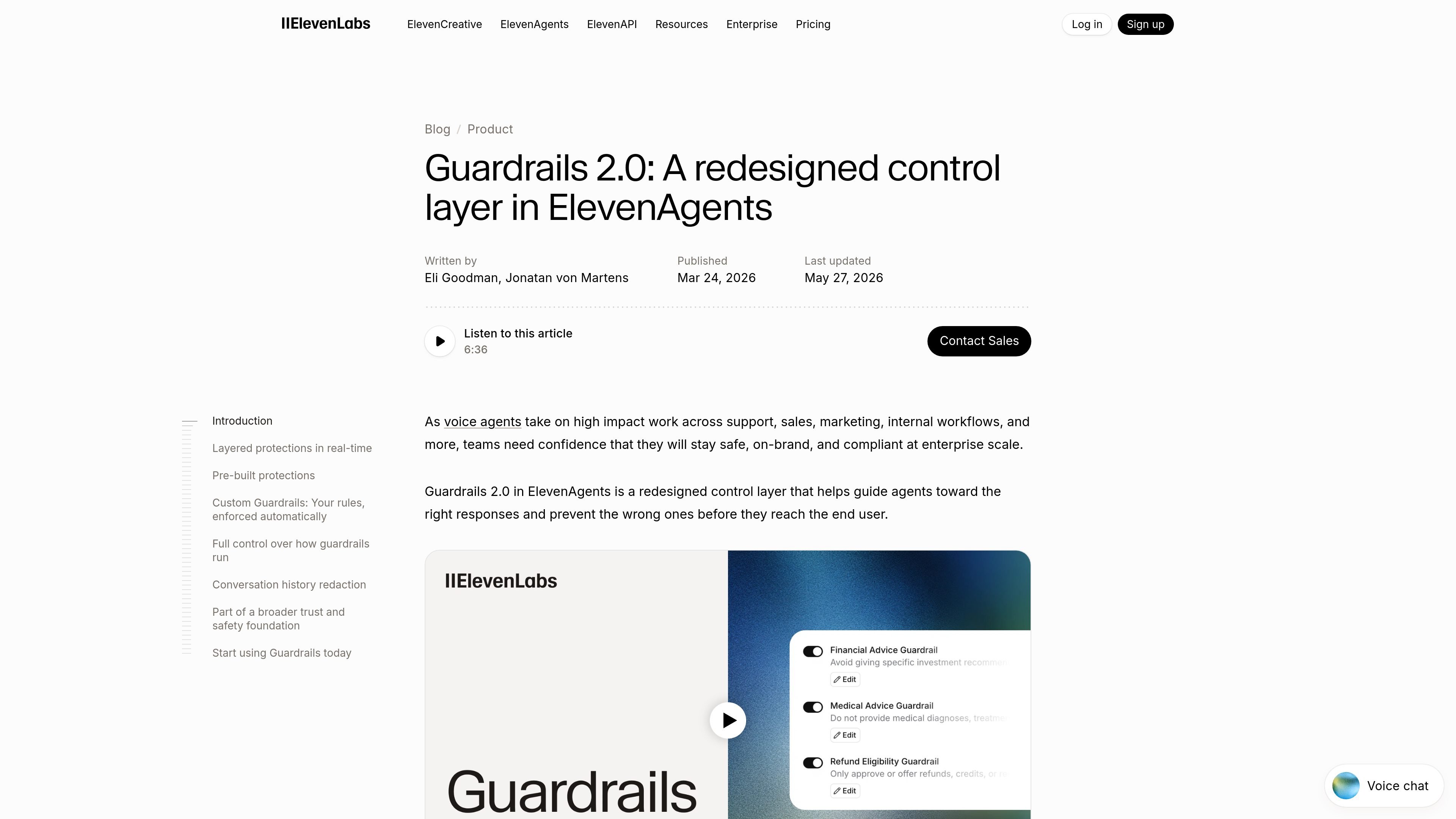
Guardrails 2.0 is ElevenLabs’ control layer for ElevenAgents, designed to keep AI voice agents on-topic, policy-aligned, and safer to deploy in production. It is built for teams using voice agents in support, sales, marketing, reception, and internal workflows.
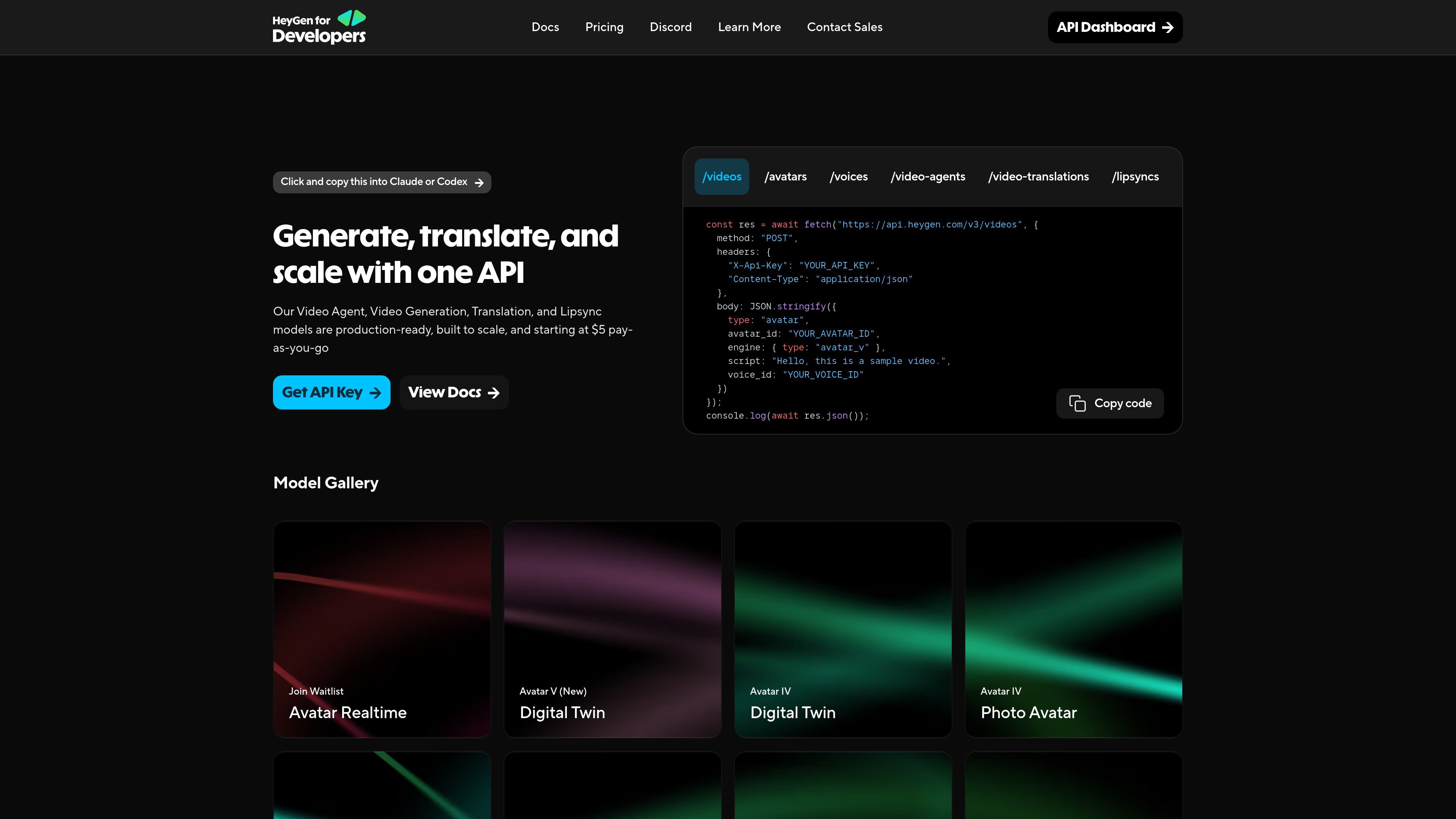
Official HeyGen API documentation for building AI avatar videos, translations, lipsync, and interactive video-agent sessions. It supports direct API use plus MCP and CLI-style workflows for developers and AI agents.
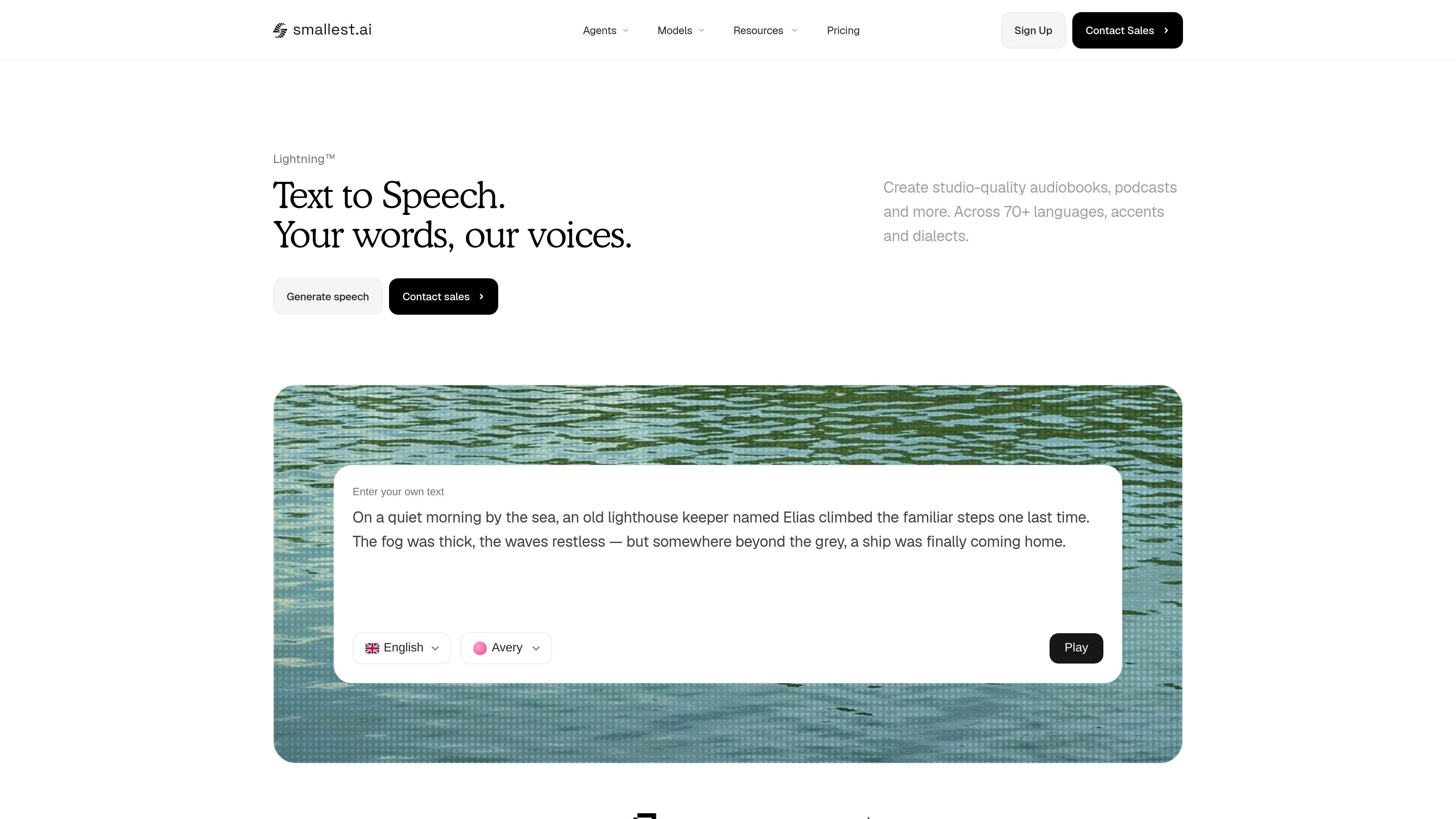
Smallest.ai Lightning TTS is a text-to-speech API for generating spoken audio from text with low latency, multilingual support, and fast voice cloning. It is aimed at developers and product teams building voice agents, narrated content, and other production speech workflows.

Voxtral TTS is Mistral’s text-to-speech model for generating lifelike, multilingual speech for voice agents and enterprise voice workflows. It supports short-reference voice adaptation, low-latency output, and access through Mistral Studio, Le Chat, the API, and open weights on Hugging Face.

Gemini 3.1 Flash Live is Google’s real-time audio and voice model for natural dialogue across developer, enterprise, and consumer surfaces. It is available in preview for developers through Google AI Studio and powers experiences in Gemini Live and Search Live.
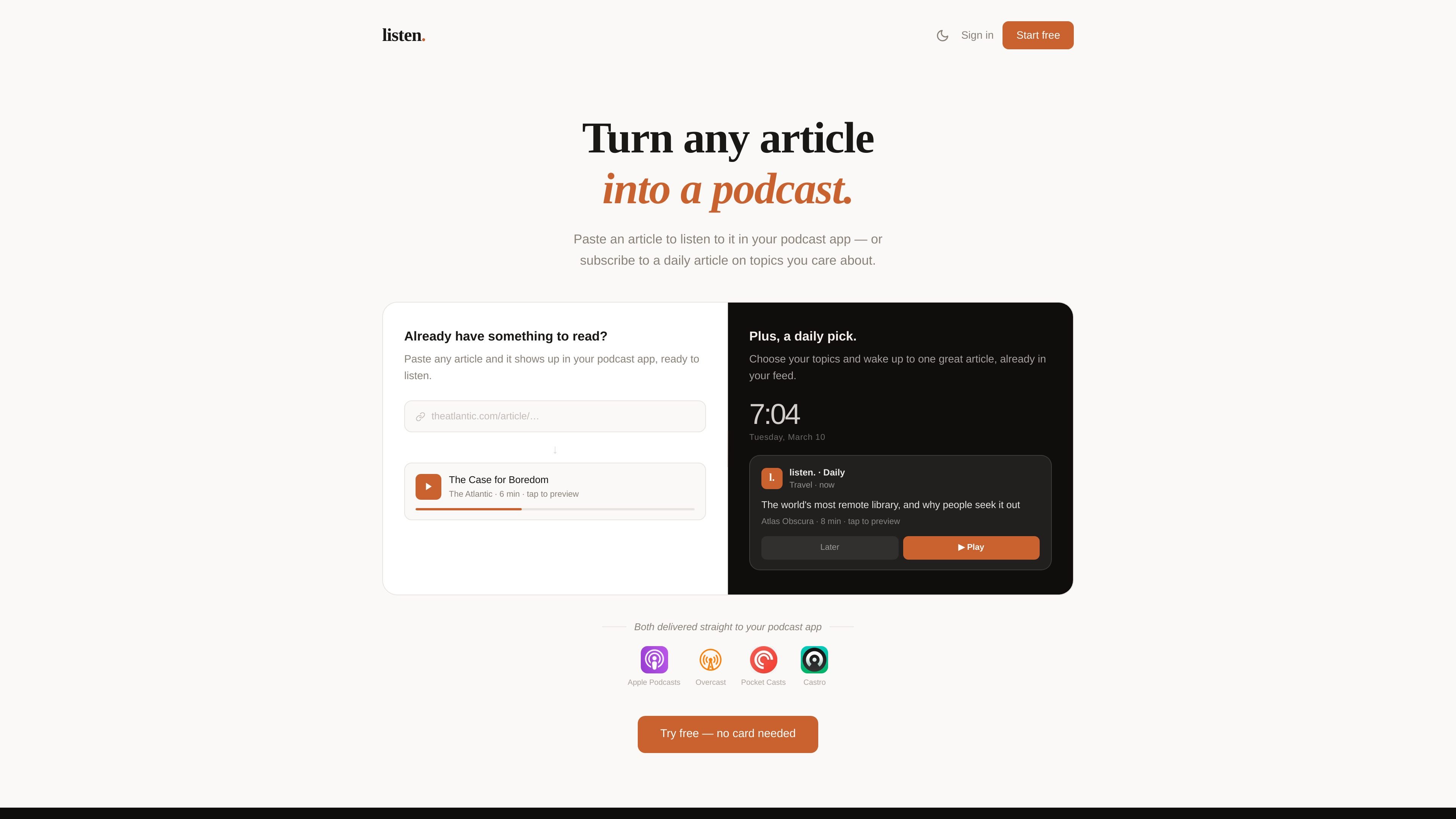
listen. turns article URLs, PDFs, or pasted text into audio that can be played in a podcast app. It also offers a daily article feed for chosen topics and a Chrome extension for faster capture while browsing.

Voizematic is an AI voice agent platform that automates inbound and outbound phone calls, appointment booking, and follow-up actions. It is designed for businesses that want to deploy phone agents without code and connect them to Google Workspace.
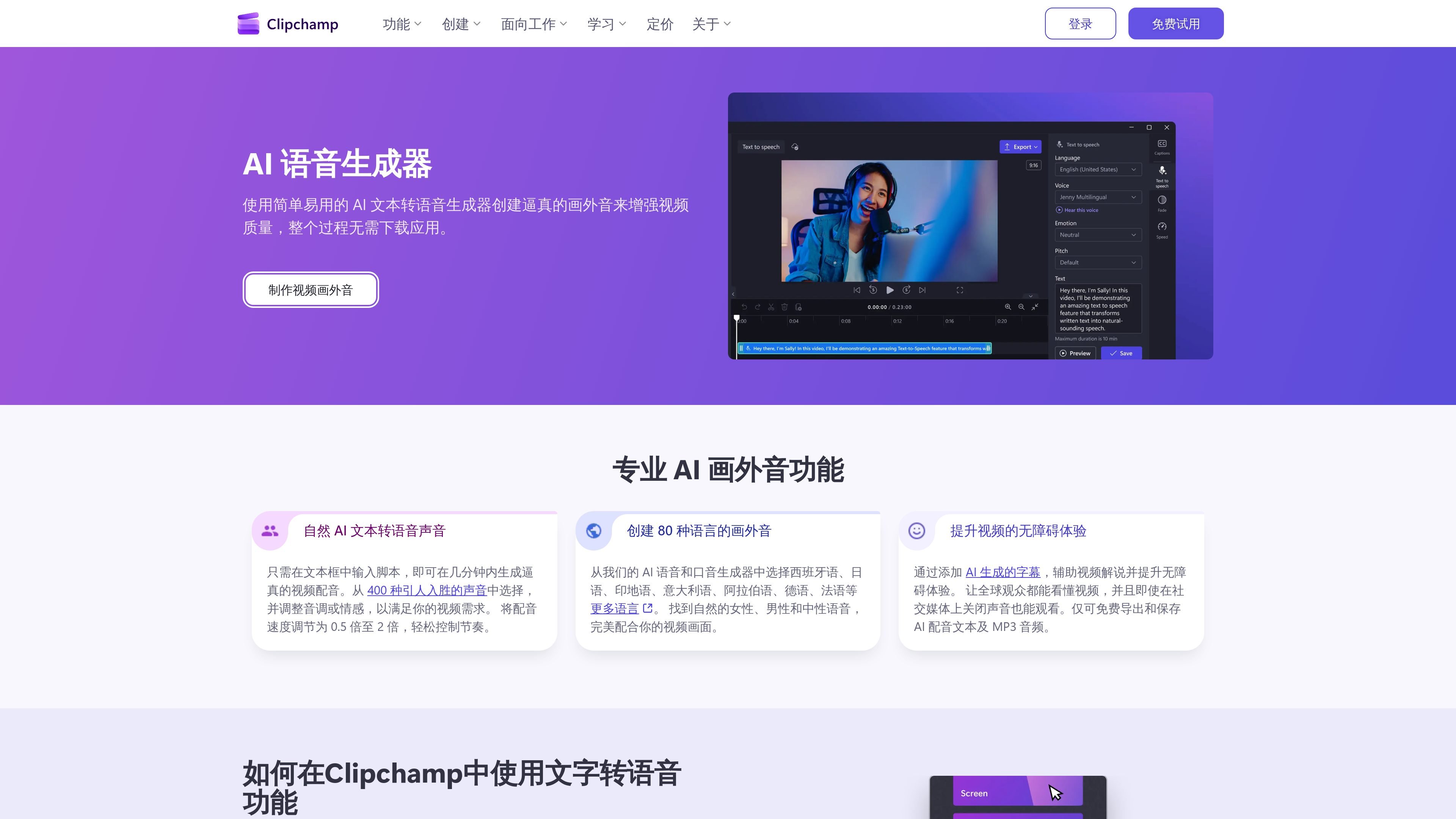
Clipchamp 的 AI 画外音生成器是一项在线文本转语音功能,可为视频生成旁白和配音。它支持多语言语音选择、语速与音色调整,并可直接在浏览器中使用。
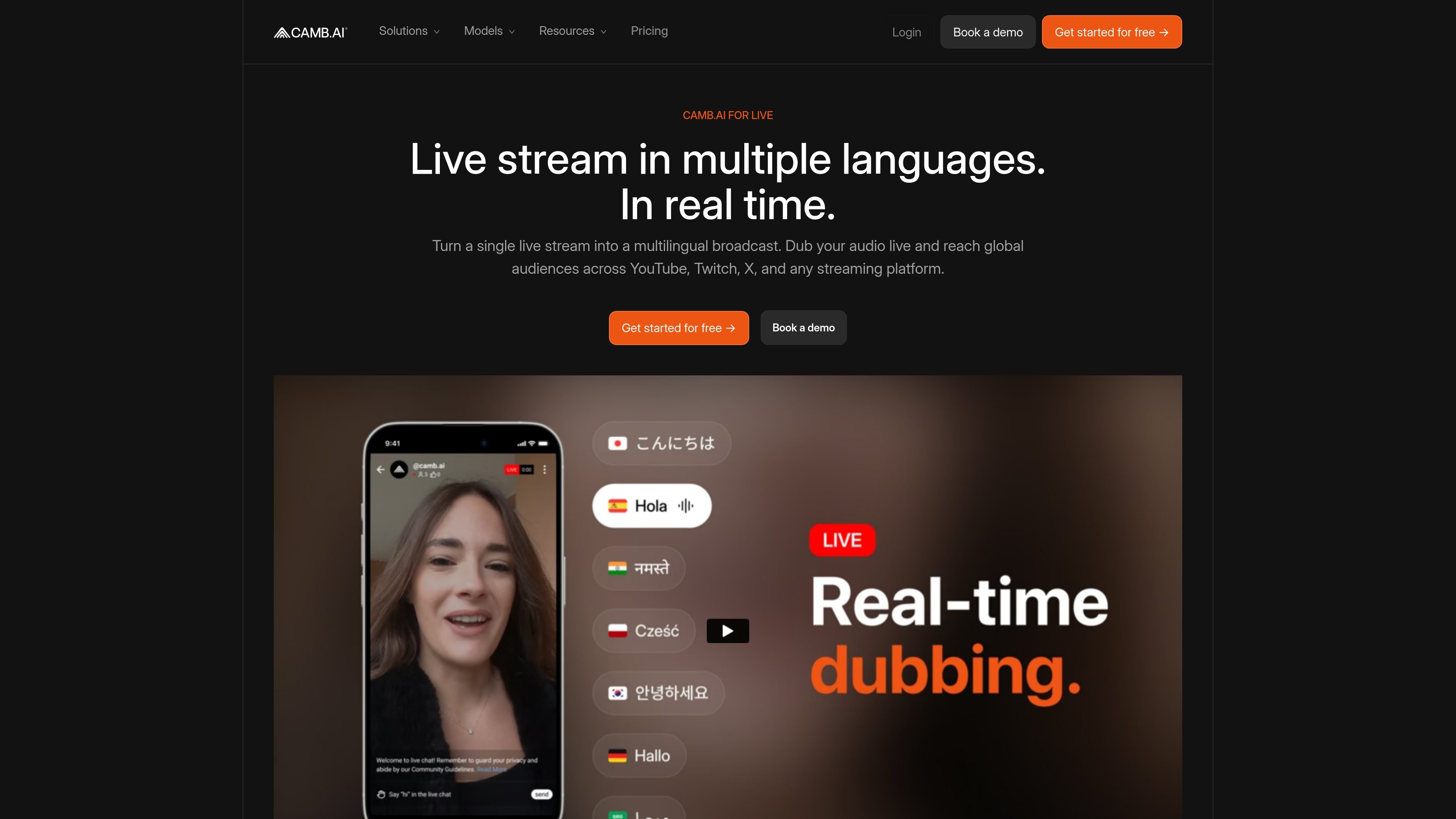
CAMB.AI Streams dubs live audio in multiple languages in real time for broadcasts on platforms like YouTube, Twitch, and X. It plugs into existing live workflows using common streaming protocols and avoids a post-production step.