Harbor
Harbor: CLI und Companion-App für lokale LLM-Stacks mit Modellen, Chat-Oberflächen und Diensten. Für KI-Workflows, Websuche, Sprache, Bilder und Coding.
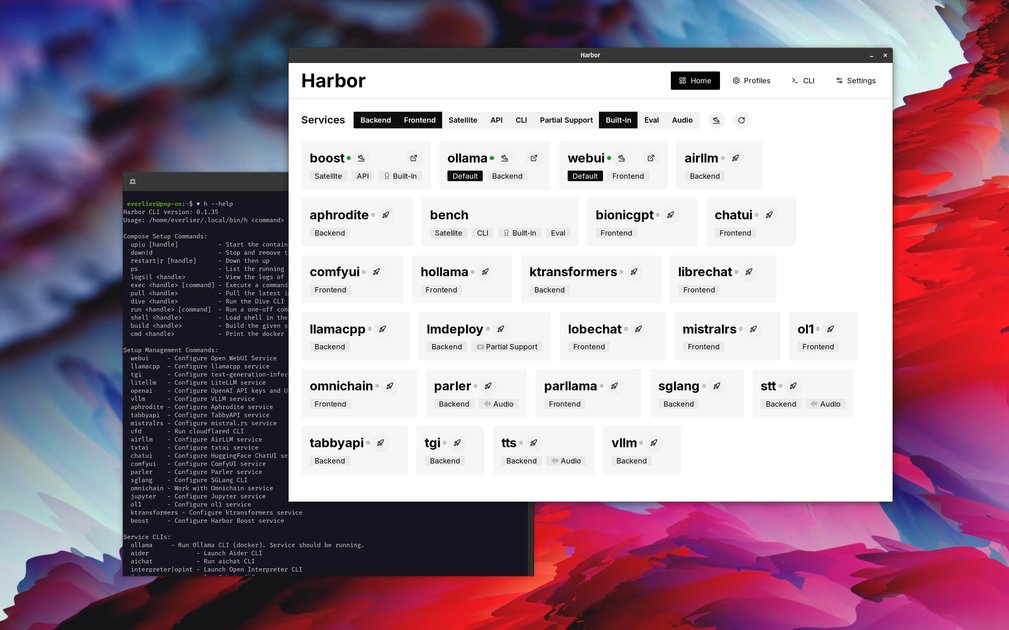
Was ist Harbor?
Harbor ist eine CLI und Companion-App zum Einrichten und Ausführen eines lokalen LLM-Stacks mit vorverdrahteten Diensten. Es soll den manuellen Aufwand für die Konfiguration von Modell-Backends, Frontends und unterstützenden Tools reduzieren, sodass Nutzer mit einem funktionsfähigen Stack über einen einzigen harbor up-Befehl starten können.
Das Projekt unterstützt lokale Modell-Backends wie Ollama, llama.cpp und vLLM und kann dazugehörige Dienste wie Open WebUI, SearXNG für die Websuche, Speaches für Sprachchat und ComfyUI für die Bildgenerierung starten. Harbor enthält außerdem Tools für Coding- und Agent-Workflows, bei denen harbor launch Host-Tools mit einem von Harbor verwalteten Backend und Modell verbinden kann, ohne Provider-Einstellungen manuell zu bearbeiten.
Wichtige Funktionen
- Stack-Start mit einem Befehl:
harbor upstartet ausgewählte Dienste mit bereits konfigurierter Docker-Compose-Orchestrierung und serviceübergreifender Verbindung. - Unterstützung mehrerer Modell-Backends: Harbor kann mit Backends wie Ollama, llama.cpp, vLLM und anderen in den Projektmaterialien genannten unterstützten Inference-Engines arbeiten.
- Vorgekoppelte Companion-Dienste: Frontends und Hilfsdienste wie Open WebUI, SearXNG, Speaches und ComfyUI sind so eingerichtet, dass sie zusammenarbeiten, statt separat konfiguriert zu werden.
- Integration für Coding-Agents:
harbor launchkann ein OpenAI-kompatibles Backend starten oder erkennen, ein Modell mit einer Host-CLI oder einem Editor verbinden und das Tool im aktuellen Projektverzeichnis laufen lassen. - Konfigurations- und Argumentverwaltung: Harbor kann Konfigurationen für Dienste und Host-Tools merken oder schreiben, einschließlich backend-spezifischer Argumente wie llama.cpp-Einstellungen.
- Companion-App und Dokumentation: Das Repository enthält eine App, CLI-Referenzmaterial, Installationsanleitungen, Dokumentation zum Servicekatalog und Anleitungen für lokale Workflows.
So verwenden Sie Harbor
Eine typische Einrichtung beginnt mit der Installation von Harbor über die Installationsanleitungen des Projekts und dem anschließenden Ausführen von harbor up mit den gewünschten Diensten. Danach können Sie die verbundenen Oberflächen wie Open WebUI öffnen oder bei Bedarf zusätzliche Dienste wie Websuche oder Sprachchat hinzufügen.
Für Coding-Workflows verwenden Sie harbor launch, um ein Backend und ein Modell auszuwählen, und starten dann ein unterstütztes Host-Tool wie einen CLI-Agenten oder Editor, während Harbor die Verbindungsdetails übernimmt. Die Dokumentation behandelt außerdem Dienstauswahl, Konfiguration und unterstützte Host-Tools.
Anwendungsfälle
- Lokales LLM-Experimentieren: Starten Sie ein Backend und eine Chat-Oberfläche gemeinsam, um Modelle lokal zu testen, ohne jede Komponente manuell zusammenzustellen.
- Web-fähige RAG-Workflows: Fügen Sie SearXNG und Open WebUI hinzu, damit ein lokaler Assistent im selben Umfeld das Web durchsuchen und gefundene Quellen nutzen kann.
- Sprachbasierte lokale Interaktion: Starten Sie Speaches zusammen mit dem restlichen Stack, wenn Sie in einem lokalen KI-Setup Speech-to-Text oder Text-to-Speech benötigen.
- Workflows zur Bildgenerierung: Integrieren Sie ComfyUI neben Modell-Backends, wenn Sie einen lokalen Stack brauchen, der Text- und Bildgenerierungsdienste abdeckt.
- Einrichtung für Coding-Agents: Verbinden Sie eine unterstützte Coding-CLI oder einen Editor mit einem von Harbor verwalteten Backend, damit das Tool ein KI-Modell ohne separate Konfiguration pro Tool nutzen kann.
FAQ
Benötigt Harbor für jeden Dienst manuelle Konfiguration?
Nein. Die Projektbeschreibung betont vorverdrahtete Dienste und eine Einrichtung mit einem einzigen Befehl, um den Stack online zu bringen.
Kann Harbor mit Coding-Tools und Agents verwendet werden?
Ja. In den Materialien wird harbor launch als Möglichkeit beschrieben, unterstützte Host-Tools mit einem Harbor-Backend und -Modell zu verbinden.
Welche Backends werden genannt?
Die Quelle nennt ausdrücklich Ollama, llama.cpp, vLLM, Docker Model Runner und MLX/OMLX im Kontext unterstützter Inference-Engines und macOS-Optionen.
Bietet Harbor nur Chat-Oberflächen?
Nein. Es verweist auch auf unterstützende Dienste für Websuche, Sprachchat, Bildgenerierung und Tools für Coding-Workflows.
Alternativen
- Manuelles Docker-Compose-Setup: Ähnlich im Ergebnis, erfordert aber, dass Sie die Dienste selbst zusammenstellen und verbinden, statt Harbors vorkonfigurierte Befehle zu nutzen.
- Lokale Single-Service-Model-Runner: Tools, die sich nur auf ein Backend wie einen Model-Server konzentrieren, können einfacher sein, wenn Sie keinen vollständigen Stack mit Frontends und Zusatzdiensten benötigen.
- Dedizierte Chat-Frontends: Anwendungen, die auf eine Web-UI für die Modellinteraktion ausgerichtet sind, passen, wenn Sie die Backend-Infrastruktur bereits haben.
- Allgemeine selbst gehostete KI-Stack-Vorlagen: Andere Stack-Vorlagen oder Starter-Kits decken möglicherweise Teile des Workflows ab, aber Harbor legt den Fokus auf CLI-gesteuerte Orchestrierung und dienstübergreifende Verbindung für lokale KI-Nutzung.
Alternativen
Ably Chat
Ably Chat ist eine Chat-API und SDKs für maßgeschneiderte Realtime-Chat-Apps: Reactions, Presence sowie Nachrichten editieren/löschen.
AakarDev AI
AakarDev AI ist eine leistungsstarke Plattform, die die Entwicklung von KI-Anwendungen mit nahtloser Integration von Vektordatenbanken vereinfacht und eine schnelle Bereitstellung und Skalierbarkeit ermöglicht.
BookAI.chat
BookAI ermöglicht es Ihnen, mit Ihren Büchern zu chatten, indem Sie einfach den Titel und den Autor angeben.
Grok AI Assistant
Grok ist ein kostenloser KI-Assistent, der von xAI entwickelt wurde und darauf ausgelegt ist, Wahrheit und Objektivität zu priorisieren, während er fortschrittliche Funktionen wie Echtzeit-Informationszugriff und Bilderzeugung bietet.
DeepMotion
DeepMotion ist eine AI-Motion-Capture- und Body-Tracking-Plattform für 3D-Animationen aus Video (und Text) im Browser – per Animate 3D API integrierbar.
skills-janitor
skills-janitor prüft, verfolgt die Nutzung und vergleicht deine Claude Code Skills mit neun Slash-Command-Aktionen – ohne Abhängigkeiten.