Nirixa
Nirixa ist ein Tool für AI-Observability und Cost Intelligence: trackt Tokens, Kosten, Latenz und Halluzinationsrisiko je LLM-Aufruf per SDK.
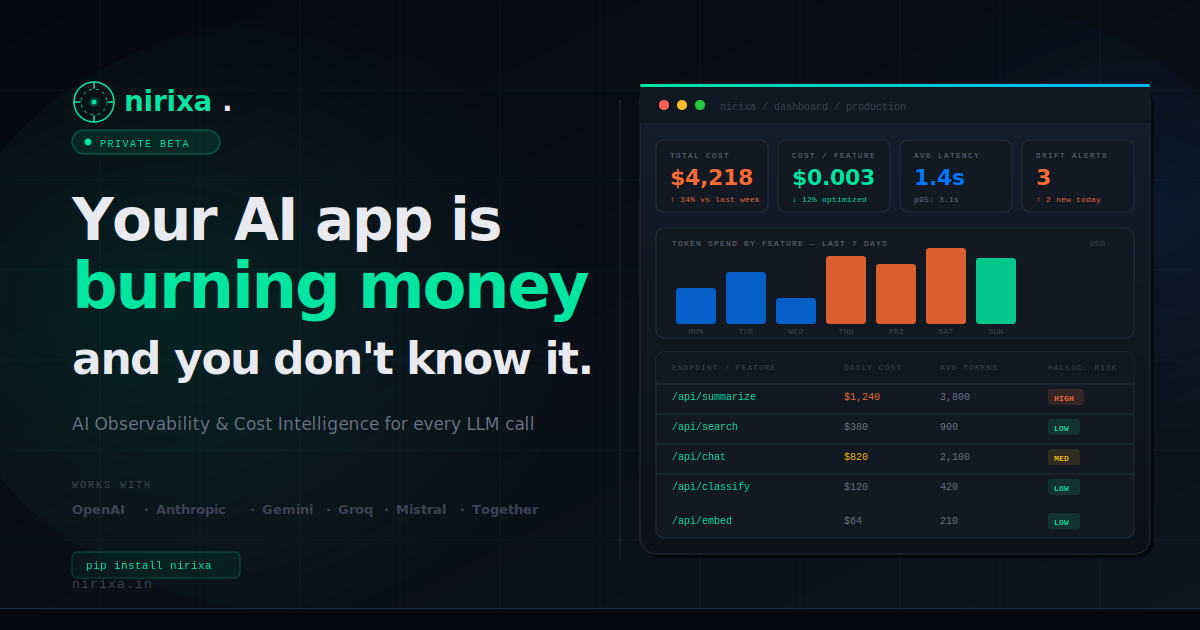
Was ist Nirixa?
Nirixa ist eine Lösung für AI-Observability und Cost Intelligence für Teams, die mit Large Language Models bauen. Sie hilft dabei, Tokens, Kosten und Latenz pro LLM-Aufruf zu tracken und zu verstehen sowie das Halluzinationsrisiko zu bewerten.
Der Kernzweck ist es, Entwicklern und Betreibern Sichtbarkeit in das Verhalten der Modellnutzung in der Produktion zu geben, um Performance zu überwachen und Ausgaben über LLM-Provider hinweg zu managen.
Wichtige Features
- Token- und Kosten-Tracking pro LLM-Aufruf: Protokolliert Token-Verbrauch und zugehörige Kosten, um Modellausgaben spezifischen Requests zuzuordnen.
- Latenz-Sichtbarkeit: Erfasst Zeitinformationen pro Aufruf, um Verlangsamungen und Performance-Muster zu identifizieren.
- Halluzinationsrisiko-Erkennung: Bietet eine Möglichkeit, die Wahrscheinlichkeit von Halluzinationen neben anderen Aufrufmetriken zu schätzen.
- Drop-in SDK für mehrere LLM-Provider: Unterstützt Integration mit OpenAI, Anthropic, Gemini und anderen Providern über einen SDK-Ansatz.
So nutzt du Nirixa
- Starte mit Nirixa und füge das bereitgestellte Drop-in-SDK in deine Anwendung ein, wo du LLM-Requests machst.
- Konfiguriere es, damit Requests für die unterstützten Provider automatisch erfasst werden.
- Nutze die Aufruf-Sichtbarkeit von Nirixa, um Tokens, Kosten, Latenz und Halluzinationsrisiko für deinen LLM-Traffic zu prüfen.
- Iteriere an Prompts oder Anwendungslogik basierend auf den beobachteten Aufrufmetriken und Risikosignalen.
Anwendungsfälle
- Produktions-LLM-Traffic überwachen: Tracke Tokens, Kosten und Latenz pro Request, um das Systemverhalten unter realer Nutzung zu verstehen.
- Ausgaben kontrollieren und untersuchen: Identifiziere, welche Workflows oder Endpoints den höchsten Token-Verbrauch und Kosten verursachen.
- Performance-Regressions diagnostizieren: Vergleiche Latenz-Muster über Requests hinweg, um langsame Modellaufrufe oder problematische Inputs zu finden.
- Unzuverlässige Outputs reduzieren: Nutze Halluzinationsrisiko-Schätzungen, um Fälle mit potenziell unzuverlässigen generierten Responses zu finden und Prompts oder Guardrails anzupassen.
- Multi-Provider-Verhalten validieren: Bei Nutzung von OpenAI, Anthropic, Gemini (und mehr) vergleiche Aufrufmetriken über Provider hinweg, um Unterschiede in Nutzungsmustern zu verstehen.
FAQ
Was misst Nirixa pro LLM-Request?
Nirixa fokussiert auf Token-Verbrauch, Kosten, Latenz und ein Halluzinationsrisiko-Signal für LLM-Aufrufe.
Welche Model-Provider unterstützt Nirixa?
Die Seite gibt an, dass Nirixa ein Drop-in-SDK für OpenAI, Anthropic, Gemini und mehr bereitstellt.
Muss ich meinen LLM-Code umschreiben, um Nirixa zu nutzen?
Die Site beschreibt Nirixa als „Drop-in SDK“, was bedeutet, dass du es ohne große Umschreibungen integrieren kannst, aber genaue Schritte hängen von deinem aktuellen LLM-Client und Aufruf ab.
Ist Nirixa nur für Observability oder auch für Cost Management?
Es ist als AI-Observability und Cost Intelligence positioniert und kombiniert Kosten-Tracking mit Performance- und Qualitäts-Signalen.
Alternativen
- Allgemeine Monitoring/Telemetry-Plattformen (APM/Logging): Geeignet für Service-Level-Metriken, bieten aber typischerweise keine LLM-spezifischen Aufrufdetails wie Tokens, Kosten und Halluzinationsrisiko out-of-the-box.
- LLM-Nutzungs-Dashboards in Orchestrierungs-Frameworks: Bieten Token-/Kosten-Sichtbarkeit innerhalb eines Frameworks, generalisieren aber nicht über Provider hinweg oder bieten die gleiche Halluzinationsrisiko-Perspektive.
- Model-Observability-Tools für Prompt/Response-Logging: Helfen Outputs zu debuggen und Generierungsverhalten zu überwachen, betonen aber oft Traceability statt Cost Intelligence oder standardisierter Aufrufmetriken über Provider hinweg.
Alternativen
BenchSpan
BenchSpan führt KI-Agent-Benchmarks parallel aus, erfasst Scores und Fehler in einer geordneten Run-Historie und macht Ergebnisse commit-gebunden reproduzierbar.
PromptScout
PromptScout trackt Markenerwähnungen, empfohlene Wettbewerber und zitierte Quellen in AI-Antworten (ChatGPT, Gemini, Google AI Overviews, Perplexity) inkl. Website-Audits.
Sleek Analytics
Leichtgewertige, datenschutzfreundliche Analytik mit Echtzeit-Visitor-Tracking: Woher Besucher kommen, was sie ansehen und wie lange sie bleiben.
MacSpoof
MacSpoof ist ein MAC-Adressenwechsler für macOS: WLAN-MAC ändern oder randomisieren, um Verbindungen zu erneuern und die Protokollierung auf öffentlichem WLAN zu reduzieren.
ClawTick
ClawTick ist eine CLI-first KI-Agenten-Automationsplattform für cronbasierte Webhook-Tasks mit Monitoring, Alerts, Retries und Ausführungslogs.
OpenFlags
OpenFlags ist ein Open-Source, self-hosted Feature-Flag-System für progressive Delivery: lokale Evaluation in App-SDKs und ein simples Control-Plane für gezielte Rollouts.