SemanticGuard
SemanticGuard ist ein AI-Gateway mit selbstvalidierendem Cache für LLM-APIs von OpenAI, Anthropic und Google. Für Entwickler zur Messung von Einsparungen und nahtlosem Request-Flow.
Was ist SemanticGuard?
SemanticGuard ist ein AI-Gateway und selbstvalidierender Cache für LLM-APIs. Es sitzt im Request-Pfad für Anbieter wie OpenAI, Anthropic und Google und cached Antworten, während es mit mehrstufiger Verifikation prüft, ob eine zwischengespeicherte Antwort noch korrekt ist.
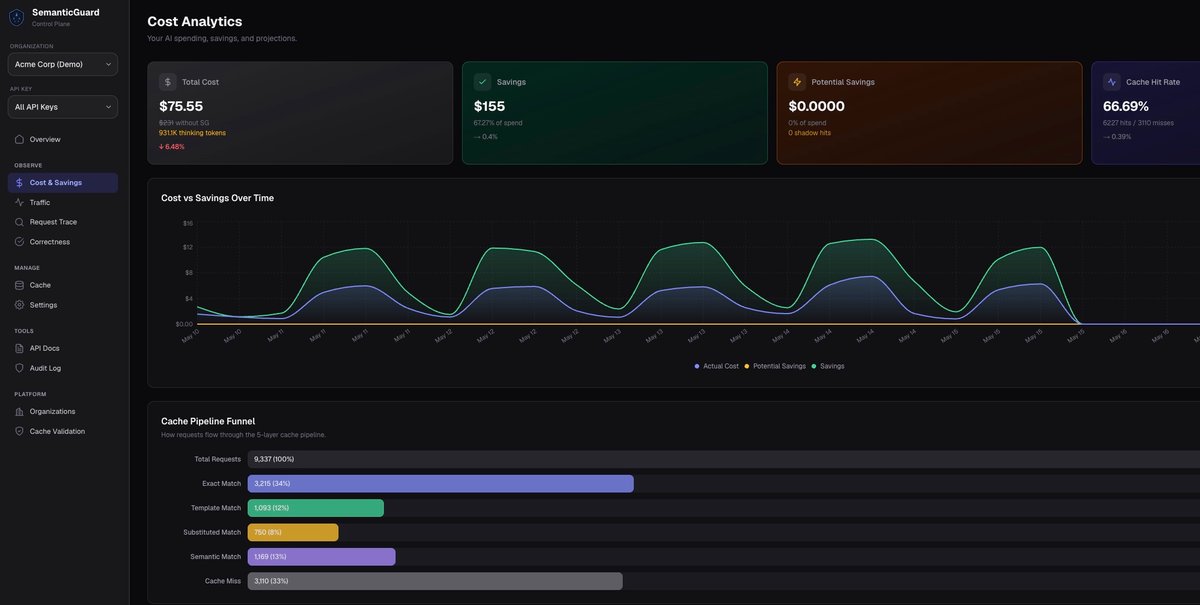
Das Produkt ist darauf ausgelegt, die Ausgaben für LLM-APIs zu senken, ohne Nutzer zu zwingen, Prompts zu ändern oder Cache-Objekte manuell zu verwalten. Es enthält außerdem einen Shadow Mode, der mögliche Einsparungen vor der Aktivierung des Cachings misst, und unterstützt ein Fail-Open-Design, sodass Requests an den Upstream-Anbieter weiterlaufen, wenn der Cache nicht verfügbar ist.
Hauptfunktionen
- SDK-Integration in einer Zeile über
fetch: withSemanticGuard()im AI SDK, damit Teams Caching hinzufügen können, ohne die Anwendungslogik neu zu schreiben. - Shadow-Mode-Messung, die pro Request Kosten, prognostizierte Einsparungen, Hit-Typen und zeigt, wo Traffic gecached würde, bevor gecachte Antworten ausgeliefert werden.
- Selbstvalidierende Cache-Treffer mit mehrstufiger Verifikation, wobei ausgewählte Treffer zusätzlich von KI auf Korrektheit bewertet und Fehler markiert werden.
- Anbieterübergreifende Unterstützung für OpenAI, Anthropic, Google und weitere gelistete Anbieter wie Azure, Bedrock und Mistral.
- Für semantische Treffer abgestimmtes Cache-Verhalten, sodass Requests mit unterschiedlichen Namen, Daten oder IDs dennoch treffen können, wenn die Antwort faktisch dieselbe ist.
- Fail-Open-Request-Handling, das Traffic direkt an den Anbieter sendet, wenn der Cache ausfällt.
- Auf der Website genannte Sicherheitskontrollen, darunter Verschlüsselung während der Übertragung und im Ruhezustand, optionale Prompt-Speicherung und Weitergabe von Upstream-API-Keys zum Zeitpunkt der Anfrage statt Speicherung.
So verwendest du SemanticGuard
Entwickler fügen SemanticGuard zu ihrer AI-SDK-Konfiguration hinzu, indem sie die Fetch-Schicht mit withSemanticGuard() umschließen und dann Requests wie gewohnt senden. Der auf der Website gezeigte Workflow beginnt mit Shadow Mode, um Einsparungen zu messen und zu beobachten, wie Traffic klassifiziert würde.
Wenn das Team mit den Ergebnissen zufrieden ist, kann Caching aktiviert werden. Ab diesem Zeitpunkt werden Cache-Treffer automatisch zurückgegeben, und im Dashboard lassen sich Einsparungen, Trefferquote und Validierungsergebnisse prüfen.
Anwendungsfälle
- Senkung der Kosten bei LLM-Anwendungen mit hohem Volumen, in denen viele Nutzer ähnliche Fragen stellen und wiederholte Antworten wiederverwendet werden können.
- Messen der Wirtschaftlichkeit von Caching vor dem Rollout, besonders für Teams, die Einsparungen quantifizieren möchten, ohne sofort gecachte Ausgaben zu liefern.
- Bereitstellen semantisch ähnlicher Requests, die sich in Oberflächendetails wie Namen, Daten oder IDs unterscheiden, bei denen byteidentisches Provider-Caching nicht greifen würde.
- Unterstützung von Multi-Provider-AI-Stacks, die eine einheitliche Caching-Schicht über verschiedene Modellanbieter hinweg benötigen.
- Sicherstellung der Verfügbarkeit für Produktions-Apps, die einen Fallback-Pfad brauchen, falls die Caching-Schicht nicht verfügbar ist.
FAQ
Benötigt SemanticGuard Prompt-Änderungen?
Nein. Auf der Website wird eine SDK-Integration in einer Zeile beschrieben, und es heißt, dass keine Prompt-Änderungen nötig sind.
Kann ich Einsparungen testen, bevor ich Cache-Treffer aktiviere?
Ja. SemanticGuard enthält Shadow Mode, der misst, was du sparen würdest, bevor gecachte Antworten ausgeliefert werden.
Funktioniert es mit mehr als einem Modellanbieter?
Ja. Die Seite nennt OpenAI, Anthropic und Google und erwähnt außerdem Kompatibilität mit weiteren Anbietern wie Azure, Bedrock und Mistral.
Was passiert, wenn der Cache nicht verfügbar ist?
Das Produkt wird als fail-open beschrieben, das heißt, Requests gehen direkt an den Anbieter.
Ist das Produkt nur für Exact-Match-Caching gedacht?
Nein. Die Seite positioniert SemanticGuard als semantisches Caching für Requests, die dasselbe bedeuten, auch wenn sich Details wie Namen, Daten oder IDs ändern.
Alternativen
- Provider-natives Prompt-Caching, etwa integriertes Caching von OpenAI oder ähnlichen Anbietern. Das ist typischerweise auf exakte oder nahezu exakte Prefix-Wiederverwendung innerhalb des Systems eines Anbieters beschränkt und eignet sich besser für statische Prompt-Segmente.
- Manuelle Cache-Schichten in einer Anwendung oder einem Proxy. Diese lassen sich anpassen, erfordern aber meist mehr Entwicklungsaufwand für Cache-Keys, Invalidierung und Korrektheitsprüfung.
- Allgemeine AI-Gateways ohne semantische Validierung. Sie können Routing, Observability oder Policy-Durchsetzung übernehmen, fokussieren aber nicht zwingend auf Caching mit Korrektheitsprüfungen.
- Direkte Nutzung des Anbieters ohne Caching-Schicht. Das ist das einfachste Setup, bietet aber weder Wiederverwendung über ähnliche Requests hinweg noch einen Workflow zur Einsparungsmessung vor dem Start.
Alternativen
AakarDev AI
AakarDev AI ist eine leistungsstarke Plattform, die die Entwicklung von KI-Anwendungen mit nahtloser Integration von Vektordatenbanken vereinfacht und eine schnelle Bereitstellung und Skalierbarkeit ermöglicht.
Ably Chat
Ably Chat ist eine Chat-API und SDKs für maßgeschneiderte Realtime-Chat-Apps: Reactions, Presence sowie Nachrichten editieren/löschen.
BookAI.chat
BookAI ermöglicht es Ihnen, mit Ihren Büchern zu chatten, indem Sie einfach den Titel und den Autor angeben.
DeepMotion
DeepMotion ist eine AI-Motion-Capture- und Body-Tracking-Plattform für 3D-Animationen aus Video (und Text) im Browser – per Animate 3D API integrierbar.
skills-janitor
skills-janitor prüft, verfolgt die Nutzung und vergleicht deine Claude Code Skills mit neun Slash-Command-Aktionen – ohne Abhängigkeiten.
Arduino VENTUNO Q
Arduino VENTUNO Q ist ein Edge-AI-Computer für Robotik und physische Systeme: KI-Inferenz mit Microcontroller für deterministische Steuerung. Entwickeln in Arduino App Lab.