Cube
Cube is an agentic analytics platform designed to serve as a semantic layer foundation, enabling consistent, secure, and performant data access for BI, embedded analytics, and LLM/AI applications.
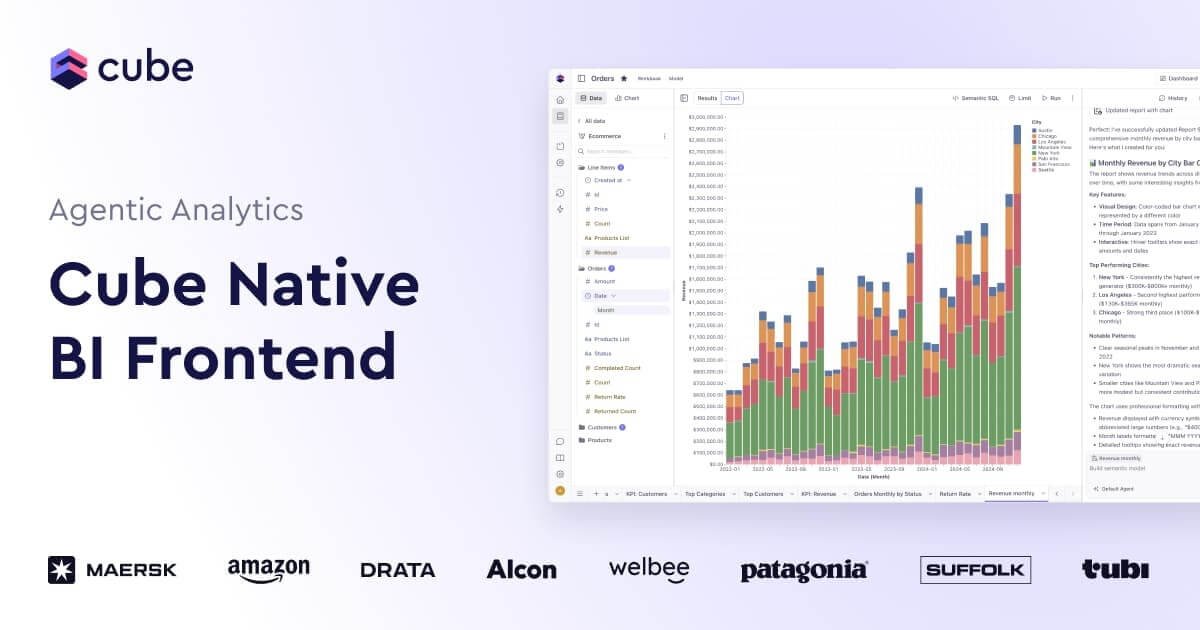
What is Cube?
What is Cube?
Cube is an advanced, agentic analytics platform that establishes a unified semantic layer across your entire data ecosystem. Its core mission is to eliminate data fragmentation and inconsistency by allowing organizations to define core business metrics and calculation logic once. This single source of truth ensures that every downstream tool—from traditional BI dashboards to cutting-edge AI agents—consumes data based on the exact same definitions, drastically reducing discrepancies and improving data governance, as highlighted by users like Alcon who saw significant efficiency gains in metric definition.
This platform bridges the gap between the modern data stack (like data warehouses and lakes) and the consumption layer, offering enterprise-grade tools for security, performance tuning, and real-time data handling. By providing a robust, API-first foundation, Cube empowers developers and analysts to build sophisticated data experiences, including high-performance embedded analytics and context-aware LLM applications, ensuring data is not just available, but trustworthy and actionable across the organization.
Key Features
- Agentic Analytics Platform: Supports next-generation data workflows by integrating deeply with AI and multi-agent systems, allowing for dynamic data interpretation and enhanced responsiveness.
- Semantic Layer Foundation: Define metrics, dimensions, and relationships centrally. This ensures consistency across all consumption points, preventing the need for redundant query writing (e.g., Alcon's experience).
- Embedded Analytics: Offers tools to build secure, consistent, and highly performant embedded dashboards and visualizations directly into applications.
- Real-time Analytics Support: Designed with a stack optimized for speed and consistency, allowing trust in data that is fresh and up-to-the-second.
- LLM & AI Context Layer: Provides the necessary structured context and pre-calculated metrics to power accurate and relevant responses from AI chatbots and Large Language Models.
- Performance Optimization: Features like caching, pre-aggregation management, and query rewriting ensure low-latency responses, leading to significant decreases in analytics downtime (e.g., Cloud Academy reported a 90% decrease).
- Cloud OLAP Bridging: Acts as a vital intermediary, connecting the raw power of modern cloud data warehouses (OLAP) with user-friendly interfaces like spreadsheets and BI tools.
How to Use Cube
Getting started with Cube involves establishing your semantic model and connecting your data sources. The typical workflow centers around defining your data schema within Cube's modeling language. First, connect Cube to your underlying data warehouse (e.g., Snowflake, BigQuery). Second, define your core metrics, dimensions, and relationships in the Cube schema files, establishing the single source of truth.
Once the model is defined, you can expose this data through various APIs, including SQL API for traditional BI tools, REST/GraphQL for custom applications, or directly integrate it into your LLM pipelines. Users benefit from rapid iteration; for instance, Cloud Academy achieved a 5x speedup in releasing new data models due to Cube's streamlined deployment process. The platform handles query compilation, optimization, and caching automatically, meaning end-users interact with consistent, fast results regardless of the tool they use.
Use Cases
- Enterprise BI Standardization: Large organizations use Cube to enforce consistent definitions for KPIs (like Monthly Recurring Revenue or Customer Acquisition Cost) across dozens of disparate BI tools (Tableau, Power BI, Looker), ensuring executive reporting is unified and trustworthy.
- Contextualizing AI Agents: Integrating Cube as the data layer for internal AI assistants. When an employee asks an LLM-powered bot a data question, Cube translates the natural language query into an optimized, context-aware query against the data warehouse, ensuring the AI response is factually grounded in the defined metrics.
- Building Customer-Facing Analytics: Companies leverage Cube's embedded analytics capabilities to securely deliver tailored, high-performance dashboards to their end customers within their own SaaS applications, managing permissions and performance at scale.
- Modernizing Legacy Reporting: Organizations migrating from older data stacks use Cube to rapidly expose their new cloud data warehouse data through familiar interfaces, accelerating time-to-value for new infrastructure investments while maintaining backward compatibility for critical reports.
- Real-time Operational Dashboards: For use cases requiring immediate feedback (e.g., monitoring live transaction flows or system health), Cube's real-time capabilities ensure that operational dashboards reflect the absolute latest state of the data without sacrificing consistency.
FAQ
Q: What data sources does Cube natively support? A: Cube is designed to connect to virtually any modern data warehouse or database, including Snowflake, BigQuery, Databricks, PostgreSQL, MySQL, and various cloud OLAP systems. It acts as the abstraction layer above these sources.
Q: How does Cube improve AI/LLM performance? A: Cube provides structured context. Instead of feeding raw data to an LLM, Cube translates user intent into optimized queries based on pre-defined metrics. This reduces hallucination, ensures accuracy, and significantly speeds up the response time by querying aggregated or pre-calculated views when appropriate.
Q: Is Cube primarily a visualization tool or a data modeling tool? A: Cube is fundamentally a semantic layer and analytics API platform. It focuses on defining what the data means and how it should be queried consistently. While it supports embedded analytics, it is tool-agnostic and designed to power visualization tools, not replace them.
Q: How does Cube handle security and access control? A: Security is managed centrally within the Cube layer. You can define granular access controls, row-level security (RLS), and column-level security based on user roles or context passed through the API, ensuring that data consumers only see what they are authorized to access, regardless of the downstream tool used.
Q: What is the difference between Cube and a traditional BI tool's modeling layer? A: Traditional BI tools create siloed models specific to that tool. Cube creates a universal semantic layer that serves all tools (BI, custom apps, AI). This centralization prevents metric drift and ensures that the definition of a metric is consistent whether viewed in Tableau or queried by an internal AI agent.
Alternatives
BookAI.chat
BookAI allows you to chat with your books using AI by simply providing the title and author.
Falconer
Falconer is a self-updating knowledge platform designed to serve as the single source of truth for teams, ensuring documentation and tribal knowledge remain accurate and easily accessible.
AakarDev AI
AakarDev AI is a powerful platform that simplifies the development of AI applications with seamless vector database integration, enabling rapid deployment and scalability.
EchoTik
EchoTik is a TikTok e-commerce data analysis platform designed to assist sellers and e-commerce creators in making data-driven decisions for product selection and market analysis.
BeFreed
BeFreed is a personalized audio learning platform that transforms knowledge into engaging audio content tailored for individual learning preferences.
紫东太初
A new generation multimodal large model launched by the Institute of Automation, Chinese Academy of Sciences and the Wuhan Artificial Intelligence Research Institute, supporting multi-turn Q&A, text creation, image generation, and comprehensive Q&A tasks.