Long-horizon reasoning and execution
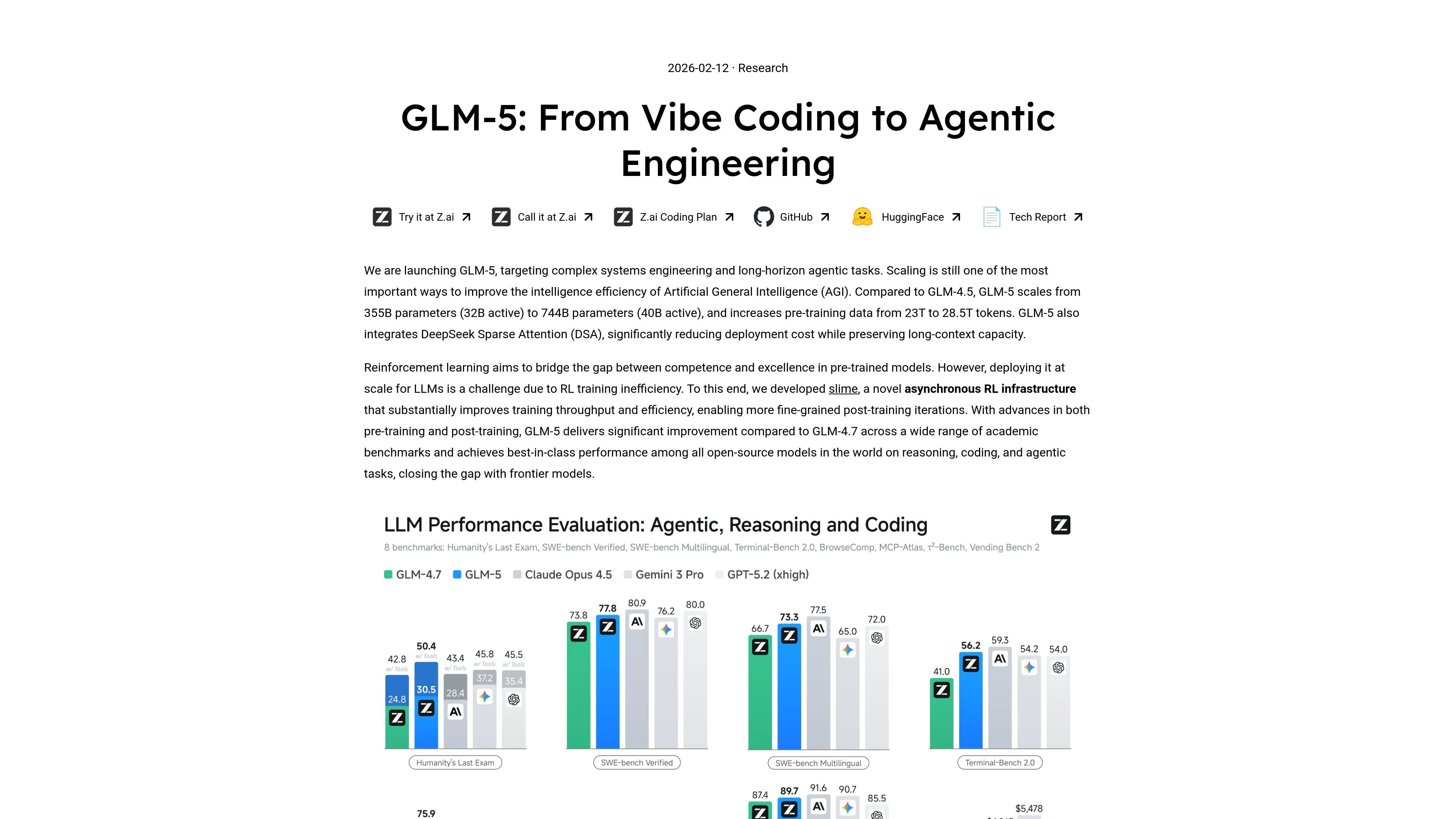
The launch post says GLM-5 targets complex systems engineering and long-horizon agentic tasks, with improvements in reasoning, coding and agent performance over GLM-4.7.
GLM-5 is Z.ai’s flagship reasoning and coding model family for complex systems engineering, long-horizon agentic tasks, and document generation. It is available through Z.ai, developer APIs, and open-source releases, with a separate coding plan for IDE and agent workflows.
GLM-5 is Z.ai’s flagship reasoning and coding model family, positioned for complex systems engineering and long-horizon agentic work. The launch page says it builds on GLM-4.7 with a larger model scale, more pre-training data, and improved post-training, and it is also presented as the basis for Z.ai’s coding plan and developer platform access.
In the published materials, GLM-5 is described as useful both for technical execution and for producing finished deliverables. Z.ai says the model can handle reasoning, coding, agent tasks, and document generation, and that it can turn source material directly into .docx, .pdf, and .xlsx outputs for workflows such as PRDs, spreadsheets, reports, lesson plans, and other office documents.
The launch post says GLM-5 targets complex systems engineering and long-horizon agentic tasks, with improvements in reasoning, coding and agent performance over GLM-4.7.
GLM-5 is described as able to turn text or source materials directly into .docx, .pdf and .xlsx files, including PRDs, lesson plans, exams, spreadsheets, financial reports and run sheets.
The model uses DeepSeek Sparse Attention to reduce deployment cost while keeping long-context capacity, which is relevant for larger codebases and multi-step workflows.
The post says Z.ai developed an asynchronous RL infrastructure called slime to improve training throughput and support more fine-grained post-training iterations.
The product pages mention compatibility with Claude Code and OpenClaw, and the coding plan says GLM models can be used in 20+ AI coding tools and IDE workflows.
Use GLM-5 for larger software tasks that require sustained context, multi-step reasoning, and back-and-forth execution across a longer workflow.
Use it when you need agent behavior for tasks such as exploring, planning, and completing longer-horizon operations rather than single-turn answers.
Use it to generate structured deliverables from source material, including reports, spreadsheets, proposals, and other office files.
Use it through the coding plan or supported tools when working in IDE-based coding assistants and other agent environments.
Use the open-source release and API access when you want to evaluate, integrate, or self-host model weights in a development workflow.
GLM-5 is available through Z.ai’s consumer chat experience, the developer platform api.z.ai and BigModel.cn, and it is also released as open source on Hugging Face and ModelScope under the MIT License. The launch page also notes compatibility with Claude Code and OpenClaw.
The source describes GLM-5 as designed for complex systems engineering, long-horizon agentic tasks, reasoning, coding, and document generation. The model page also says GLM-5.1 supports long-horizon tasks and closed-loop engineering-grade deliverables.
Z.ai’s coding subscription is presented as a separate plan for AI coding workflows. The plan page says it supports 20+ popular coding tools and is organized into Lite, Pro, and Max tiers starting from $18/month on the displayed billing options, with lower effective rates shown for quarterly and yearly billing.
The launch materials say GLM-5 can generate .docx, .pdf and .xlsx outputs from text or source materials, and Z.ai’s Agent mode adds built-in skills for PDF, Word and Excel creation. The page frames these as end-to-end deliverables rather than raw text-only responses.
The source highlights Claude Code and OpenClaw compatibility, and the coding plan page mentions support for 20+ tools. Beyond that, the provided pages do not list a complete integration matrix or exact setup requirements for every supported tool.
ByteAsk is a terminal-first AI coding agent for C and C++ that edits repositories and verifies changes with the real compiler, debugger, sanitizers, and tests before showing a diff. It offers a free tier plus paid plans, with editor connectors and zero-retention handling described in the source.
Une plateforme IA tout-en-un qui combine des outils pour l'image, la vidéo, la voix, l'écriture et le chat afin d'améliorer la créativité et la collaboration.
Slidesgo is a presentation template platform for Google Slides, PowerPoint, and selected Canva workflows. It offers free and Premium templates, plus AI-assisted presentation creation and team-friendly access options.
Wysera is an AI business platform that combines PostWyse for content and OpsWyse for CRM and revenue workflows, powered by the shared Wyse AI. It is built for solo operators, teams, and agencies that want approval-first automation across publishing, lead follow-up, and related operations.
Grok est un assistant IA gratuit développé par xAI, conçu pour privilégier la vérité et l'objectivité tout en offrant des capacités avancées telles que l'accès à l'information en temps réel et la génération d'images.
Ghost est un assistant IA en terminal pour discuter, générer du code et lancer des tâches en ligne de commande. Modèles gratuits, Linux, macOS, Windows, open source.