Nirixa
Nirixa suit chaque appel LLM : tokens, coût, latence et risque d’hallucination via un SDK intégré pour OpenAI, Anthropic et Gemini.
Qu'est-ce que Nirixa ?
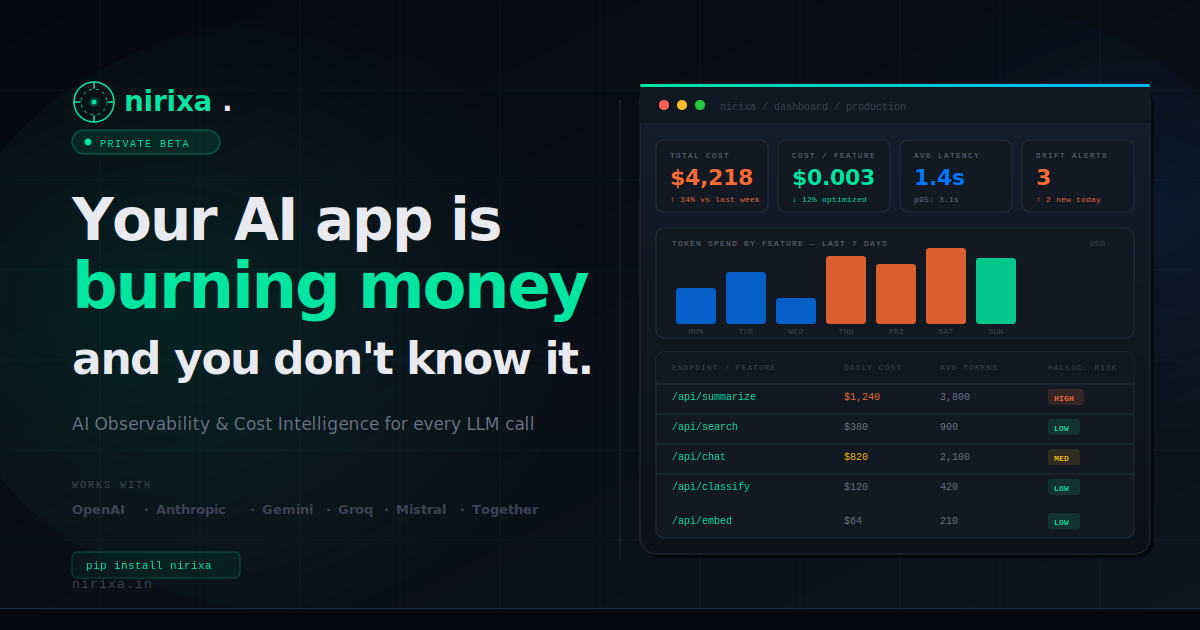
Nirixa est une solution d'observabilité IA et d'intelligence des coûts pour les équipes qui développent avec des grands modèles de langage. Elle est conçue pour vous aider à suivre et comprendre les tokens, le coût et la latence de chaque appel LLM, et à évaluer le risque d'hallucination.
L'objectif principal est de donner aux développeurs et opérateurs une visibilité sur le comportement de l'utilisation des modèles en production, afin qu'ils puissent surveiller les performances et gérer les dépenses sur l'ensemble des fournisseurs LLM.
Fonctionnalités clés
- Suivi des tokens et des coûts par appel LLM : enregistre l'utilisation des tokens et le coût associé pour attribuer les dépenses aux requêtes spécifiques.
- Visibilité sur la latence : capture les informations de temporisation pour chaque appel afin d'identifier les ralentissements et les schémas de performance.
- Détection du risque d'hallucination : fournit un moyen d'estimer la probabilité d'hallucination en complément des autres métriques d'appel.
- SDK intégré pour plusieurs fournisseurs LLM : prend en charge l'intégration avec OpenAI, Anthropic, Gemini et d'autres fournisseurs via une approche SDK.
Comment utiliser Nirixa
- Commencez avec Nirixa et ajoutez le SDK intégré fourni à votre application là où vous effectuez des requêtes LLM.
- Configurez-le pour que les requêtes soient capturées automatiquement pour les fournisseurs pris en charge.
- Utilisez la visibilité au niveau des appels de Nirixa pour examiner les tokens, le coût, la latence et le risque d'hallucination de votre trafic LLM.
- Itérez sur les prompts ou la logique applicative en fonction des métriques d'appel et des signaux de risque observés.
Cas d'usage
- Surveiller le trafic LLM en production : suivez les tokens, le coût et la latence par requête pour comprendre le comportement du système en usage réel.
- Contrôler et analyser les dépenses : identifiez les workflows ou endpoints qui génèrent la plus forte utilisation de tokens et de coûts.
- Diagnostiquer les régressions de performance : comparez les schémas de latence entre les requêtes pour repérer les appels lents ou les entrées problématiques.
- Réduire les sorties peu fiables : utilisez les estimations du risque d'hallucination pour trouver les cas où les réponses générées peuvent être moins fiables, et ajustez les prompts ou garde-fous en conséquence.
- Valider le comportement multi-fournisseurs : avec OpenAI, Anthropic, Gemini (et plus), comparez les métriques au niveau des appels entre fournisseurs pour comprendre les différences de schémas d'utilisation.
FAQ
Que mesure Nirixa pour chaque requête LLM ?
Nirixa se concentre sur l'utilisation des tokens, le coût, la latence et un signal de risque d'hallucination pour les appels LLM.
Quels fournisseurs de modèles Nirixa prend-il en charge ?
La page indique que Nirixa fournit un SDK intégré pour OpenAI, Anthropic, Gemini, et plus.
Dois-je réécrire mon code LLM pour utiliser Nirixa ?
Le site décrit Nirixa comme un « SDK intégré », ce qui implique une intégration sans réécriture majeure, mais les étapes exactes dépendent de votre client LLM actuel et de la façon dont vous l'appelez.
Nirixa est-il seulement pour l'observabilité ou aussi pour la gestion des coûts ?
Il est positionné comme observabilité IA et intelligence des coûts, combinant suivi des coûts avec des signaux de performance et de qualité.
Alternatives
- Plateformes de monitoring/télémétrie générales (APM/logging) : adaptées au suivi des métriques au niveau service, mais elles ne fournissent généralement pas de détails spécifiques aux appels LLM comme les tokens, le coût et le risque d'hallucination nativement.
- Tableaux de bord d'utilisation LLM intégrés aux frameworks d'orchestration : peuvent offrir une visibilité sur les tokens/coûts dans un framework spécifique, mais ne généralisent pas forcément entre fournisseurs ou n'offrent pas la même perspective sur le risque d'hallucination.
- Outils d'observabilité de modèles axés sur la journalisation des prompts/réponses : aident au débogage des sorties et à la surveillance du comportement de génération, mais mettent l'accent sur la traçabilité plutôt que sur l'intelligence des coûts ou les métriques standardisées au niveau des appels entre fournisseurs.
Alternatives
BenchSpan
BenchSpan exécute des benchmarks d’agents IA en parallèle, consigne scores et échecs dans un historique, et facilite la reproductibilité via des exécutions taguées par commit.
PromptScout
PromptScout suit les mentions de votre marque, les concurrents recommandés et les sources citées dans ChatGPT, Gemini, Google AI Overviews et Perplexity.
Sleek Analytics
Sleek Analytics : analytics légères et respectueuses de la vie privée, avec suivi en temps réel des visiteurs. Provenance, pages consultées et durée.
MacSpoof
MacSpoof change ou randomise l’adresse MAC Wi‑Fi sur macOS pour reconnecter aux réseaux et limiter l’enregistrement de votre identité sur Wi‑Fi public.
ClawTick
ClawTick est une plateforme d’automatisation d’agents IA via CLI pour planifier des tâches webhooks en cron avec monitoring, alertes, retries et logs.
OpenFlags
OpenFlags est un système open source de feature flags auto-hébergé pour déploiement progressif : évaluation locale via SDK et contrôle REST.