PinchBench
Comparez les performances des agents OpenClaw sur 100+ LLM grâce aux classements de taux de réussite : vérifications automatisées et notation par un LLM.
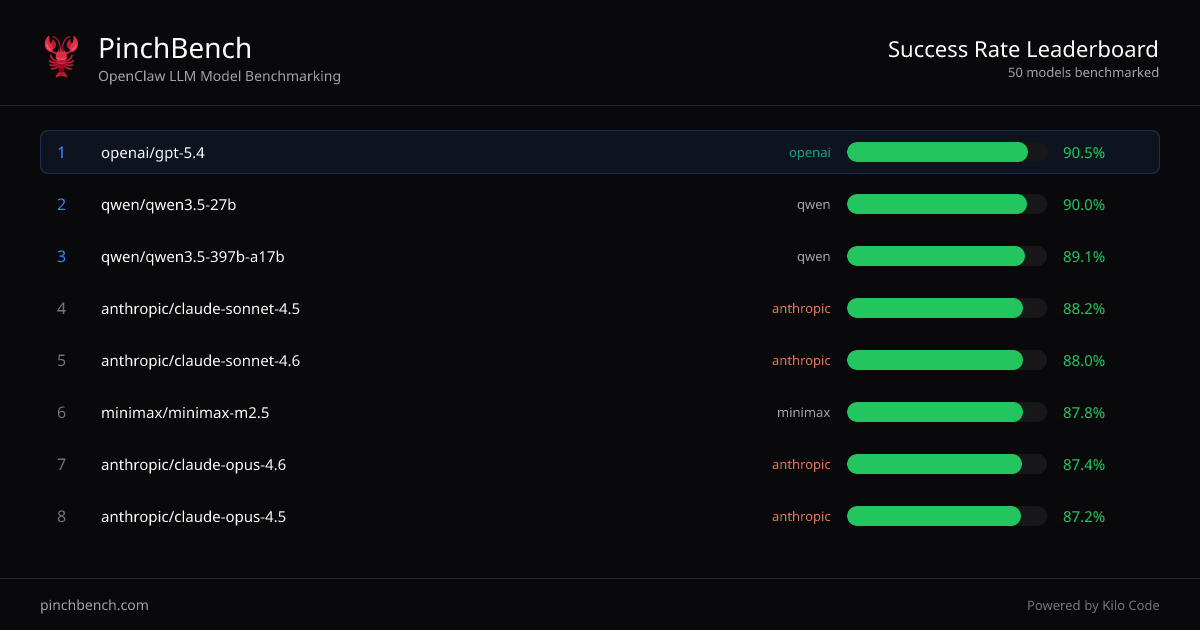
Qu'est-ce que PinchBench ?
PinchBench est un site de benchmarking des modèles LLM OpenClaw qui classe les modèles d'IA par taux de réussite sur des tâches de codage standardisées. Son objectif principal est de vous aider à comparer plusieurs LLM en utilisant le même environnement de test basé sur des agents, afin de choisir un modèle en fonction de résultats mesurés plutôt que d'hypothèses.
Le site présente des classements « Taux de réussite par modèle » et permet de consulter plus de tâches et de détails sur la notation. Il indique également que la notation et l'évaluation sont automatisées à l'aide de vérifications automatisées et d'un juge LLM.
Fonctionnalités principales
- Classements de taux de réussite par modèle : Affiche un tableau trié des modèles avec des champs pour « Best % », « Avg % » et d'autres colonnes de scores pour comparer les performances de manière cohérente.
- Benchmarking d'agents OpenClaw : Évalue les modèles spécifiquement dans le contexte d'un workflow d'agent « OpenClaw », reflétant leurs performances sur des tâches de codage pilotées par agent.
- Notation automatisée avec vérifications et juge LLM : Les scores proviennent de vérifications automatisées et d'un juge LLM, offrant une méthode d'évaluation reproductible.
- Filtrage par budget (max $ par exécution) : Inclut un filtre de budget étiqueté « Max $per run », permettant de recentrer les comparaisons dans une contrainte de coût affichée par l'interface.
- Matériel de test et critères transparents : Indique que « All tasks and grading criteria are open source » et fournit un moyen de consulter les tâches.
Comment utiliser PinchBench
- Accédez à PinchBench et utilisez le tableau de classement des modèles pour comparer les modèles par taux de réussite.
- Ajustez optionnellement le filtrage par budget à l'aide du contrôle « Max $ per run » pour restreindre les résultats aux modèles respectant votre limite de coût indiquée.
- Consultez les vues des tâches et détails de notation (y compris les critères de notation ouverts) pour comprendre ce que mesurent les scores avant de sélectionner un modèle.
Cas d'usage
- Sélection d'un LLM pour un agent de codage OpenClaw : Comparez les modèles candidats par taux de réussite mesuré sur des tâches d'agent standardisées, puis choisissez la meilleure option pour votre cas d'usage.
- Évaluation qualité vs performance moyenne : Utilisez les colonnes « Best % » et « Avg % » du tableau pour différencier les modèles qui excellent en pic de ceux ayant des résultats plus constants.
- Comparaison de modèles consciente des coûts : Appliquez le filtre max $ par exécution pour comparer les modèles sous un plafond budgétaire tout en s'appuyant sur les mêmes tâches de benchmark.
- Examen du calcul des scores : Vérifiez les tâches ouvertes et les critères de notation pour comprendre ce que signifie le « succès » dans le benchmark, et évaluer s'il correspond à votre comportement attendu.
- Comparaison de plusieurs fournisseurs en une vue : Utilisez les classements consolidés pour comparer les modèles de différents fournisseurs (comme indiqué dans le tableau, par ex. OpenAI, Anthropic, Qwen, Minimax et modèles Google).
FAQ
-
Comment PinchBench détermine-t-il le taux de réussite d'un modèle ? Le taux de réussite est mesuré comme le pourcentage de tâches complétées avec succès sur des tests d'agents OpenClaw standardisés, en utilisant des vérifications automatisées et un juge LLM.
-
Puis-je voir ce que contiennent les tests de benchmark ? Oui. La page propose des options pour consulter les tâches, et indique que les tâches et critères de notation sont open source.
-
Quelles métriques sont affichées dans les classements ? Le tableau de classement inclut des champs en pourcentage liés au succès tels que « Best % » et « Avg % » (avec d'autres colonnes de scores visibles dans l'interface).
-
Y a-t-il un moyen de filtrer les modèles par coût ? L'interface inclut un filtre de budget étiqueté « Max $per run », que vous pouvez utiliser pour restreindre les résultats affichés.
-
PinchBench évalue-t-il la qualité générale du chat ? Le site benchmarke spécifiquement les modèles sur des tâches de codage d'agents OpenClaw, et le taux de réussite affiché correspond à ce contexte de benchmark standardisé.
Alternatives
- Leaderboards LLM généraux : Des classements larges et non spécifiques aux tâches peuvent être utiles pour un scan rapide, mais ils ne mesurent généralement pas les performances sur des tâches de codage d'agents OpenClaw.
- Harness d'évaluation propre / benchmarks internes : Exécuter un ensemble curaté de tâches de codage et appliquer votre approche de notation peut mieux correspondre à vos besoins, mais nécessite une configuration et une maintenance continue.
- Évaluations et benchmarks spécifiques aux fournisseurs : Certains vendeurs publient des résultats de performance sur des benchmarks ; ceux-ci peuvent différer en conception de tâches et notation de PinchBench, donc les comparaisons doivent être traitées avec prudence.
- Outils d'évaluation de frameworks d'agents : Des outils permettant de tester les LLM avec des workflows d'agents peuvent fournir des résultats alignés sur les workflows, mais n'offrent pas nécessairement le même benchmark standardisé multi-modèles et critères de notation ouverts que PinchBench.
Alternatives
AakarDev AI
AakarDev AI est une plateforme puissante qui simplifie le développement d'applications d'IA avec une intégration fluide des bases de données vectorielles, permettant un déploiement rapide et une évolutivité.
BookAI.chat
BookAI vous permet de discuter avec vos livres en utilisant l'IA en fournissant simplement le titre et l'auteur.
skills-janitor
skills-janitor audite, suit l’usage et compare vos compétences Claude Code avec neuf actions d’analyse par commandes slash, sans dépendances.
FeelFish
FeelFish AI Novel Writing Agent est un client PC pour auteurs : planifiez personnages et décors, générez et modifiez des chapitres, continuez avec cohérence.
BenchSpan
BenchSpan exécute des benchmarks d’agents IA en parallèle, consigne scores et échecs dans un historique, et facilite la reproductibilité via des exécutions taguées par commit.
ChatBA
ChatBA, l’IA générative pour créer des présentations : utilisez un workflow en chat pour générer rapidement le contenu de vos slides.