SemanticGuard
SemanticGuard est une passerelle IA avec cache auto-validant pour les API LLM d’OpenAI, Anthropic et Google. Mesurez les économies.
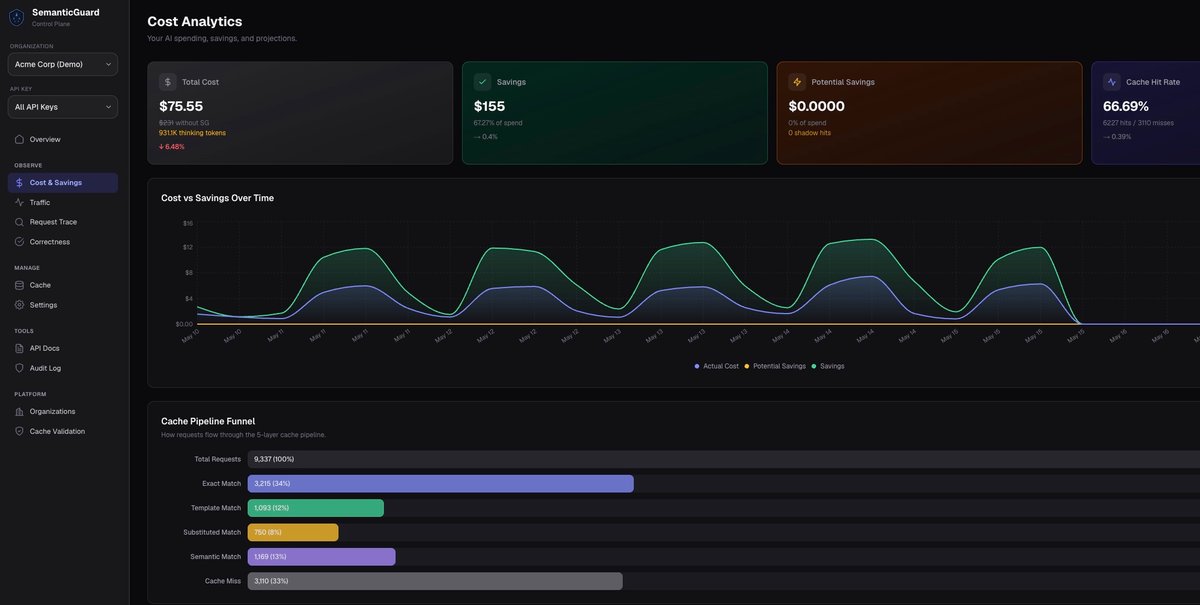
Qu’est-ce que SemanticGuard ?
SemanticGuard est une passerelle IA et un cache auto-validant pour les API LLM. Il se place dans le chemin des requêtes pour des fournisseurs tels qu’OpenAI, Anthropic et Google, met en cache les réponses tout en utilisant une vérification multicouche pour contrôler si une réponse en cache est toujours correcte.
Le produit est conçu pour réduire les dépenses liées aux API LLM sans obliger les utilisateurs à modifier les prompts ni à gérer manuellement des objets de cache. Il inclut aussi un mode Shadow qui mesure les économies potentielles avant l’activation du cache, et prend en charge une conception fail-open afin que les requêtes continuent vers le fournisseur upstream si le cache est indisponible.
Fonctionnalités clés
- Intégration SDK en une ligne via
fetch: withSemanticGuard()dans l’AI SDK, ce qui permet aux équipes d’ajouter la mise en cache sans réécrire la logique applicative. - Mesure en Shadow Mode qui affiche le coût par requête, les économies projetées, les types de hits et l’endroit où le trafic serait mis en cache avant de servir des réponses en cache.
- Hits de cache auto-validants avec vérification multicouche, les hits échantillonnés étant aussi évalués par l’IA pour en vérifier la justesse et signaler les échecs.
- Prise en charge multi-fournisseurs sur OpenAI, Anthropic, Google et d’autres fournisseurs सूचीés tels qu’Azure, Bedrock et Mistral.
- Comportement du cache optimisé pour les correspondances sémantiques, afin que des requêtes avec des noms, dates ou identifiants différents puissent quand même aboutir si la réponse est en pratique la même.
- Gestion des requêtes en fail-open, qui envoie le trafic directement au fournisseur si le cache est hors service.
- Contrôles de sécurité indiqués sur le site, notamment le chiffrement en transit et au repos, le stockage des prompts en option, et des clés API upstream transmises au moment de la requête plutôt que stockées.
Comment utiliser SemanticGuard
Les développeurs ajoutent SemanticGuard à la configuration de leur AI SDK en enveloppant la couche fetch avec withSemanticGuard() puis en envoyant les requêtes comme d’habitude. Le workflow présenté sur le site commence par le Shadow Mode pour mesurer les économies et observer comment le trafic serait classé.
Une fois l’équipe à l’aise avec les résultats, le cache peut être activé. À ce stade, les hits de cache sont renvoyés automatiquement, et le tableau de bord peut être utilisé pour consulter les économies, le taux de hit et les résultats de validation.
Cas d’usage
- Réduire les dépenses des applications LLM à fort volume où de nombreux utilisateurs posent des questions similaires et où des réponses répétées peuvent être réutilisées.
- Mesurer l’économie du cache avant le déploiement, en particulier pour les équipes qui veulent quantifier les économies sans servir immédiatement du contenu mis en cache.
- Servir des requêtes sémantiquement similaires qui diffèrent sur des détails de surface comme les noms, dates ou identifiants, là où un cache fournisseur strictement identique en octets ferait un miss.
- Prendre en charge des piles IA multi-fournisseurs qui ont besoin d’une couche de cache unique sur différents éditeurs de modèles.
- Maintenir la disponibilité pour les applications de production qui ont besoin d’un chemin de secours si la couche de cache est indisponible.
FAQ
SemanticGuard nécessite-t-il des modifications des prompts ? Non. Le site décrit une intégration SDK en une ligne et indique qu’aucune modification des prompts n’est nécessaire.
Puis-je tester les économies avant d’activer les hits de cache ? Oui. SemanticGuard inclut le Shadow Mode, qui mesure ce que vous économiseriez avant que les réponses en cache ne soient servies.
Fonctionne-t-il avec plus d’un fournisseur de modèles ? Oui. La page cite OpenAI, Anthropic, Google, et mentionne aussi la compatibilité avec d’autres fournisseurs comme Azure, Bedrock et Mistral.
Que se passe-t-il si le cache est indisponible ? Le produit est décrit comme fail-open, ce qui signifie que les requêtes vont directement au fournisseur.
Le produit est-il réservé au cache à correspondance exacte ? Non. La page présente SemanticGuard comme du semantic caching, destiné aux requêtes qui veulent dire la même chose même si des détails comme les noms, dates ou identifiants changent.
Alternatives
- Cache de prompts natif au fournisseur, comme le cache intégré d’OpenAI ou de fournisseurs similaires. Cela se limite généralement à une réutilisation exacte ou quasi exacte des préfixes dans le système du fournisseur et convient mieux aux segments de prompt statiques.
- Couches de cache manuelles intégrées à une application ou à un proxy. Elles peuvent être personnalisées, mais nécessitent généralement plus de travail d’ingénierie pour définir les clés de cache, gérer l’invalidation et vérifier la correction.
- Passerelles IA générales sans validation sémantique. Elles peuvent gérer le routage, l’observabilité ou l’application de politiques, mais ne se concentrent pas nécessairement sur la mise en cache avec vérification de la justesse.
- Utilisation directe du fournisseur sans couche de cache. C’est la configuration la plus simple, mais elle n’ajoute ni réutilisation entre requêtes similaires ni workflow de mesure des économies avant lancement.
Alternatives
AakarDev AI
AakarDev AI est une plateforme puissante qui simplifie le développement d'applications d'IA avec une intégration fluide des bases de données vectorielles, permettant un déploiement rapide et une évolutivité.
Ably Chat
Ably Chat : API et SDK de chat temps réel pour créer des applications personnalisées, avec réactions, présence et édition/suppression de messages.
BookAI.chat
BookAI vous permet de discuter avec vos livres en utilisant l'IA en fournissant simplement le titre et l'auteur.
DeepMotion
DeepMotion est une plateforme IA de motion capture et body-tracking pour générer des animations 3D à partir de vidéo (et texte) dans votre navigateur.
skills-janitor
skills-janitor audite, suit l’usage et compare vos compétences Claude Code avec neuf actions d’analyse par commandes slash, sans dépendances.
Arduino VENTUNO Q
Arduino VENTUNO Q : ordinateur edge IA pour la robotique, combinant inférence accélérée et microcontrôleur pour un contrôle déterministe. Arduino App Lab.