Lamatic.ai
Lamatic.ai propose un Toolkit LLM Ops : suivi temps réel de disponibilité sur 18 API IA, calculateur de coûts avec TCO, simulateur de routage.
Qu'est-ce que Lamatic.ai ?
Le Toolkit LLM Ops de Lamatic.ai aide les équipes à évaluer et exploiter plusieurs fournisseurs LLM en tenant compte de la visibilité sur la planification et les opérations. Il combine des outils pour l'estimation des coûts, la simulation de routage de modèles, le suivi de la disponibilité des fournisseurs et une évaluation de la maturité opérationnelle.
L'objectif principal est de soutenir la prise de décision sur les modèles à utiliser, la façon de router les requêtes entre fournisseurs et la quantification des « coûts cachés » opérationnels (comme le temps passé sur les opérations de modèles) en parallèle de la fiabilité observée des fournisseurs.
Fonctionnalités clés
- Calculateur de coûts LLM et analyse des coûts réels : Estime les coûts mensuels et annuels à partir d'entrées comme le nombre de fournisseurs, les dépenses API mensuelles, la taille de l'équipe ingénierie, le temps alloué aux opérations de modèles et un multiplicateur TCO pour calculer un coût mensuel « réel » et les coûts cachés.
- Simulateur de routage avec comparaison de stratégies : Simule le routage de requêtes sur différents modèles en utilisant des paramètres comme le volume de requêtes, la complexité des requêtes et une stratégie de routage (incluant des concepts optimisés pour les coûts et la qualité en priorité) pour estimer les économies de coûts et les résultats qualité/latence.
- Audit de diversité et maturité des modèles : Évalue la maturité LLM Ops via un ensemble de questions ciblées (présentées comme une évaluation de maturité avec recommandations) pour guider les étapes suivantes.
- Radar de capacités (vue de comparaison de modèles) : Affiche une comparaison en style radar de capacités pour plusieurs modèles listés, incluant le coût par 1K tokens, le score qualité et la latence.
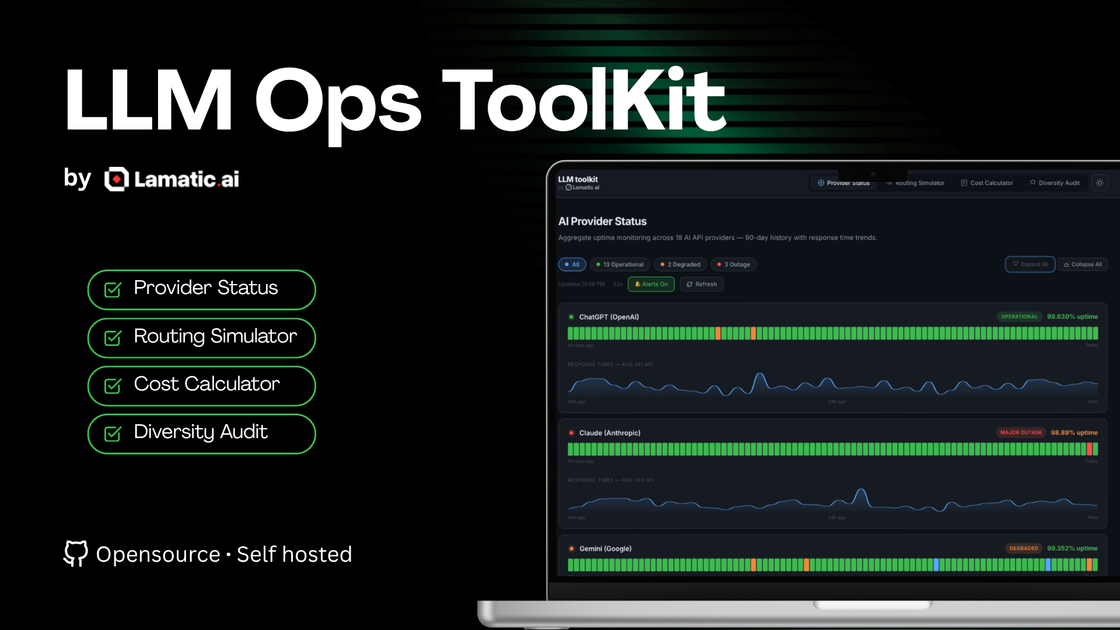
- Suivi agrégé de disponibilité sur les API IA : Suit l'état des fournisseurs avec un historique de 90 jours et des tendances de temps de réponse, incluant des états opérationnels comme opérationnel, dégradé et panne ; inclut des contrôles de notification de panne (indiqués par une icône d'alerte).
Comment utiliser Lamatic.ai
- Commencez par vos hypothèses de base dans le calculateur de coûts : définissez le nombre de fournisseurs LLM, les dépenses API mensuelles, la taille de l'équipe ingénierie et le pourcentage de temps ingénierie passé sur les opérations de modèles pour générer une estimation de « coût réel » et de coûts cachés.
- Lancez une simulation de routage : choisissez un volume et une complexité de requêtes, puis comparez les résultats des stratégies de routage (par exemple, routage priorisant les coûts versus routage priorisant la qualité) pour quantifier les économies potentielles et les évolutions qualité/latence attendues.
- Évaluez la fiabilité des fournisseurs via la vue de suivi de disponibilité pour examiner les 90 derniers jours d'uptime et les tendances de temps de réponse sur l'ensemble des fournisseurs supportés.
- Complétez l'audit de maturité en répondant aux questions ciblées pour identifier les étapes recommandées suivantes et situer votre processus actuel d'opérations LLM sur l'échelle de maturité.
Cas d'usage
- Planification de budgets LLM multi-fournisseurs : Une équipe peut utiliser le calculateur de coûts pour convertir la facturation API brute en une vue « coût mensuel réel » plus large incluant le temps ingénierie et un multiplicateur TCO estimé, aidant à justifier les investissements opérationnels.
- Évaluation si le routage peut réduire les dépenses : En simulant une stratégie de routage où une partie du trafic va vers des modèles moins chers, une équipe ingénierie peut estimer les économies annuelles potentielles et comparer des allocations de routage conservatrices versus optimistes.
- Comparaison de modèles sous hypothèses de charge : Les équipes peuvent utiliser le radar de capacités et le simulateur de routage ensemble pour comparer les modèles listés par coût au token et latence, puis valider l'impact du routage sur la qualité et latence moyennes sous un profil de requêtes donné.
- Revue des risques opérationnels pour la performance des fournisseurs : À l'aide du suivi agrégé d'uptime avec historique de 90 jours, les équipes peuvent examiner les tendances de temps de réponse et pannes/dégradations pour informer la stratégie fournisseur ou la planification d'incidents.
- Analyse des écarts pour la maturité LLM Ops : Les organisations nouvelles en LLMOps ou déjà équipées peuvent utiliser l'audit de maturité pour structurer les améliorations via l'évaluation des capacités guidée par questionnaire.
FAQ
-
Quelles métriques le toolkit calcule-t-il pour les coûts ? La page décrit une analyse de coût réel qui combine les dépenses mensuelles d’API avec le temps d’ingénierie sur les opérations de modèles et un multiplicateur TCO, produisant un « coût mensuel réel » et des chiffres de coûts cachés.
-
Puis-je simuler le routage sur plusieurs modèles ? Oui. Le simulateur de routage est conçu pour visualiser comment le routage distribue les requêtes sur les modèles et estimer les économies de coûts et les résultats de routage.
-
Quels fournisseurs sont couverts par le suivi de disponibilité ? La section de suivi de disponibilité indique qu’elle couvre 18 fournisseurs d’API IA et fournit un historique de 90 jours avec les tendances des temps de réponse.
-
Que mesure l’audit de maturité ? L’audit de maturité est présenté comme une évaluation utilisant 10 questions ciblées et génère des recommandations ad hoc et une vue de type radar de capacités.
Alternatives
- Outils de comptabilité des coûts et tokens LLM (tableaux de bord de coûts) : Ils se concentrent sur l’utilisation d’API et le suivi des coûts de tokens, mais n’incluent généralement pas la même combinaison de modélisation TCO réel, simulation de routage, historique de disponibilité des fournisseurs et audit de maturité.
- Plateformes générales de suivi de disponibilité/latence d’API : Les outils de monitoring peuvent suivre la disponibilité et les temps de réponse des endpoints, mais nécessitent souvent plus de configuration pour modéliser les décisions de routage LLM et les compromis coût/qualité sur plusieurs fournisseurs de modèles.
- Logique de routage personnalisée avec analyses internes : Les équipes peuvent construire le routage et l’évaluation en interne avec leur télémétrie ; cela peut reproduire des parties du simulateur mais nécessite généralement plus d’efforts d’ingénierie pour créer des comparaisons coût/qualité/latence et des vues d’état historique des fournisseurs.
Alternatives
ClawTick
ClawTick est une plateforme d’automatisation d’agents IA via CLI pour planifier des tâches webhooks en cron avec monitoring, alertes, retries et logs.
OpenFlags
OpenFlags est un système open source de feature flags auto-hébergé pour déploiement progressif : évaluation locale via SDK et contrôle REST.
skills-janitor
skills-janitor audite, suit l’usage et compare vos compétences Claude Code avec neuf actions d’analyse par commandes slash, sans dépendances.
BenchSpan
BenchSpan exécute des benchmarks d’agents IA en parallèle, consigne scores et échecs dans un historique, et facilite la reproductibilité via des exécutions taguées par commit.
Rectify
Rectify est une plateforme d’opérations tout-en-un pour SaaS : monitoring, analytics, support, roadmaps, changelogs et gestion des agents, pilotés par conversation.
PromptScout
PromptScout suit les mentions de votre marque, les concurrents recommandés et les sources citées dans ChatGPT, Gemini, Google AI Overviews et Perplexity.