PinchBench
PinchBench confronta le prestazioni dell’agent OpenClaw su 100+ LLM: classifiche per success rate con controlli automatici e grading giudicato da LLM.
Cos'è PinchBench?
PinchBench è un sito di benchmarking per modelli LLM OpenClaw che classifica i modelli AI in base al success rate su task di coding standardizzati. Il suo scopo principale è aiutarti a confrontare più LLM usando la stessa configurazione di test basata su agent, così puoi scegliere un modello in base a risultati misurati anziché supposizioni.
Il sito presenta classifiche “Success rate by model” e ti permette di visualizzare più task e dettagli di grading. Indica inoltre che grading e scoring sono automatizzati tramite controlli automatici e un giudice LLM.
Caratteristiche Principali
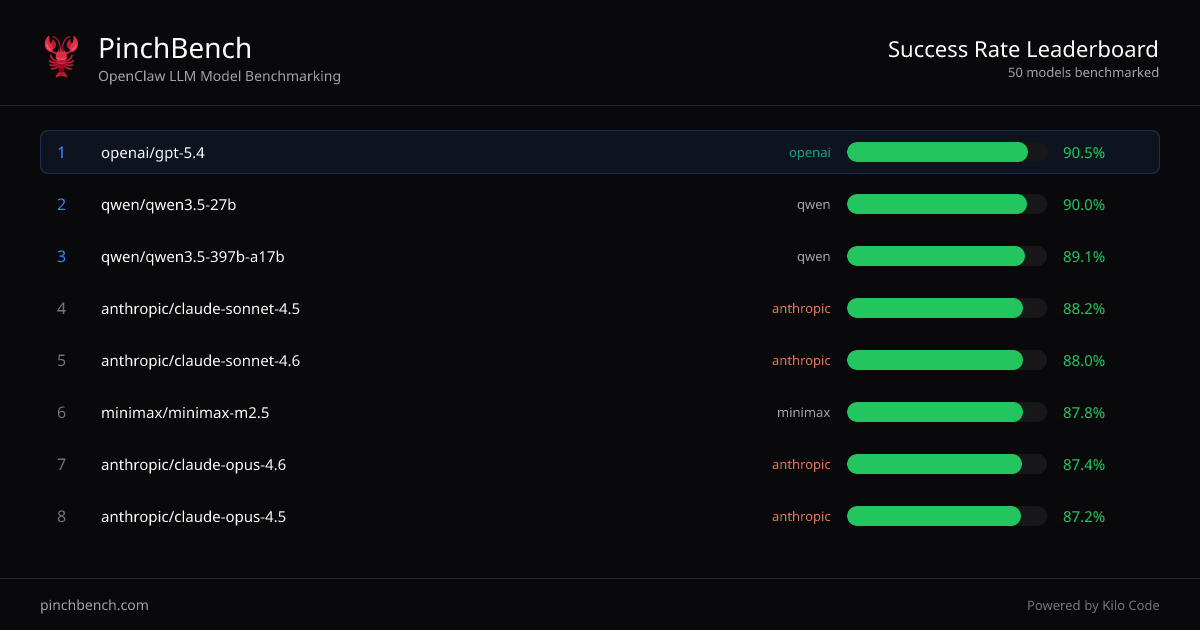
- Classifiche per success rate tra modelli: Mostra una tabella ordinata di modelli con campi per “Best %,” “Avg %” e colonne di punteggio correlate per confrontare le prestazioni in modo coerente.
- Benchmarking dell’agent OpenClaw: Valuta i modelli specificamente nel contesto di un workflow agent “OpenClaw,” riflettendo le prestazioni su task di coding guidati da agent.
- Grading automatizzato con controlli e giudice LLM: I punteggi derivano da controlli automatici e un giudice LLM, fornendo un metodo di valutazione ripetibile.
- Filtro budget (max $ per run): Include un filtro budget etichettato “Max $per run,” che ti permette di concentrare i confronti entro un vincolo di costo mostrato dall’interfaccia.
- Materiali e criteri di test trasparenti: Nota che “All tasks and grading criteria are open source” e fornisce un modo per visualizzare i task.
Come Usare PinchBench
- Vai su PinchBench e usa la tabella di ranking dei modelli per confrontare i modelli per success rate.
- Opzionalmente regola il filtro budget usando il controllo “Max $ per run” per restringere i risultati ai modelli che rientrano nel tuo limite di costo specificato.
- Usa le viste task e dettagli di grading (inclusi criteri di grading open) per capire cosa misurano i punteggi prima di selezionare un modello.
Casi d'Uso
- Selezione di un LLM per un agent di coding OpenClaw: Confronta i modelli candidati per success rate misurato su task agent standardizzati, poi scegli l’opzione con le migliori prestazioni per il tuo caso d’uso.
- Valutazione qualità vs. prestazioni medie: Usa le colonne “Best %” e “Avg %” della tabella per distinguere modelli che piccano bene da quelli con risultati più consistenti.
- Confronto modelli con attenzione ai costi: Applica il filtro max $ per run per confrontare modelli sotto un tetto di budget mantenendo gli stessi task di benchmark.
- Revisione di come sono calcolati i punteggi: Controlla task open e criteri di grading per verificare cosa significa “success” nel benchmark e valutare se si allinea al tuo comportamento atteso.
- Confronto di più provider in un’unica vista: Usa le classifiche consolidate per confrontare modelli di diversi provider (come mostrato nella tabella, es. OpenAI, Anthropic, Qwen, Minimax e modelli Google).
FAQ
-
Come determina PinchBench il success rate di un modello? Il success rate è misurato come percentuale di task completati con successo su test agent OpenClaw standardizzati, usando controlli automatici e un giudice LLM.
-
Posso vedere cosa includono i test di benchmark? Sì. La pagina offre opzioni per visualizzare i task e afferma che task e criteri di grading sono open source.
-
Quali metriche sono mostrate nelle classifiche? La tabella di ranking include campi percentuali legati al success come “Best %” e “Avg %” (con colonne di punteggio aggiuntive visibili nell’interfaccia).
-
C’è un modo per filtrare i modelli per costo? L’interfaccia include un filtro budget etichettato “Max $per run,” che puoi usare per restringere i risultati mostrati.
-
PinchBench valuta la qualità generale della chat? Il sito benchmarka specificamente i modelli su task di coding agent OpenClaw, e il success rate mostrato corrisponde a quel contesto di benchmark standardizzato.
Alternative
- Leaderboard generali LLM: Classifiche ampie e non specifiche per task possono essere utili per una scansione rapida, ma tipicamente non misurano le prestazioni su task di coding agent OpenClaw.
- Harness di valutazione proprietario / benchmark interni: Eseguire un set curato di task di coding e applicare il tuo approccio di grading può adattarsi meglio ai tuoi requisiti, ma richiede setup e manutenzione continua.
- Eval e benchmark specifici del provider: Alcuni vendor pubblicano risultati di performance su benchmark; questi possono differire in design task e grading da PinchBench, quindi i confronti vanno trattati con cautela.
- Tool di valutazione per framework agent: Tool che ti permettono di testare LLM con workflow agent possono fornire risultati allineati al workflow, ma potrebbero non offrire lo stesso benchmark cross-modello standardizzato e criteri di grading open di PinchBench.
Alternative
AakarDev AI
AakarDev AI è una piattaforma potente che semplifica lo sviluppo di applicazioni AI con integrazione fluida dei database vettoriali, consentendo un rapido deployment e scalabilità.
BookAI.chat
BookAI ti consente di chattare con i tuoi libri utilizzando l'IA semplicemente fornendo il titolo e l'autore.
skills-janitor
skills-janitor esegue audit, traccia l’uso e confronta le tue skill per Claude Code con 9 azioni slash mirate, senza dipendenze.
FeelFish
FeelFish AI Novel Writing Agent è un client PC per autori: pianifica personaggi e ambienti, genera e modifica capitoli e continua trame con coerenza.
BenchSpan
BenchSpan esegue benchmark per AI agent in parallelo, salva punteggi e errori in una run history ordinata e replica risultati con commit-tag.
ChatBA
ChatBA è una generative AI per creare slide deck con un workflow in stile chat: genera rapidamente contenuti per la tua presentazione.