Claro
ClaroのResearch Agentsが、ネイティブなテーブル上で手作業の調査を自動化。リスト強化、文書から構造化データ抽出、価格変化の監視に対応。
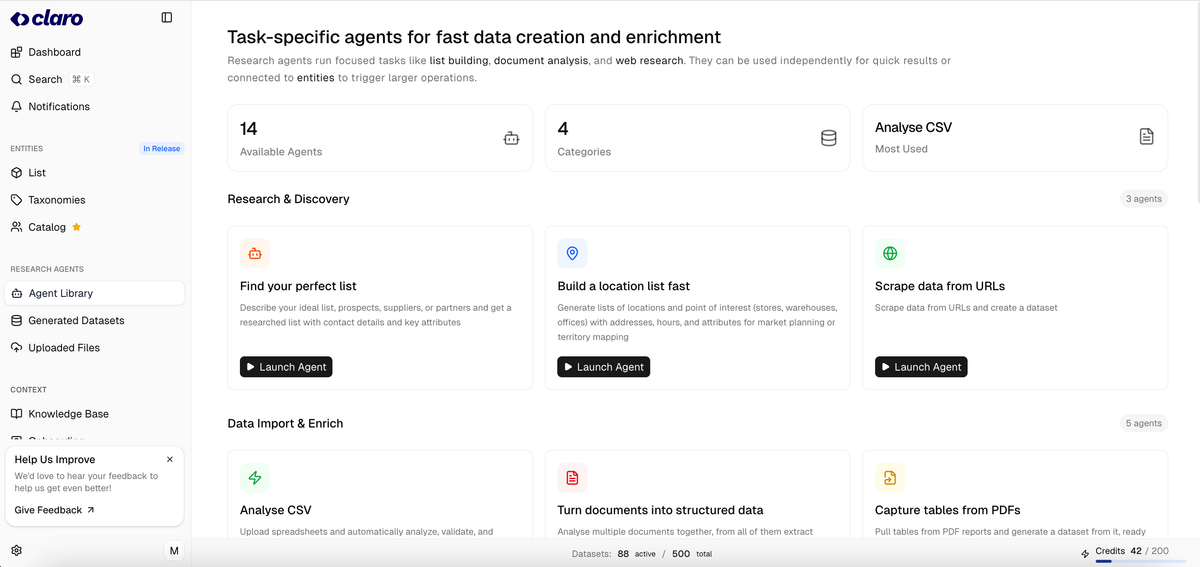
Claro (Research Agents)とは?
ClaroのResearch Agentsは、テーブル内で直接手作業の調査作業を自動化するAI調査ツールです。エージェントはデータセットの生成・強化、企業調査、価格などの変更監視、文書からの構造化データ抽出が可能で、下流工程向けに構造化された出力形式です。
このページでは、Research Agentsを「スタンドアロン」(独立使用可能)と位置づけつつ、「Claro内ではより強力」とし、既存の「マスターテーブル」ワークフローと連携します。主な目的は、調査出力を構造化・追跡可能にし、チームがすでに使用する同一データセットに配信することです。
主な機能
- ネイティブテーブルワークフロー(データセットから開始): インポートしたCSV、サプライヤーカタログ、生成データセット、または空のテーブルから始め、調査出力を同一テーブル構造内に保持。
- 行ベース実行とスケーリング制御: 列を追加し、タスクを定義して、小規模サンプル(例: 10行)から大規模セット(例: 100,000行)までツール切り替えなしで実行。
- リストの生成・強化: ソース(ウェブサイト含む)をスキャンし、構造化データポイントでリストを強化。
- 構造化抽出のためのドキュメント処理: PDFや契約書をアップロードし、テーブル対応フィールドに構造化データを抽出。
- 価格/在庫変更の監視: ソース全体の価格、在庫、変更をリアルタイム追跡し、データセットを最新状態に保つ。
- 分類とタグ付け: テーブル内で定義したカスタムロジックで自動分類・タグ付け。
- Claro接続モードでエンティティ認識出力: Claro接続時、エージェントはエンティティ認識で正準IDに整合し、ERP、PIM、eコマース、アナリティクスシステムと同期。監査トレイルとレビューキューによるガバナンス付き。
Claro (Research Agents)の使い方
- テーブルを作成またはインポート: Claro内でインポートしたCSV、サプライヤーカタログ、生成データセット、または空のテーブルから開始。
- 調査タスクを選択: リスト強化、ドキュメント処理/抽出、分類/タグ付け、監視などのエージェント機能を選択。
- 基準を定義して実行: 出力用の列を追加、自然言語でタスク/基準を記述(該当する場合)、選択行でエージェントを実行。
- 構造化出力を確認: テーブル結果を確認し、Claro接続時は監査トレイルやレビューキューなどのトレーサビリティ・ガバナンス機能を活用して下流更新を確定。
ユースケース
- 運用調査のためのリスト強化: 関連ウェブサイトをスキャンし、既存リストを構造化データポイントで強化、同一テーブル形式で結果保持。
- 企業調査とデータセット拡張: 提供基準に基づき企業を調査し、非構造化テキストではなく強化・検証済みデータセット行を生成。
- 価格・在庫監視: ソース全体の価格、在庫、変更をリアルタイム監視し、変更時にデータセットを更新。
- 契約/PDFの構造化抽出: PDFや契約書をアップロードし、キー構造化フィールドをテーブルに抽出、分析と下流処理を容易に。
- 大規模分類・タグ付け: カスタム分類ロジックを適用し、データセット内でアイテムを自動分類・タグ付け。
FAQ
Research Agentは単独で使用可能ですか?
はい。ページでは、Research Agentを構造化調査ツールとして独立使用可能と記載。
どのような入力形式から始められますか?
ClaroのResearch Agentsは、インポートしたCSV、サプライヤーカタログ、生成データセット、空のテーブルから開始可能。
出力はどこに保存されますか?
出力はネイティブテーブルインターフェース内で直接実行され、テーブル形式の構造化結果を生成(ページ記載の「structured in, structured out」)。
文書からどのようなデータが抽出可能ですか?
ページでは、PDFや契約書のアップロードで構造化データを抽出すると具体的に記載。
Claro接続でエージェントが向上しますか?
ページでは、Claro接続時の追加動作として、エンティティ認識、正準ID整合、ERP/PIM/eコマース/アナリティクスシステム同期、監査トレイル・レビューキュー付きガバナンスを記載。
代替案
- 汎用AI抽出ツール(ドキュメントから構造化ツール): PDF/契約書からフィールド抽出が主なニーズの場合に有用ですが、テーブル優先・データセットネイティブなワークフローに特化していない可能性があります。
- WebスクレイピングとETLパイプライン: ウェブサイトから情報を収集しデータシステムにロード可能。ただし、検証済み構造化テーブル出力に変換するには通常、より多くのエンジニアリングが必要です。
- データカタログ/エンチッチメントプラットフォーム: エンティティデータの強化・標準化に焦点。ただし、ツールによってはデータ品質ワークフローを重視し、テーブル内で直接調査を実行するわけではありません。
- 手動調査ステップを含むBIワークフロー: データ準備後の分析に有用ですが、ClaroのResearch Agentsで説明される調査・抽出・監視ステップを直接自動化しません。
代替品
Happenstance
HappenstanceはAI搭載のネットワーク検索。GmailやGoogleカレンダー、LinkedInなどつながりを基に人を調査し、営業・採用に活用。
Bardeen
Bardeenは、ユーザーがリードを効率的にソース、資格付け、連絡するのを助けるAI駆動のウェブスクレイパーです。
Paperpal
Paperpalは学術執筆向けAIツール。文献の読み取り、英語の校正・学術改稿、執筆コンポーネント生成、投稿前チェックと類似度検知をサポート。
VForms
VFormsは、YouTube動画上に直接インタラクティブなアンケートを重ねて表示できるようにすることで、非常に文脈に即したフィードバックと深いユーザーインサイトを収集可能にします。
Scite
Sciteは、研究者が研究の議論を理解し、信頼できる引用を確保し、執筆を改善するのを助けるAI駆動の研究ツールです。
DataSieve: Text to Data
DataSieve: Text to Dataは、iPhone/iPad/Macでオフライン動作。テキストや各種ファイルからメール・日付・URLなどを抽出します。