PinchBenchとは?
PinchBenchは、OpenClaw LLMモデルベンチマークサイトで、標準化されたコーディングタスクでの成功率でAIモデルをランキングします。主な目的は、同じエージェントベースのテスト環境で複数のLLMを比較し、仮定ではなく測定結果に基づいてモデルを選択できるようにすることです。
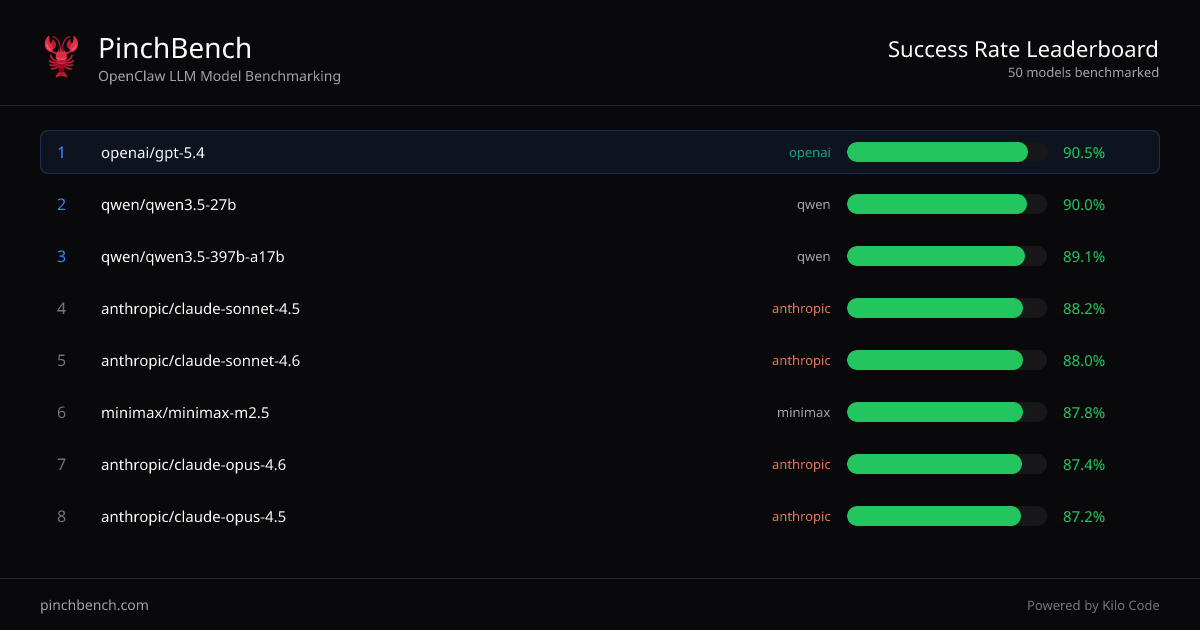
サイトでは「モデル別成功率」ランキングを表示し、さらに多くのタスクや採点詳細を確認できます。また、採点とスコアリングは自動チェックとLLMジャッジにより自動化されていることを示します。
主な機能
- モデル間の成功率ランキング: 「Best %」「Avg %」および関連スコア列を含むソートされたモデルテーブルを表示し、一貫した性能比較を可能にします。
- OpenClawエージェントベンチマーク: 「OpenClaw」エージェントワークフローの文脈でモデルを評価し、エージェント駆動のコーディングタスクでの性能を反映します。
- チェックとLLMジャッジによる自動採点: スコアは自動チェックとLLMジャッジから導かれ、再現可能な評価方法を提供します。
- 予算フィルタリング(実行あたり最大$): インターフェースに表示される「Max $per run」ラベルの予算フィルタを備え、コスト制約内で比較に絞り込めます。
- 透明なテスト素材と基準: 「すべてのタスクと採点基準はオープンソース」と記載し、タスク閲覧方法を提供します。
PinchBenchの使い方
- PinchBenchにアクセスし、モデルランキングテーブルを使って成功率でモデルを比較します。
- オプションで「Max $ per run」コントロールを使って予算フィルタリングを調整し、指定したコスト上限に合うモデルに結果を絞り込みます。
- タスクビューと採点詳細(オープンな採点基準を含む)を使って、スコアが何を測定しているかを理解してからモデルを選択します。
ユースケース
- OpenClawコーディングエージェント向けLLMの選定: 標準化されたエージェントタスクでの測定成功率で候補モデルを比較し、使用ケースに最適な高性能モデルを選択します。
- 最高性能 vs. 平均性能の評価: テーブルの「Best %」と「Avg %」列を使って、ピーク性能が高いモデルと一貫性のあるモデルを区別します。
- コスト考慮モデル比較: max $ per runフィルタを適用し、予算上限内で同じベンチマークタスクに基づくモデル比較を行います。
- スコア計算方法の確認: オープンタスクと採点基準を確認し、ベンチマークでの「成功」の意味を検証し、期待する動作に合っているかを評価します。
- 複数プロバイダの一括比較: 集約ランキングを使って異なるプロバイダ(テーブルに表示される例: OpenAI, Anthropic, Qwen, Minimax, Googleモデル)のモデルを一画面で比較します。
FAQ
-
PinchBenchはモデルの成功率をどのように決定するのですか? 成功率は、標準化されたOpenClawエージェントテストで成功裏に完了したタスクの割合として測定され、自動チェックとLLMジャッジを使用します。
-
ベンチマークテストの内容を確認できますか? はい。ページでタスク閲覧オプションがあり、タスクと採点基準はオープンソースです。
-
ランキングに表示される指標は何ですか? ランキングテーブルには「Best %」「Avg %」などの成功関連パーセンテージフィールド(インターフェースに表示される追加スコア列を含む)が含まれます。
-
コストでモデルをフィルタリングできますか? インターフェースに「Max $per run」とラベルされた予算フィルタがあり、表示結果を制限できます。
-
PinchBenchは一般的なチャット品質を評価しますか? サイトはOpenClawエージェントコーディングタスクに特化しており、表示される成功率はその標準化されたベンチマーク文脈に対応します。
代替案
- 一般的なLLMリーダーボード: 広範でタスク非特化のランキングはクイックスキャンに便利ですが、通常OpenClawエージェントコーディングタスクの性能を測定しません。
- 独自評価ハーネス / 内部ベンチマーク: 厳選したコーディングタスクを実行し、自社の採点手法を適用することで要件に適合しますが、セットアップと継続メンテナンスが必要です。
- プロバイダ固有の評価とベンチマーク: 一部のベンダーがベンチマーク横断のパフォーマンス結果を公開していますが、タスク設計と採点がPinchBenchと異なるため、比較は慎重に行ってください。
- エージェントフレームワーク評価ツール: エージェントワークフローでLLMをテストできるツールはワークフロー適合結果を提供しますが、PinchBenchのような標準化クロスモデルベンチマークやオープン採点基準を提供しない場合があります。
代替品
AakarDev AI
AakarDev AIは、シームレスなベクターデータベース統合を通じてAIアプリケーションの開発を簡素化し、迅速な展開とスケーラビリティを実現する強力なプラットフォームです。
BookAI.chat
BookAIは、書名と著者を提供するだけで、AIを使って本とチャットできるサービスです。
skills-janitor
skills-janitorでClaude Codeのスキルを監査・使用状況を追跡し、9つの/コマンドと比較。重複や不備もチェック。依存なし。
FeelFish
FeelFish AI Novel Writing Agentは、PCで小説制作を支援。登場人物・設定計画、章生成/編集、文脈管理でプロットを継続します。
BenchSpan
BenchSpanはAIエージェントのベンチマークを並列実行し、スコアと失敗を整理した実行履歴に記録。コミット連携で再現性向上。
ChatBA
ChatBAは、チャット形式のワークフローで入力からスライドデッキの文章を素早く下書き作成できる生成AIです。