Loading...
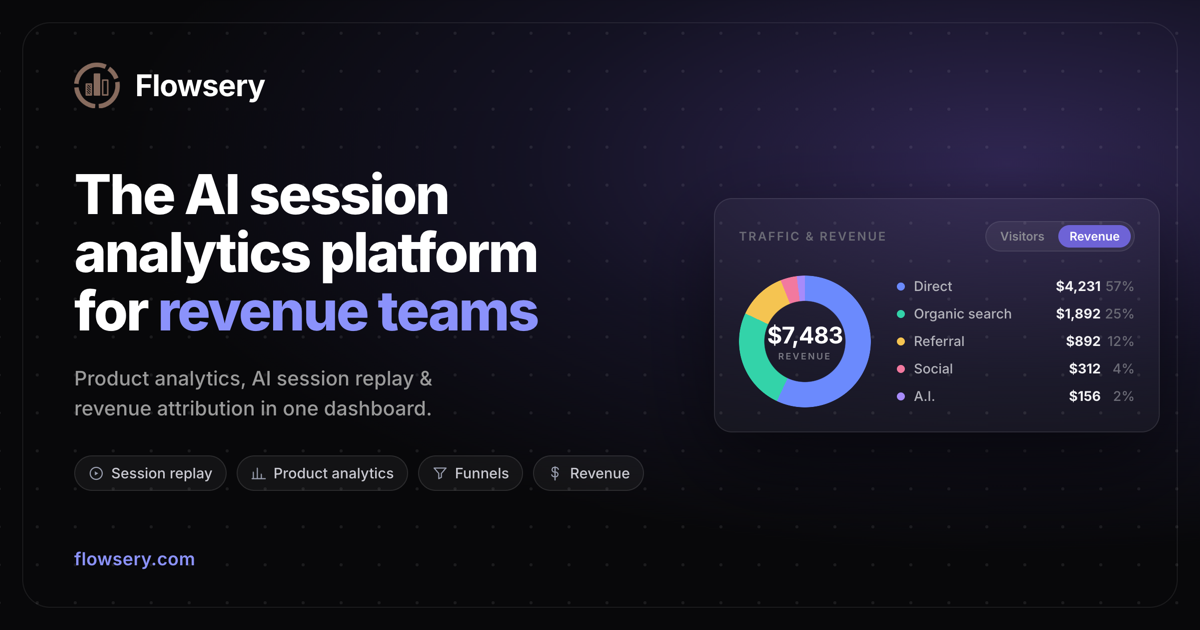
Flowsery AI Session Replay records web sessions, uses AI to flag bugs and drop-offs, and helps product and engineering teams review the exact moment a problem occurred. It is part of Flowsery’s broader web analytics platform.
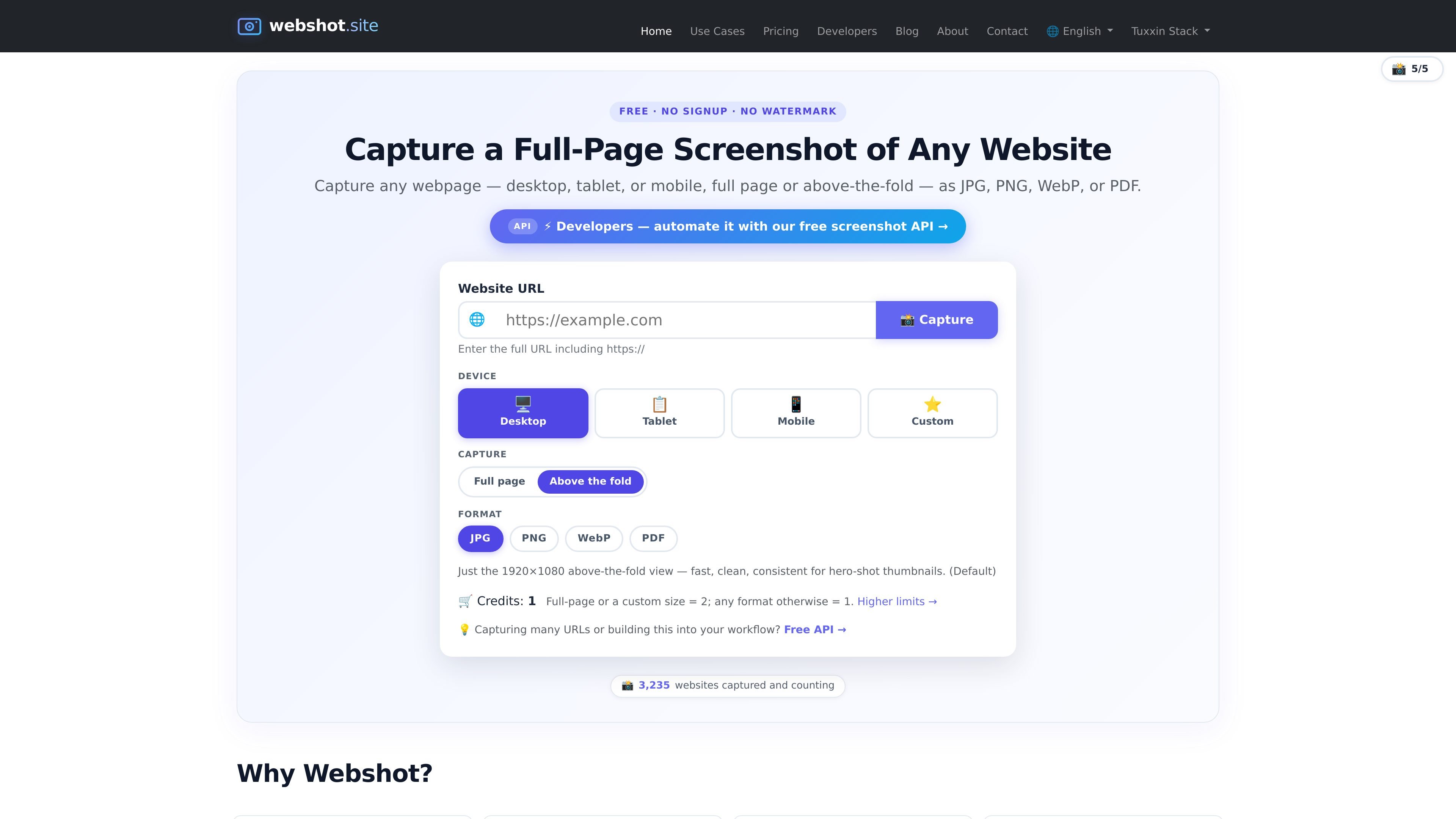
Webshot is a website screenshot tool and screenshot API for capturing public webpages as JPG, PNG, WebP, or PDF. It supports manual capture in the browser and API-driven automation for public URLs.
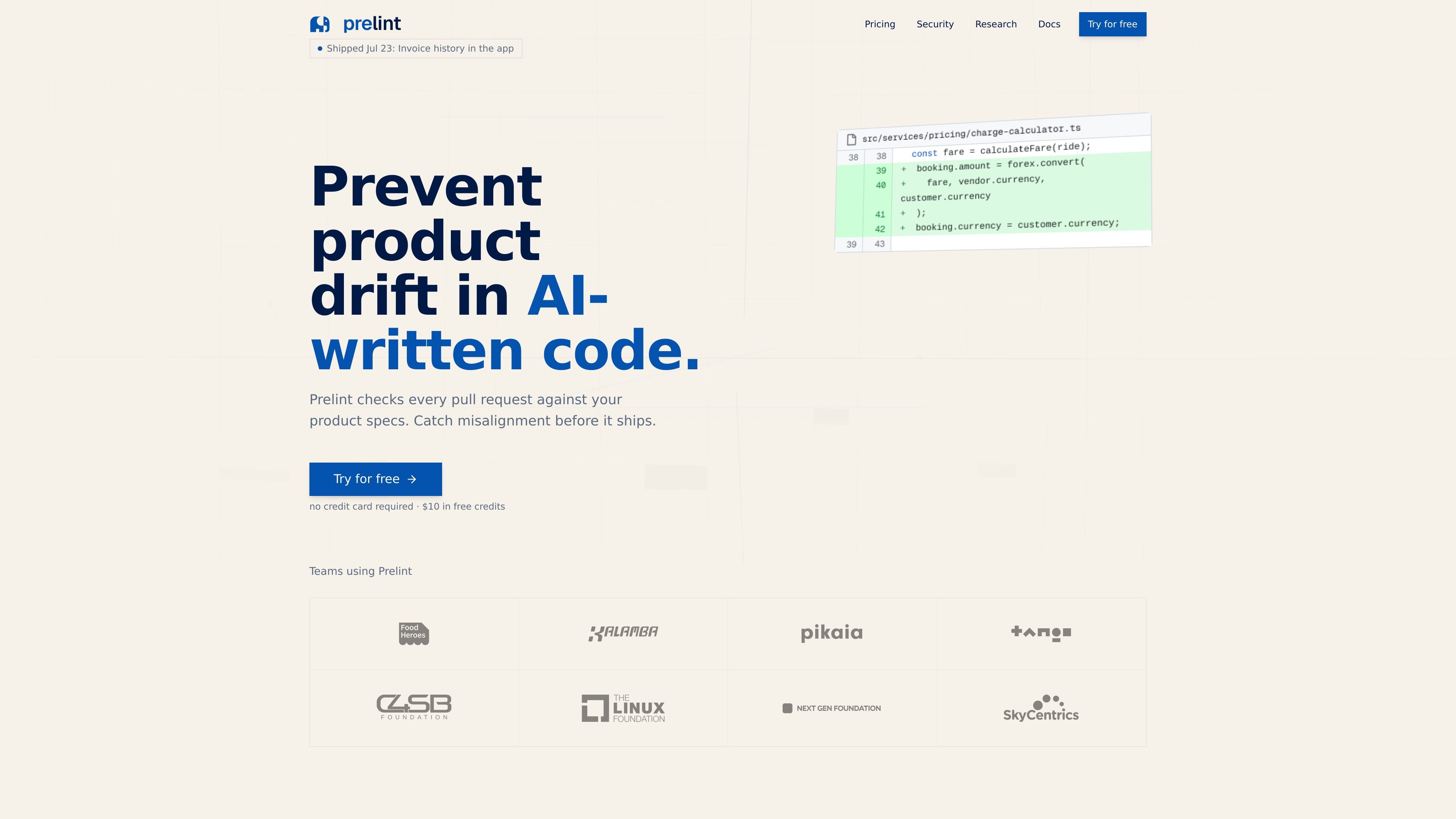
Prelint reviews pull requests against product specifications to catch drift, inconsistencies, and misalignment before changes ship. It uses repo-based specs and prepaid, usage-based billing with $10 in free credits to start.
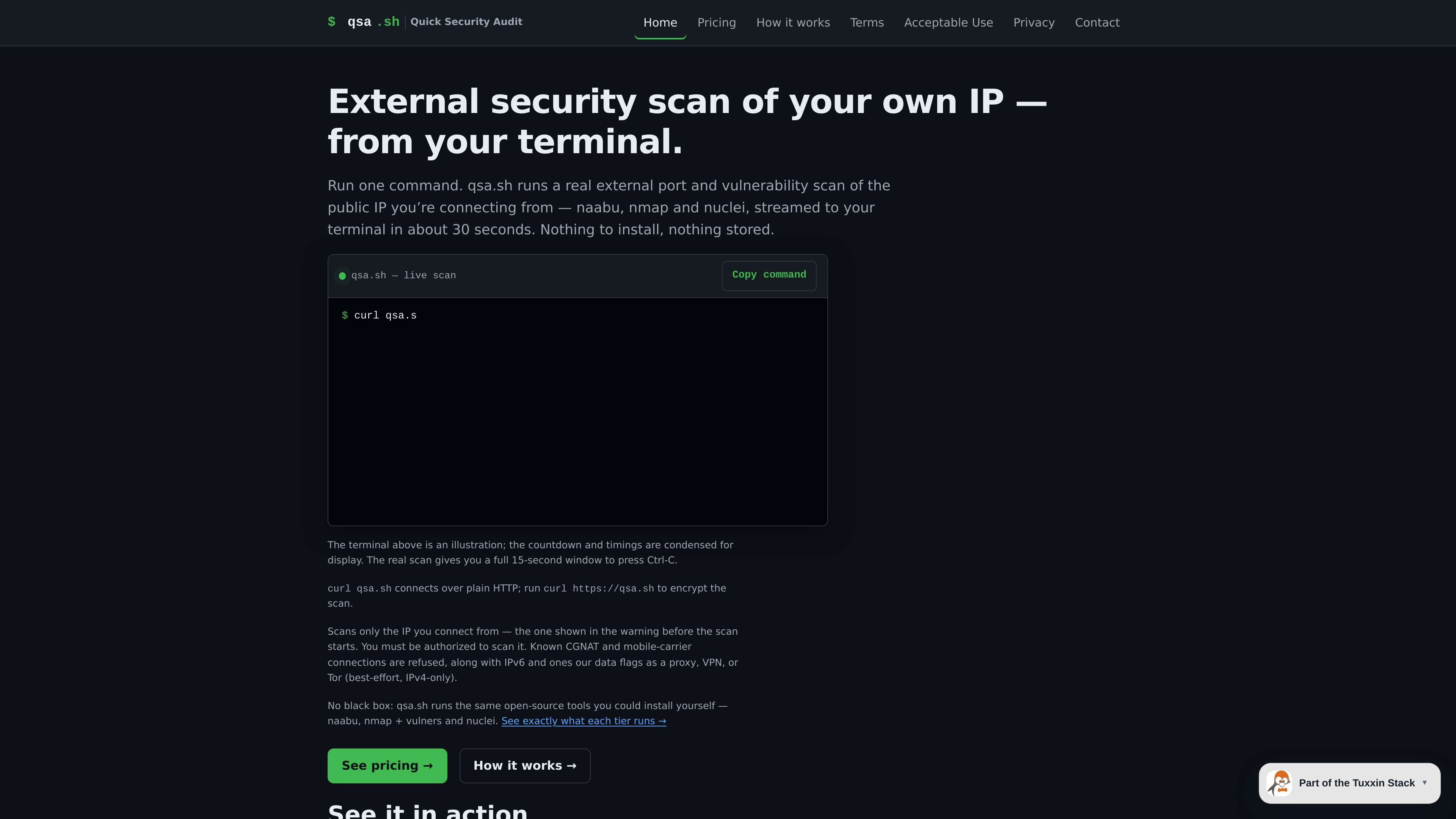
qsa.sh runs an external security scan of the public IP your request comes from, using terminal-streamed results and no local installation. It helps people inspect their own exposed ports and vulnerability signals from the internet-facing side.

Prefactor is an AI agent observability, evaluation, and enforcement platform for teams running agents in production. It records agent steps as spans, evaluates them in real time, and can hold, approve, or block runs based on policy.
HOL Guard is a local safety layer for AI coding agents that reviews risky actions before execution. It supports offline scanning, works without an account on one machine, and can sync decision receipts through Guard Cloud.
Argmin AI helps teams turn their rules, docs, and examples into an AI evaluation they can run before release. It is positioned for product and engineering teams that need quality checks without building custom evaluation code or hiring an ML team.

Box is a cloud sandbox service for agents and developers who need persistent Linux VMs with SSH, Docker, snapshots, and per-machine IPv4. It is designed for CLI and API-driven workflows and supports agents such as Claude Code, Codex, and OpenCode.
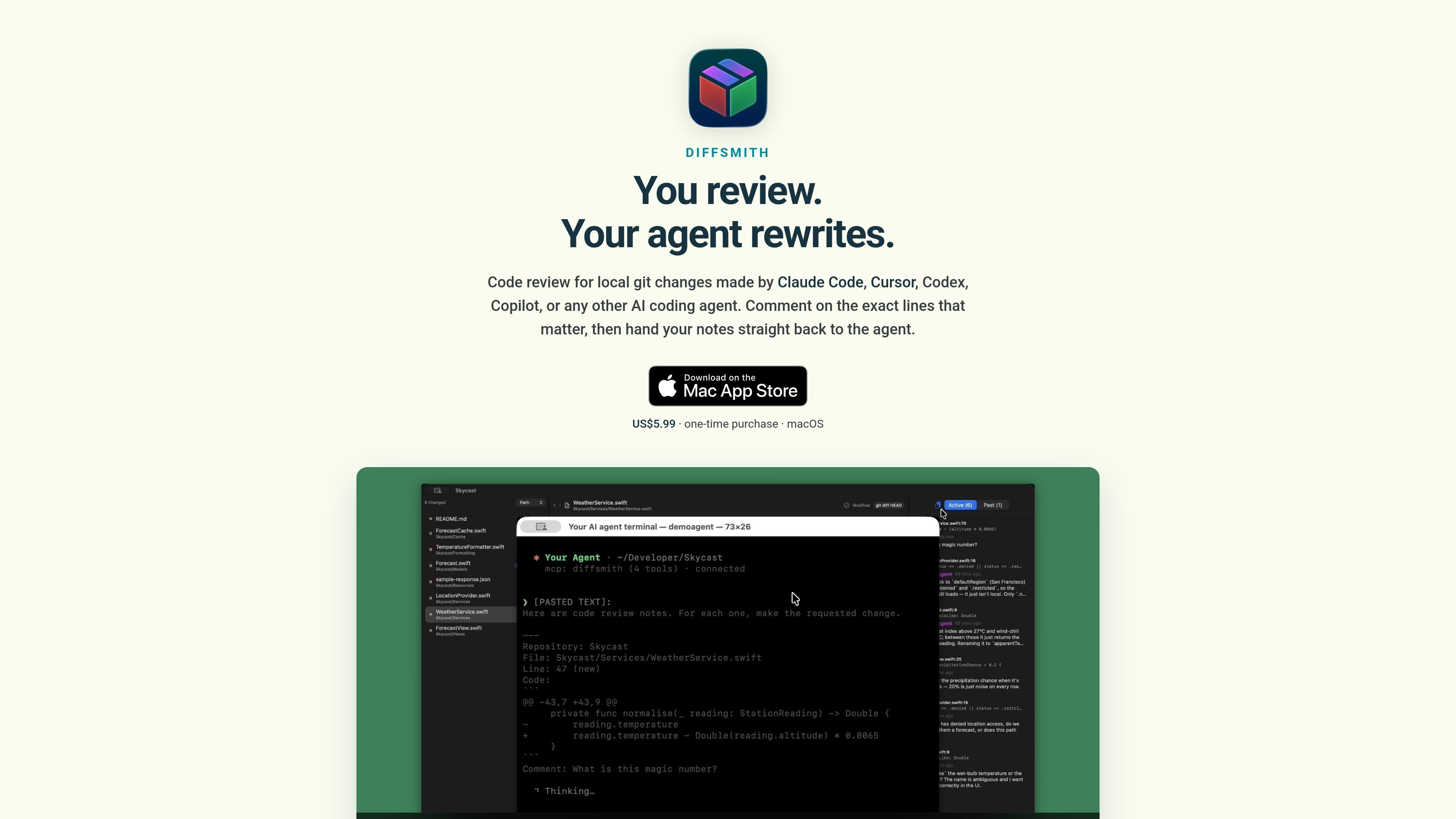
Diffsmith is a native macOS app for reviewing uncommitted code changes made by AI coding agents. It lets you leave inline comments on local git diffs and send feedback back to the agent by prompt or through a local MCP server.

Routebase is an API lifecycle management platform for designing, mocking, testing, documenting, governing, and monitoring APIs from one living spec. It also includes a built-in MCP server so AI agents can work with APIs under team permissions.
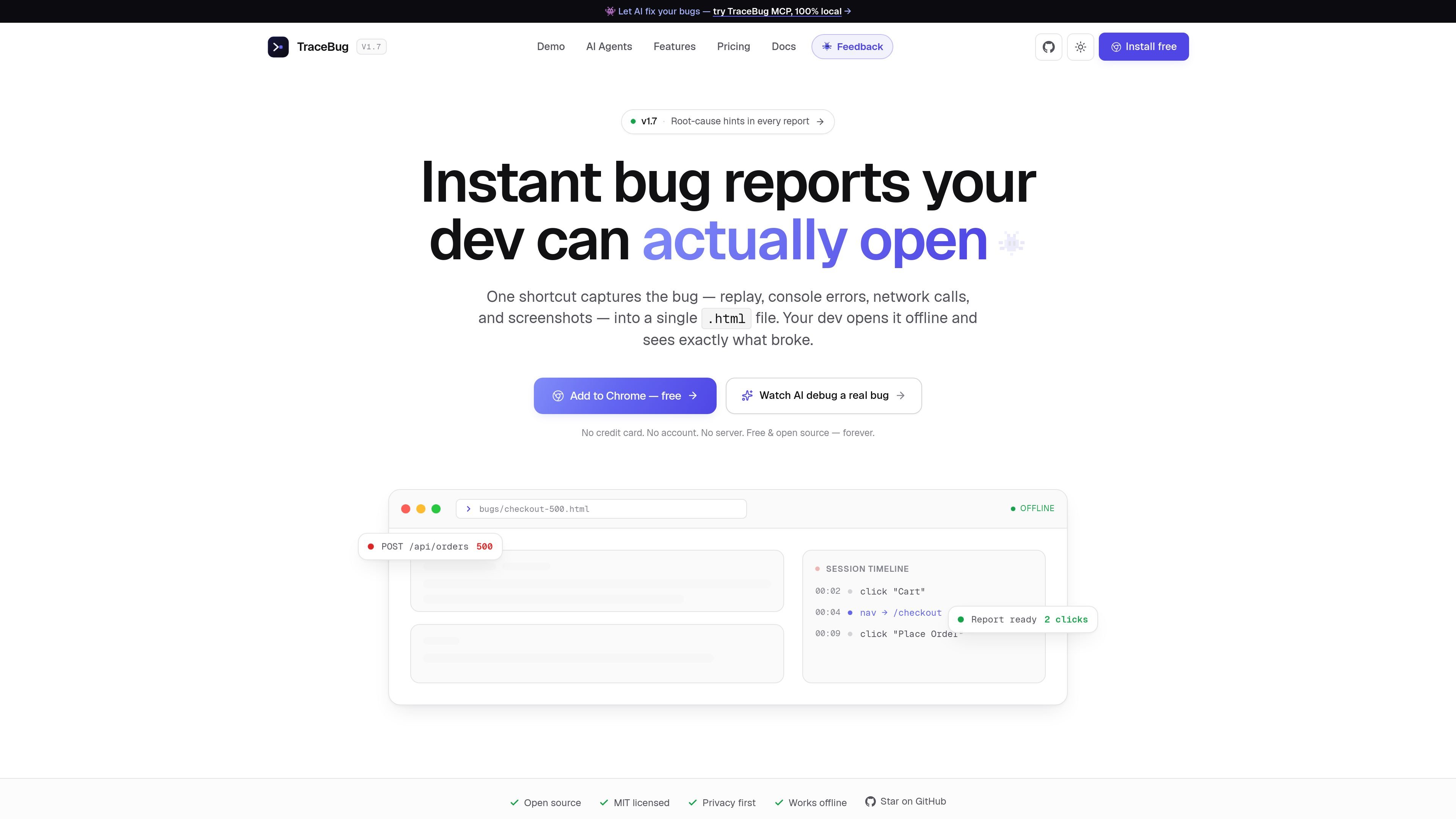
TraceBug is a browser-based bug reporting tool that captures a failing session and exports it as a self-contained HTML report. It helps developers, testers, and AI coding agents inspect replay, console errors, network activity, and screenshots without requiring an account or upload.
Replay QA is an AI-powered QA testing platform for setting up and running quality checks on web apps. It focuses on automated explorations, journey testing, and polish analysis, with setup starting from an app URL.
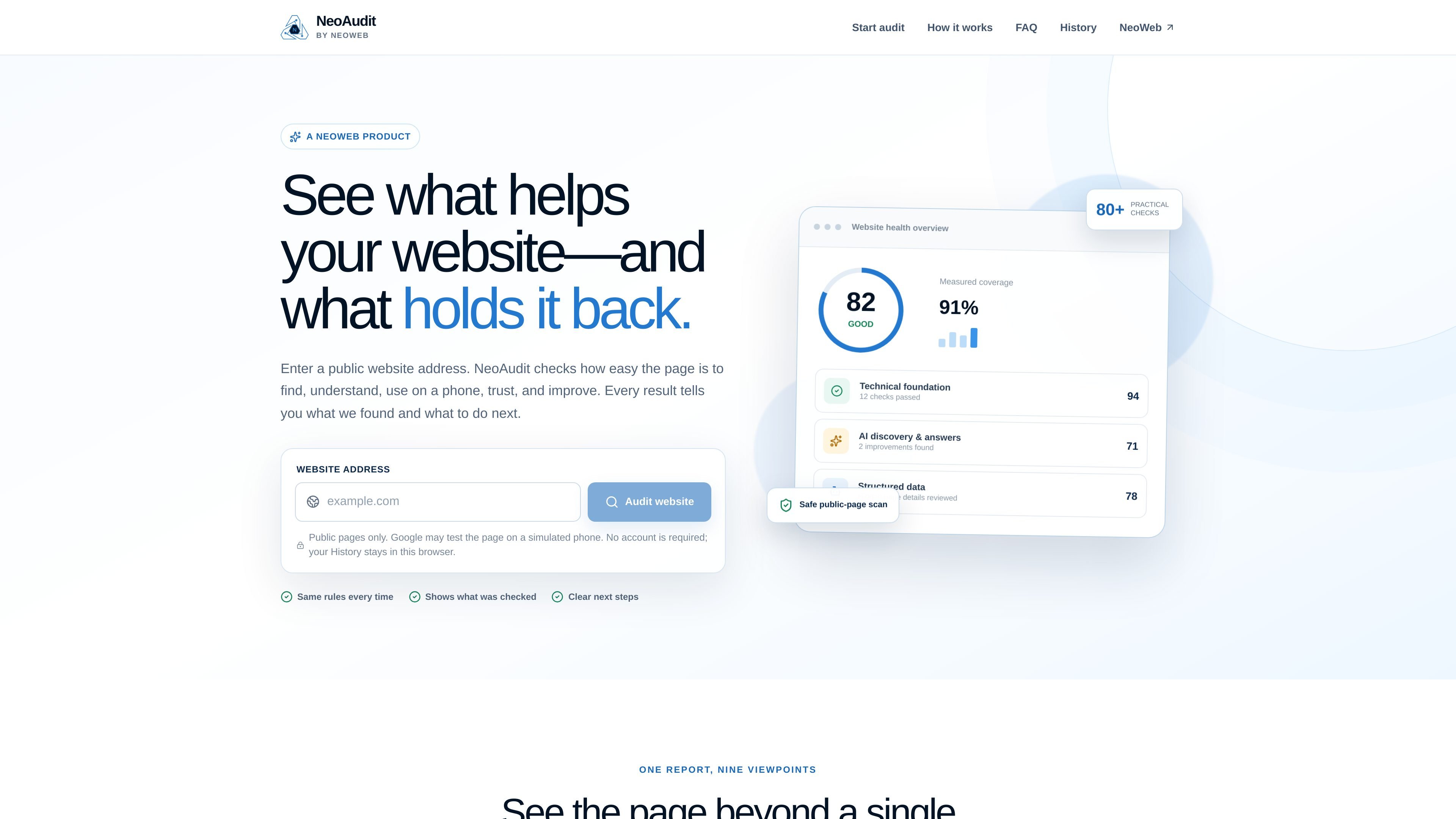
NeoAudit is a public website audit tool from NeoWeb that reviews one page for search visibility, mobile usability, speed, accessibility, AI readiness, trust, and basic protection. It helps website owners and managers identify what to fix next on a public page.
Panguard AI is an AI agent security tool that scans skills and MCP servers for threats before they run and guards agent actions at runtime. It is built for developers, AI vendors, and regulated teams that need local protection and audit-ready evidence.
Isvisible.ai is a free web-based AI visibility audit tool that checks whether a website can be accessed by AI assistants and crawlers. It returns an instant 0-100 score, an agent-by-agent access map, and a downloadable report.
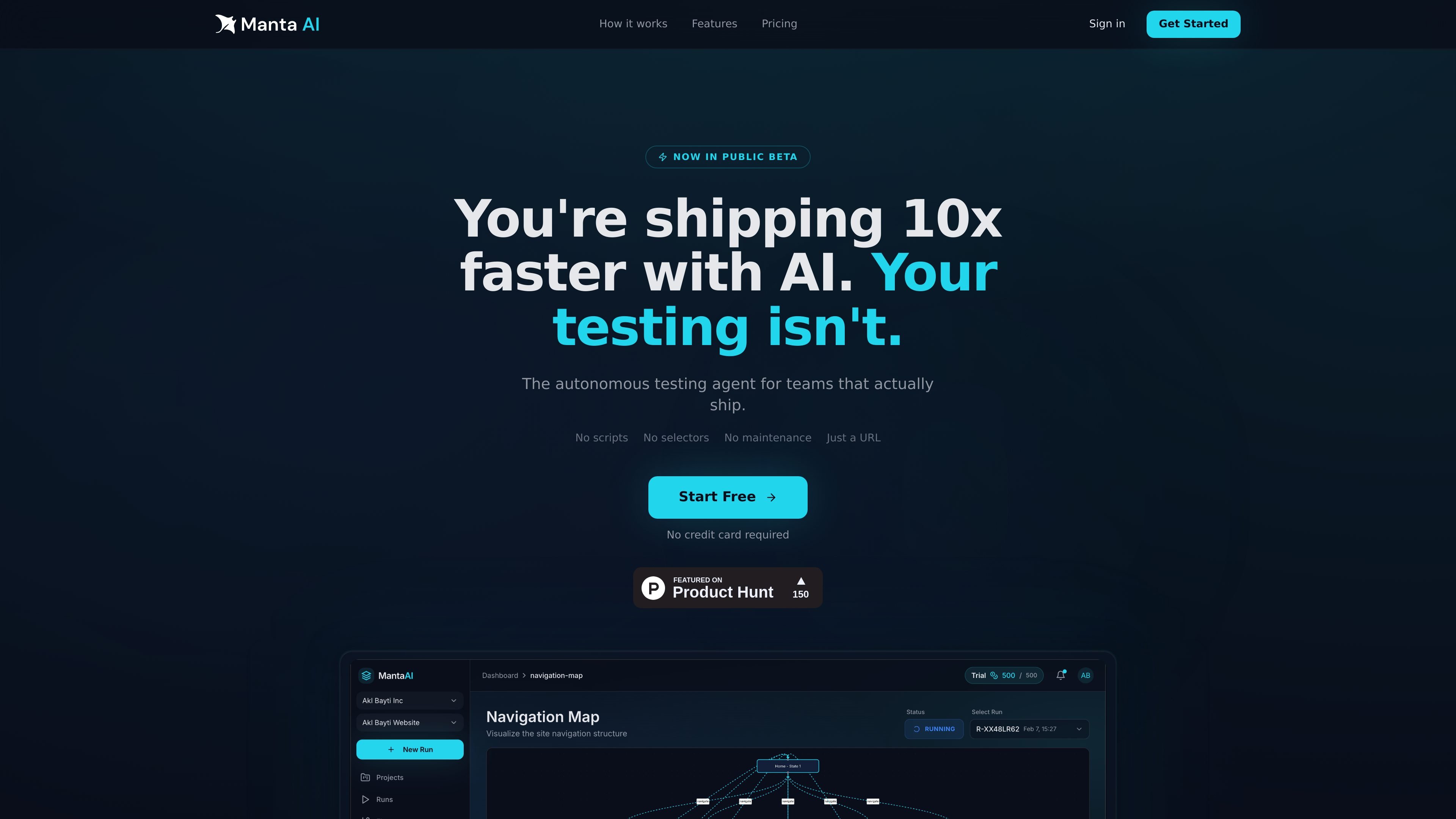
Manta AI is an autonomous web app testing tool for teams that want to map application behavior, catch regressions, and generate tests without writing scripts or maintaining selectors. It works from a URL and supports plain-English test flows, run results with screenshots, and scheduled or deployment-triggered checks.

dot. is a feedback tool for live prototypes and web pages that lets collaborators pin comments directly on a shared URL. It supports a Claude connector workflow and does not require reviewers to sign up.
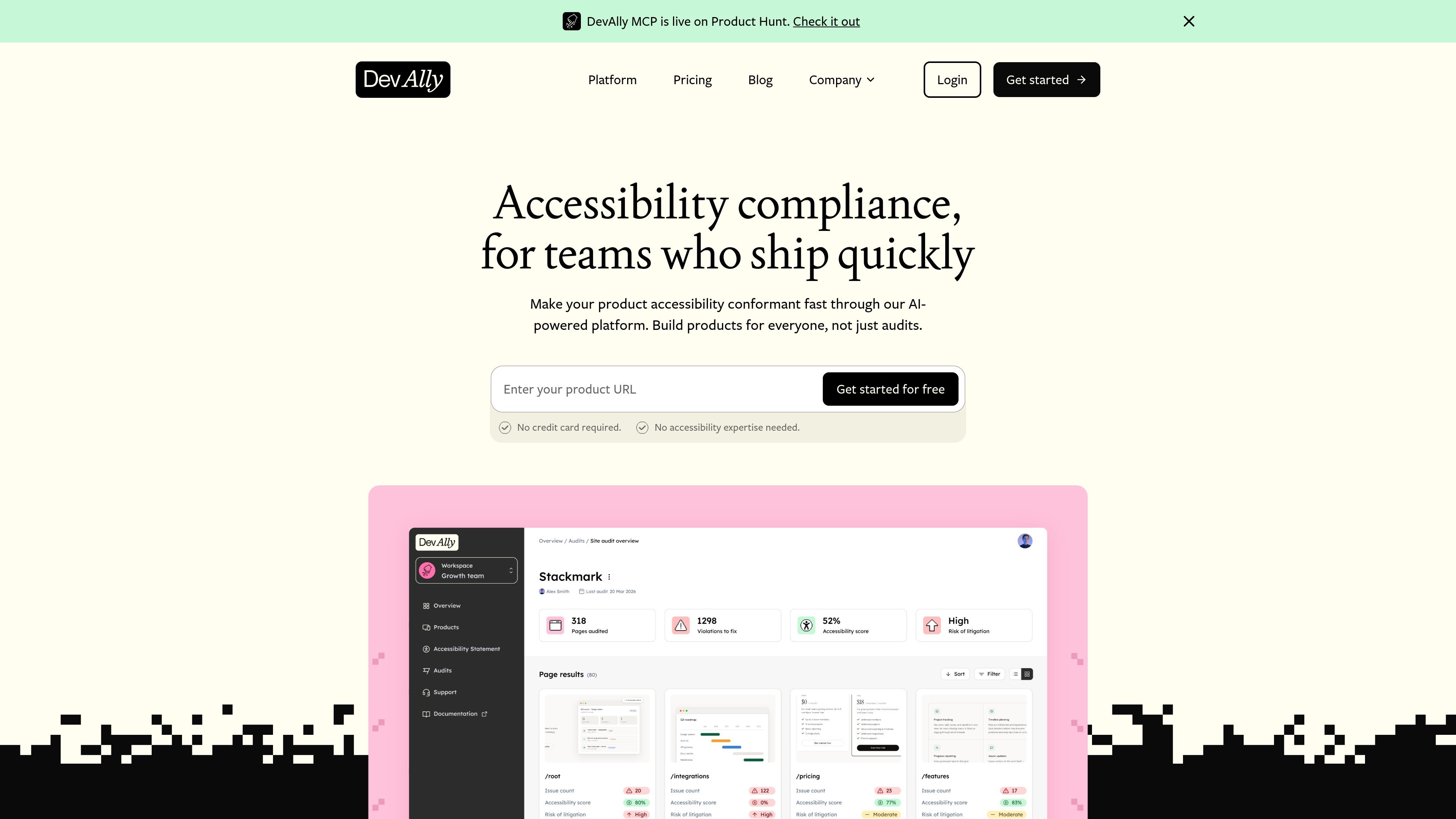
DevAlly is an AI-powered accessibility compliance platform for product teams. It combines automated audits, issue prioritisation, remediation support, and compliance documentation, with free and paid plans.
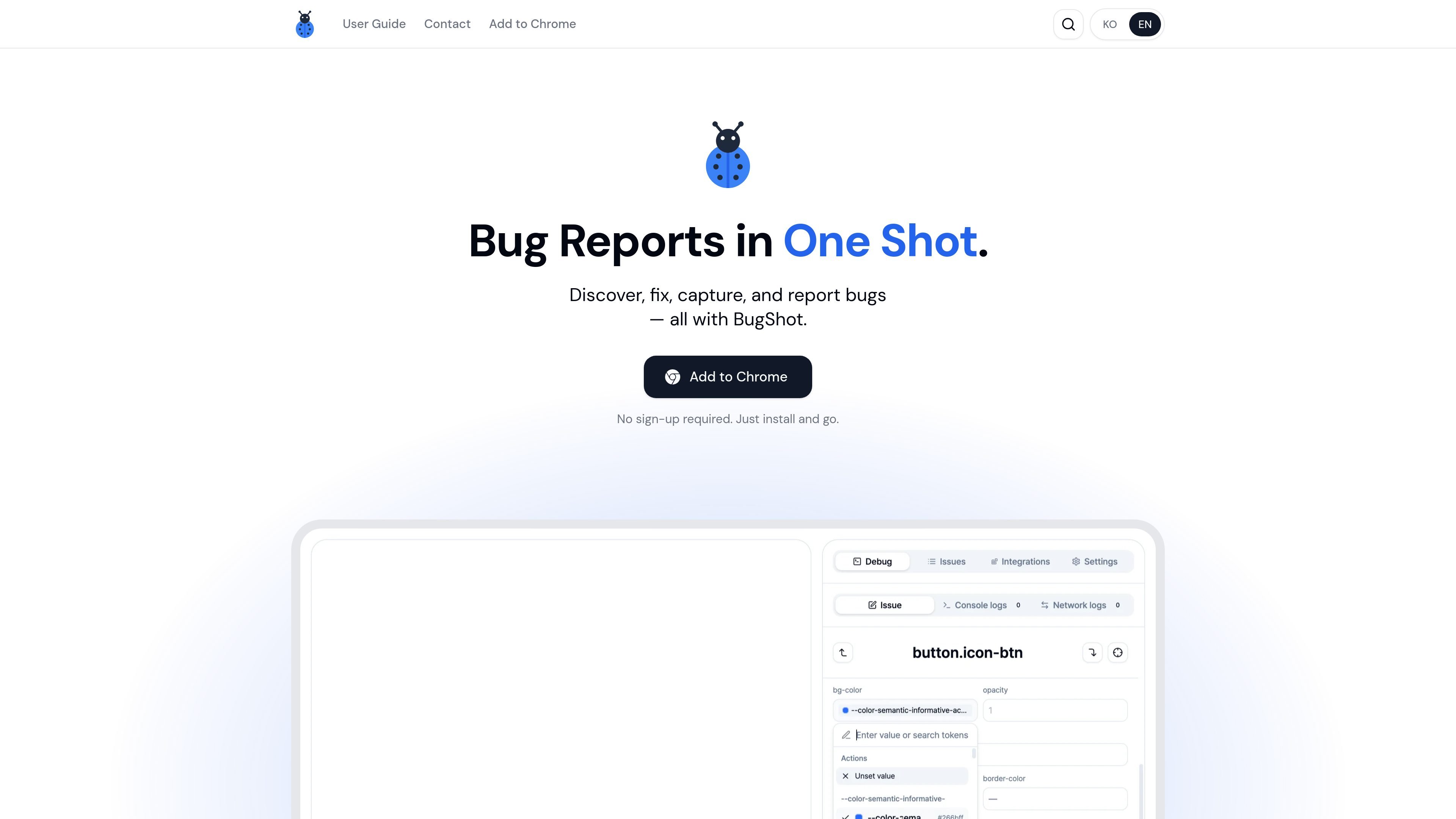
BugShot is a Chrome-based bug reporting tool that combines inspection, capture, replay, and issue filing in one browser workflow. It helps QA, design, and development teams document UI issues with context and send reports to connected trackers.
SandyWP is a WordPress sandbox service that creates real WordPress installs in seconds for testing plugins, themes, bug fixes, and demos. It also supports cloning, Git deploys, CLI/API access, and Slack-based workflows.