Claro
Claro Research Agents가 표 안에서 수동 리서치를 자동화해 목록을 풍부하게 하고 문서에서 구조화 데이터를 추출하며 가격·변경을 모니터링합니다.
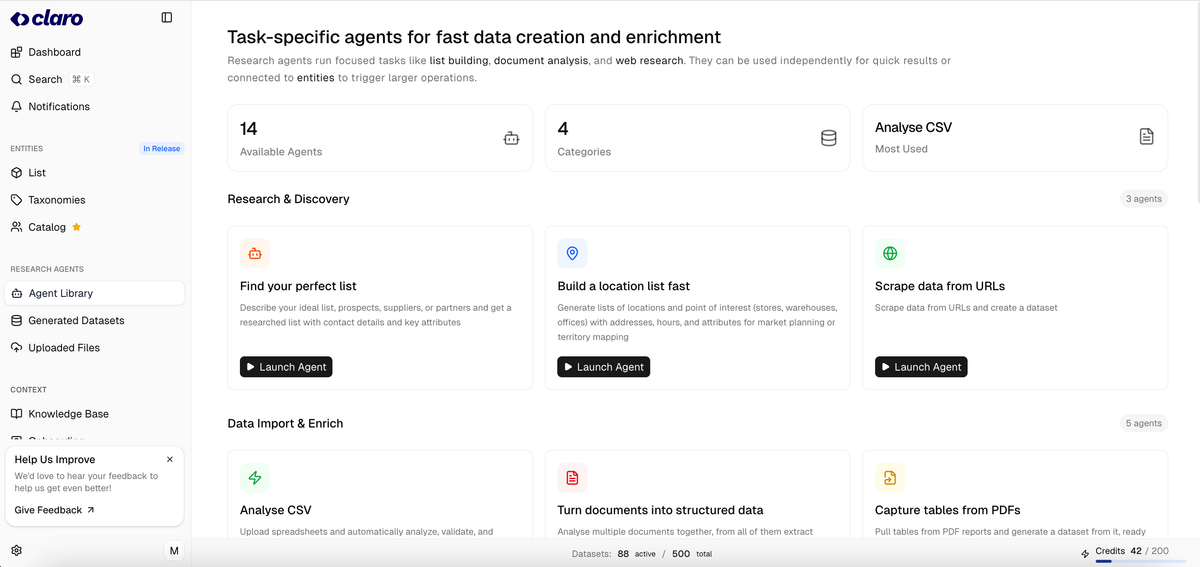
Claro(Research Agents)란 무엇인가요?
Claro의 Research Agents는 테이블 안에서 직접 수동 리서치 작업을 자동화하도록 설계된 AI 리서치 도구입니다. 에이전트는 데이터셋을 생성·풍부하게 하고, 기업을 리서치하며, 가격 등의 변경을 모니터링하고, 문서에서 구조화 데이터를 추출하며, 출력물을 다운스트림 사용에 적합하게 구조화합니다.
이 페이지는 Research Agents를 “독립 실행형”(독립 사용 가능)으로 위치짓되, Claro 안에서 “더 강력”하며 기존 “마스터 테이블” 워크플로와 연동할 수 있다고 설명합니다. 핵심 목적은 리서치 출력을 구조화·추적 가능하게 하고, 팀이 이미 사용하는 동일 데이터셋으로 전달하는 것입니다.
주요 기능
- 네이티브 테이블 워크플로(데이터셋에서 시작): 가져온 CSV, 공급자 카탈로그, 생성된 데이터셋 또는 빈 테이블에서 시작해 리서치 출력을 동일한 테이블 구조 내에 유지합니다.
- 행 기반 실행 및 스케일링 제어: 열을 추가하고 작업을 정의한 후, 작은 샘플(예: 10행) 또는 매우 큰 세트(예: 100,000행)에서 도구 전환 없이 실행합니다.
- 목록 생성 및 풍부화: 웹사이트(설명된 대로) 등의 소스를 스캔해 목록을 구조화 데이터포인트로 풍부하게 합니다.
- 문서 처리로 구조화 추출: PDF나 계약서를 업로드해 테이블 준비 필드로 구조화 데이터를 추출합니다.
- 가격/재고 변경 모니터링: 실시간으로 소스 전반의 가격, 재고, 변경을 추적(설명된 대로)해 데이터셋을 최신 상태로 유지합니다.
- 분류 및 태깅: 테이블 안에서 정의한 커스텀 로직으로 자동 분류 및 태깅합니다.
- Claro 연결 모드로 엔티티 인식 출력: Claro에 연결 시 엔티티 인식 및 표준 ID 정렬로 묘사되며, ERP, PIM, 이커머스, 분석 시스템과의 동기화; 감사 추적 및 리뷰 큐 등의 거버넌스 기능이 있습니다.
Claro(Research Agents) 사용 방법
- 테이블 생성 또는 가져오기: Claro 안에서 가져온 CSV, 공급자 카탈로그, 생성된 데이터셋 또는 빈 테이블로 시작합니다.
- 리서치 작업 선택: 목록 풍부화, 문서 처리/추출, 분류/태깅 또는 모니터링 등의 에이전트 기능을 선택합니다.
- 기준 정의 및 실행: 원하는 출력 열을 추가하고, 자연어로 작업/기준을 설명(해당 시)한 후 선택한 행에서 에이전트를 실행합니다.
- 구조화 출력 검토: 테이블 결과를 사용하고(Claro 연결 시) 감사 추적 및 리뷰 큐 등의 추적성·거버넌스 기능을 활용해 다운스트림 업데이트를 최종화합니다.
사용 사례
- 운영 리서치를 위한 목록 풍부화: 관련 웹사이트를 스캔해 기존 목록을 구조화 데이터포인트로 풍부하게 하고, 결과를 동일 테이블 형식으로 유지합니다.
- 기업 리서치 및 데이터셋 확장: 제공 기준에 따라 기업을 리서치하고, 비구조화 텍스트가 아닌 풍부화·검증된 데이터셋 행을 생성합니다.
- 가격 및 재고 모니터링: 소스 전반의 가격, 재고, 변경을 실시간 모니터링하고 변경 시 데이터셋을 업데이트합니다.
- 계약/PDF 구조화 추출: PDF나 계약서를 업로드해 주요 구조화 필드를 테이블로 추출, 분석 및 다운스트림 처리를 용이하게 합니다.
- 대규모 분류 및 태깅: 커스텀 분류 로직을 적용해 데이터셋 내에서 아이템을 자동 분류·태깅합니다.
자주 묻는 질문
Research Agent를 독립적으로 사용할 수 있나요?
네. 페이지는 Research Agent를 독립적인 구조화 리서치 도구로 사용할 수 있다고 명시합니다.
어떤 입력 형식으로 시작할 수 있나요?
Claro의 Research Agents는 가져온 CSV, 공급자 카탈로그, 생성된 데이터셋 또는 빈 테이블에서 시작할 수 있습니다.
출력물은 어디로 가나요?
출력물은 네이티브 테이블 인터페이스 안에서 직접 실행되며, 테이블 형식의 구조화 결과를 생성합니다(“구조화 입력, 구조화 출력”으로 페이지에 설명).
문서에서 어떤 종류의 데이터를 추출할 수 있나요?
페이지는 PDF나 계약서 업로드를 통해 구조화 데이터를 추출한다고 구체적으로 언급합니다.
Claro에 연결 시 에이전트가 향상되나요?
페이지는 Claro 연결 시 엔티티 인식, 표준 ID 정렬, ERP/PIM/이커머스/분석 시스템 동기화, 감사 추적 및 리뷰 큐 등의 거버넌스 기능을 추가로 설명합니다.
대안
- 범용 AI 추출기 (문서-구조 도구): PDF/계약서에서 필드를 추출하는 것이 주 목적이라면 유용하지만, 테이블 우선·데이터셋 네이티브 워크플로에 최적화되지 않을 수 있습니다.
- 웹 스크래핑 및 ETL 파이프라인: 웹사이트에서 정보를 수집해 데이터 시스템에 로드할 수 있지만, 결과를 검증된 구조화 테이블 출력으로 변환하려면 더 많은 엔지니어링이 필요합니다.
- 데이터 카탈로그/풍부화 플랫폼: 엔티티 데이터를 풍부하게 하고 표준화하는 데 초점; 도구에 따라 데이터 품질 워크플로를 강조하며 테이블 안에서 직접 리서치를 실행하지 않을 수 있습니다.
- 수동 리서치 단계를 포함한 BI 워크플로: 데이터가 준비된 후 분석에 유용하지만, Claro Research Agents에서 설명된 리서치·추출·모니터링 단계를 직접 자동화하지 않습니다.
대안
Happenstance
Happenstance는 Gmail, Google Calendar, Contacts, LinkedIn, Twitter, Instagram, Outlook 등 연결된 네트워크로 사람을 AI 검색해 리서치를 돕습니다.
Bardeen
Bardeen은 사용자가 리드를 효율적으로 소싱, 자격 부여 및 연락하는 데 도움을 주는 AI 기반 웹 스크레이퍼입니다.
Paperpal
Paperpal은 학술 작성을 위한 AI 도구로, 스마트 문헌 읽기·영문 교정/학술 리라이트·작성 구성 생성·투고 전 점검 및 유사도 검사를 지원합니다.
VForms
VForms는 YouTube 동영상 위에 직접 대화형 설문지를 생성하여 매우 맥락적인 피드백과 심층적인 사용자 통찰력을 수집할 수 있도록 지원합니다.
Scite
Scite는 연구자들이 연구 논쟁을 이해하고 신뢰할 수 있는 인용을 보장하며 글쓰기를 개선하는 데 도움을 주는 AI 기반 연구 도구입니다.
DataSieve: Text to Data
DataSieve: Text to Data는 텍스트와 여러 파일에서 이메일, 날짜, URL 등 구조화 정보를 추출하며 iPhone, iPad, Mac에서 완전 오프라인으로 동작합니다.