Lamatic.ai
Toolkit LLM Ops Lamatic.ai com monitoramento de uptime em 18 provedores de API, calculadora de custo com TCO, simulador de roteamento e auditoria de maturidade.
O que é Lamatic.ai?
O Toolkit LLM Ops da Lamatic.ai ajuda as equipes a avaliar e operar múltiplos provedores de LLM com visibilidade de planejamento e operacional em mente. Ele combina ferramentas para estimativa de custos, simulação de roteamento de modelos, monitoramento de uptime de provedores e avaliação de maturidade operacional.
O propósito principal é apoiar a tomada de decisões sobre quais modelos usar, como rotear requisições entre provedores e como quantificar os “custos ocultos” operacionais (como tempo gasto em operações de modelo) junto à confiabilidade observada dos provedores.
Principais Recursos
- Calculadora de custos de LLM e análise de custo real: Estima custos mensais e anuais usando entradas como número de provedores, gasto mensal com API, dimensionamento da equipe de engenharia, tempo alocado a operações de modelo e um multiplicador de TCO para calcular o custo mensal “real” e custo oculto.
- Simulador de roteamento com comparação de estratégias: Simula roteamento de requisições entre diferentes modelos usando parâmetros como volume de requisições, complexidade de requisições e estratégia de roteamento (incluindo conceitos de otimização de custo e priorização de qualidade) para estimar economias de custo e resultados de qualidade/latência.
- Auditoria de diversidade de modelos e maturidade: Avalia a maturidade de LLM Ops usando um conjunto de perguntas direcionadas (exibidas como avaliação de maturidade com recomendações) para guiar os próximos passos.
- Radar de capacidades (visão de comparação de modelos): Exibe uma comparação no estilo radar de capacidades para múltiplos modelos listados, incluindo custo por 1K tokens, pontuação de qualidade e latência.
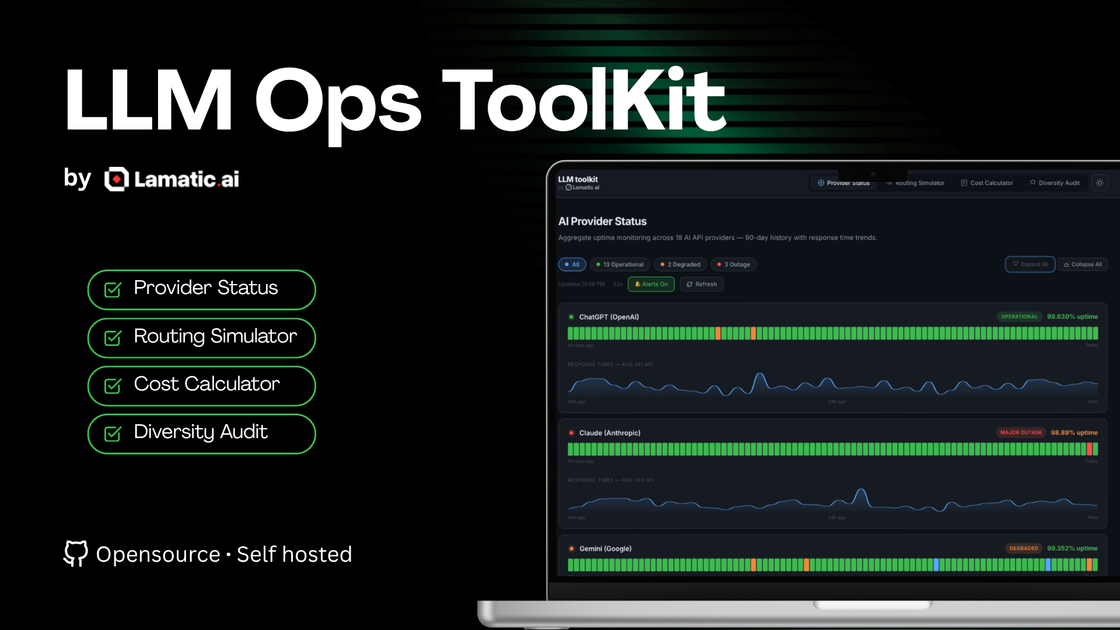
- Monitoramento agregado de uptime em provedores de API de IA: Acompanha o status dos provedores com histórico de 90 dias e tendências de tempo de resposta, incluindo estados operacionais como operacional, degradado e interrupção; inclui controles de notificação de interrupções (indicados por ícone de alerta).
Como Usar o Lamatic.ai
- Comece com suas premissas base na calculadora de custos: defina o número de provedores de LLM, gasto mensal com API, tamanho da equipe de engenharia e a porcentagem de tempo de engenharia gasto em operações de modelo para gerar uma estimativa de “custo real” e custo oculto.
- Execute uma simulação de roteamento: escolha um volume e complexidade de requisições e compare os resultados de estratégias de roteamento (por exemplo, roteamento que prioriza custo versus roteamento que prioriza qualidade) para quantificar economias potenciais e mudanças esperadas em qualidade/latência.
- Avalie a confiabilidade dos provedores usando a visão de monitoramento de uptime para revisar os últimos 90 dias de uptime e tendências de tempo de resposta nos provedores suportados.
- Conclua a auditoria de maturidade respondendo às perguntas direcionadas para revelar próximos passos recomendados e identificar onde seu processo atual de operações de LLM se encaixa no espectro de maturidade.
Casos de Uso
- Planejamento de orçamentos multi-provedor de LLM: Uma equipe pode usar a calculadora de custos para converter faturamento bruto de API em uma visão mais ampla de “custo mensal real” que inclui tempo de engenharia e um multiplicador estimado de TCO, ajudando a justificar investimentos operacionais.
- Avaliação se roteamento pode reduzir gastos: Simulando uma estratégia de roteamento em que parte do tráfego vai para modelos mais baratos, uma equipe de engenharia pode estimar economias anuais potenciais e comparar alocações de roteamento conservadoras versus otimistas.
- Comparação de modelos sob premissas de carga de trabalho: Equipes podem usar o radar de capacidades e o simulador de roteamento juntos para comparar modelos listados por custo de token e latência, validando então como o roteamento impacta a qualidade e latência média sob um perfil de requisição dado.
- Revisão de risco operacional para desempenho de provedores: Usando monitoramento agregado de uptime com histórico de 90 dias, equipes podem revisar tendências de tempo de resposta e interrupções/degradações para informar estratégia de provedores ou planejamento de incidentes.
- Análise de lacunas para maturidade de LLM Ops: Organizações novas em LLMOps ou que já têm ferramentas podem usar a auditoria de maturidade para estruturar melhorias usando a avaliação de capacidades guiada por questionário.
FAQ
-
Quais métricas o toolkit calcula para custo? A página descreve uma análise de custo real que combina gastos mensais de API com tempo de engenharia em operações de modelo e um multiplicador de TCO, produzindo um “custo mensal real” e valores de custos ocultos.
-
Posso simular roteamento entre múltiplos modelos? Sim. O simulador de roteamento foi projetado para visualizar como o roteamento distribui requisições entre modelos e estimar economias de custo e resultados de roteamento.
-
Quais provedores são cobertos pelo monitoramento de uptime? A seção de monitoramento de uptime afirma que cobre 18 provedores de API de IA e fornece um histórico de 90 dias com tendências de tempo de resposta.
-
O que a auditoria de maturidade mede? A auditoria de maturidade é apresentada como uma avaliação usando 10 perguntas direcionadas e gera recomendações ad hoc e uma visualização no estilo de radar de capacidades.
Alternativas
- Ferramentas de custo e contabilidade de tokens para LLM (painéis de custo): Elas focam no uso de API e rastreamento de custo de tokens, mas geralmente não incluem a mesma combinação de modelagem de TCO real, simulação de roteamento, histórico de uptime de provedores e auditoria de maturidade.
- Plataformas gerais de monitoramento de uptime/latência de API: Ferramentas de monitoramento podem rastrear uptime e tempos de resposta para endpoints, mas podem exigir mais configuração para modelar decisões de roteamento LLM e trade-offs de custo/qualidade entre múltiplos provedores de modelos.
- Lógica de roteamento personalizada com análises internas: Equipes podem construir roteamento e avaliação internamente usando sua telemetria; isso pode replicar partes do simulador, mas geralmente exige mais esforço de engenharia para criar comparações de custo/qualidade/latência e visualizações de status histórico de provedores.
Alternativas
ClawTick
ClawTick é uma plataforma de automação de agentes com IA e CLI para agendar tarefas via webhooks em cron, com monitoramento, alertas e logs.
OpenFlags
OpenFlags é um sistema de feature flags open source e self-hosted para progressive delivery, com avaliação local via SDKs e control plane.
skills-janitor
skills-janitor audita, rastreia e compara suas skills do Claude Code com nove ações focadas por comandos slash, sem dependências.
BenchSpan
BenchSpan executa benchmarks de agentes de IA em paralelo, registra scores e falhas em um histórico organizado e facilita reprodutibilidade por commit.
Rectify
Rectify é uma plataforma de operações tudo-em-um para SaaS: monitoramento, analytics, suporte, roadmaps, changelogs e gestão de agentes em um workspace visual por conversa.
PromptScout
PromptScout monitora menções à sua marca, recomendações de concorrentes e fontes citadas em respostas de IA no ChatGPT, Gemini, Google AI Overviews e Perplexity.