Automated evaluation
Run automated checks to measure output quality, safety, and reliability, then review results through shareable visual reports.
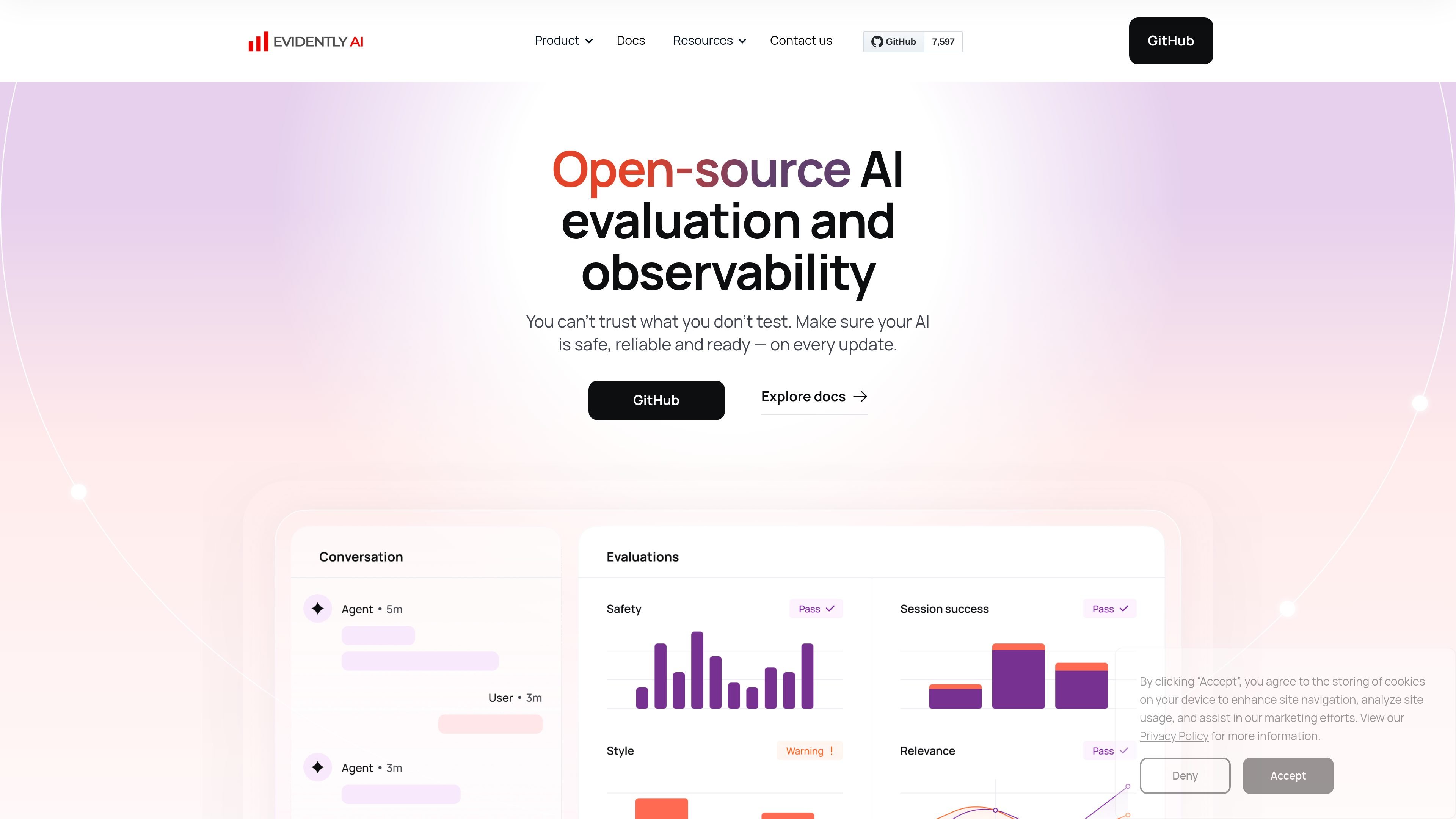
Evidently AI is an open-source platform for evaluating and monitoring LLMs, RAG systems, AI agents, and predictive ML models. It helps teams run tests, generate synthetic data, and track production quality with built-in and custom metrics.
Evidently AI is an open-source AI evaluation and observability platform for LLMs, RAG applications, AI agents, and predictive ML models. The site presents it as a single framework for evaluating, testing, and monitoring AI systems across development and production.
Its core purpose is to help teams check whether AI is safe, reliable, and ready after updates. The product combines automated evaluation, synthetic data generation, and continuous monitoring, with support for visual reports, dashboards, and a library of built-in and custom metrics.
Run automated checks to measure output quality, safety, and reliability, then review results through shareable visual reports.
Generate realistic, edge-case, or adversarial inputs for testing prompts and workflows before or during production use.
Track evaluation results and quality checks over time with a live dashboard to surface drift, regressions, and emerging risks.
Use a library of more than 100 built-in metrics, or combine rules, classifiers, and LLM-based evaluations for custom quality systems.
Evaluate adherence to guidelines, hallucinations and factuality, PII detection, retrieval quality, context relevance, sentiment, toxicity, tone, and trigger words.
Create custom evaluations with any prompt, model, or rule, which lets teams adapt the framework to different AI products.
Evaluate chatbots, copilots, and other LLM-powered products with templates and metrics that cover quality, safety, and factuality.
Measure retrieval quality and context relevance for RAG systems, including checks that help identify grounding issues and answer quality problems.
Run continuous monitoring for production models to detect drift, regressions, and data quality issues after deployment.
Generate edge-case or adversarial test inputs when you need to stress-test prompt handling, safety boundaries, or jailbreak resistance.
Build internal evaluation workflows for teams that want custom tests, metrics, and reports rather than a fixed dashboard-only product.
Evidently AI is positioned for evaluating and monitoring LLMs, RAG applications, AI agents, and predictive ML models in a single open-source framework. The site also highlights guides and courses for teams learning AI observability and MLOps.
The homepage describes automated evaluation, synthetic data generation, and continuous monitoring. It also mentions a library of 100+ built-in metrics and support for custom evals using any prompt, model, or rule.
The source materials point to an open-source offering under Apache 2.0 and do not show pricing numbers. The pricing page promotes the product, resources, and contact options, but does not provide specific plan details in the collected text.
Yes. The site specifically calls out evaluation for LLM-powered systems such as chatbots, RAG applications, AI agents, and copilots, as well as predictive ML systems.
The collected pages do not list a supported integration matrix. One testimonial mentions MLflow, but the site text in scope does not provide a full integrations page or API list.
Benchspan is an AI agent security platform that discovers agents, blocks prompt injection and data exfiltration in real time, and supports pre-launch red teaming. It is aimed at teams running agents in production and includes Python and TypeScript SDKs.
ByteAsk is a terminal-first AI coding agent for C and C++ that edits repositories and verifies changes with the real compiler, debugger, sanitizers, and tests before showing a diff. It offers a free tier plus paid plans, with editor connectors and zero-retention handling described in the source.
PromptScout tracks how ChatGPT, Gemini, Google AI Overviews, and Perplexity mention your brand or competitors, then pairs those results with source analysis and website audits. It helps teams decide what to fix in content, positioning, or site readiness next.
Sleek Analytics is a privacy-friendly web analytics tool with real-time visitor tracking, Core Web Vitals, and revenue attribution. It helps site owners understand traffic and conversions without cookie banners or a heavy setup.
MacSpoof — смена MAC-адреса в macOS: меняйте или рандомизируйте Wi‑Fi MAC, чтобы переподключаться и меньше светить идентификатор в публичных сетях.
Manta AI is an autonomous web app testing tool for teams that want to map application behavior, catch regressions, and generate tests without writing scripts or maintaining selectors. It works from a URL and supports plain-English test flows, run results with screenshots, and scheduled or deployment-triggered checks.