SemanticGuard
SemanticGuard — AI gateway с self-validating cache для LLM API OpenAI, Anthropic и Google: помогает измерять экономию и сохранять поток запросов.
Что такое SemanticGuard?
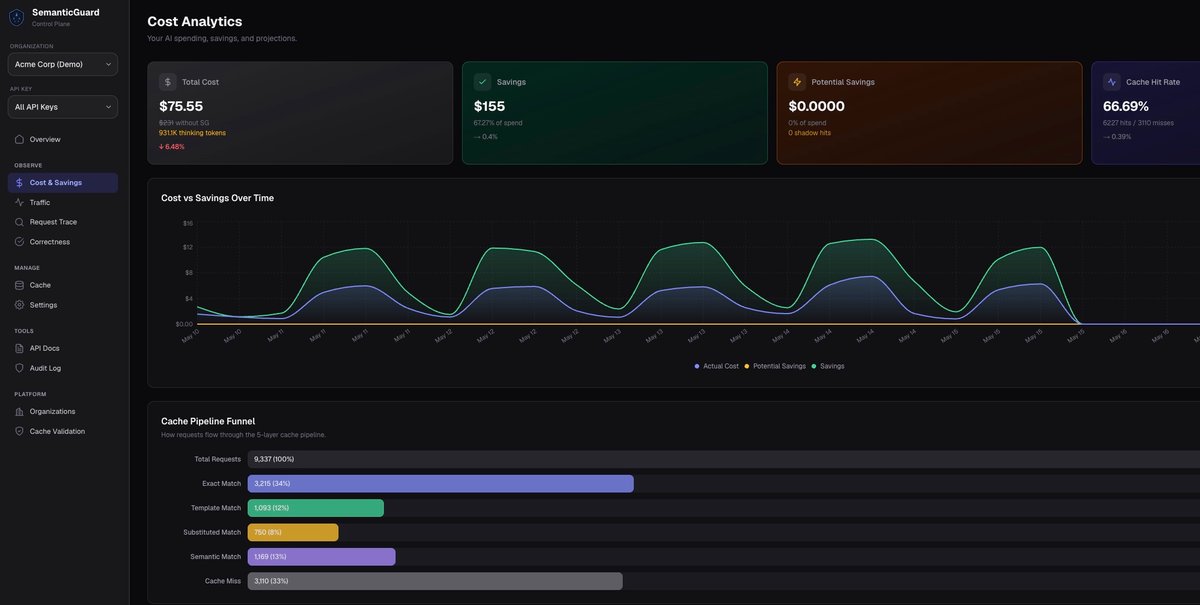
SemanticGuard — это AI gateway и self-validating cache для LLM API. Он находится в пути запросов для таких провайдеров, как OpenAI, Anthropic и Google, кэшируя ответы и используя многоуровневую проверку, чтобы определить, остается ли сохраненный ответ корректным.
Продукт создан для снижения затрат на LLM API без необходимости менять промпты или вручную управлять объектами кэша. Также он включает Shadow Mode, который измеряет потенциальную экономию до включения кэширования, и поддерживает fail-open дизайн, чтобы запросы продолжали идти к upstream-провайдеру, если кэш недоступен.
Ключевые возможности
- Интеграция SDK в одну строку через
fetch: withSemanticGuard()в AI SDK, что позволяет командам добавить кэширование без переписывания логики приложения. - Измерение в Shadow Mode, показывающее стоимость каждого запроса, прогнозируемую экономию, типы попаданий и то, где трафик был бы закэширован, прежде чем начинать отдавать кэшированные ответы.
- Попадания в self-validating cache с многоуровневой проверкой, при этом часть попаданий также оценивается ИИ на корректность, а ошибки помечаются.
- Поддержка разных провайдеров: OpenAI, Anthropic, Google и других указанных провайдеров, таких как Azure, Bedrock и Mistral.
- Поведение кэша, настроенное на семантические совпадения, так что запросы с разными именами, датами или ID все равно могут совпадать, если ответ по сути тот же.
- Обработка запросов по принципу fail-open: трафик отправляется напрямую провайдеру, если кэш недоступен.
- Указанные на сайте меры безопасности, включая шифрование при передаче и хранении, опциональное хранение промптов и передачу upstream API keys в момент запроса, а не их хранение.
Как использовать SemanticGuard
Разработчики добавляют SemanticGuard в конфигурацию своего AI SDK, оборачивая fetch-слой с помощью withSemanticGuard(), а затем отправляют запросы как обычно. Показанный на сайте сценарий начинается с Shadow Mode, чтобы измерить экономию и увидеть, как классифицировался бы трафик.
Когда команда удовлетворена результатами, можно включить кэширование. После этого кэшированные ответы будут возвращаться автоматически, а в dashboard можно будет просматривать экономию, hit rate и результаты валидации.
Сценарии использования
- Снижение затрат в высоконагруженных LLM-приложениях, где многие пользователи задают пересекающиеся вопросы, а повторяющиеся ответы можно переиспользовать.
- Оценка экономики кэширования до запуска, особенно для команд, которые хотят количественно измерить экономию, не начиная сразу выдавать кэшированный результат.
- Обслуживание семантически похожих запросов, которые отличаются поверхностными деталями, такими как имена, даты или ID, где byte-identical кэширование у провайдера не сработало бы.
- Поддержка AI-стеков с несколькими провайдерами, которым нужен единый слой кэширования между разными вендорами моделей.
- Обеспечение доступности для production-приложений, которым нужен fallback-путь на случай недоступности слоя кэширования.
FAQ
Требует ли SemanticGuard изменений в промптах? Нет. На сайте описана интеграция SDK в одну строку и сказано, что изменения промптов не нужны.
Можно ли проверить экономию до включения cache hits? Да. SemanticGuard включает Shadow Mode, который измеряет, сколько вы сэкономите, до того как начнутся выдачи кэшированных ответов.
Работает ли это более чем с одним провайдером моделей? Да. На странице перечислены OpenAI, Anthropic, Google, а также указана совместимость с другими провайдерами, такими как Azure, Bedrock и Mistral.
Что происходит, если кэш недоступен? Продукт описан как fail-open, то есть запросы идут напрямую к провайдеру.
Это продукт только для exact-match кэширования? Нет. На странице SemanticGuard позиционируется как semantic caching, рассчитанный на запросы с одинаковым смыслом, даже если детали вроде имен, дат или ID меняются.
Альтернативы
- Нативное кэширование промптов у провайдера, например встроенное кэширование от OpenAI или аналогичных вендоров. Обычно оно ограничено точным или почти точным повторным использованием префикса внутри собственной системы провайдера и лучше подходит для статических сегментов промпта.
- Ручные слои кэша внутри приложения или proxy. Их можно настраивать, но обычно они требуют больше инженерной работы для определения cache keys, управления invalidation и проверки корректности.
- Общие AI gateway без semantic validation. Они могут отвечать за routing, observability или enforcement политик, но не обязательно фокусируются на кэшировании с проверкой корректности.
- Прямое использование провайдера без слоя кэширования. Это самая простая схема, но она не дает повторного использования для похожих запросов и workflow для предварительного измерения экономии до запуска.
Альтернативы
AakarDev AI
AakarDev AI — это мощная платформа, которая упрощает разработку приложений ИИ с бесшовной интеграцией векторных баз данных, позволяя быстрое развертывание и масштабируемость.
Ably Chat
Ably Chat — chat API и SDK для кастомных realtime-приложений: реакции, presence и правка/удаление сообщений для чатов в масштабе.
BookAI.chat
BookAI позволяет вам общаться с вашими книгами, просто предоставив название и автора.
DeepMotion
DeepMotion — платформа ИИ для motion capture и body-tracking: создавайте 3D-анимации из видео (и текста) в браузере; интеграция через Animate 3D API.
skills-janitor
skills-janitor для Claude Code: аудит и учет навыков, сравнение с девятью командами /janitor-* и поиск дублей без зависимостей.
Arduino VENTUNO Q
Arduino VENTUNO Q — edge AI компьютер для робототехники: ускоренный вывод нейросетей и микроконтроллер для детерминированного управления. Через Arduino App Lab.