系统提示加固
加固的系统提示提供基础政策,而 Focus Guardrail 会在整个对话中强化这些指令,以减少长时间或复杂交互中的偏离。
Guardrails 2.0 是 ElevenLabs 为 ElevenAgents 提供的控制层,旨在让语音代理与团队的指令、安全规则和运营目标保持一致。它在代理行为周围增加多层检查,帮助团队减少偏离、捕捉操控尝试,并在违规回复到达用户之前进行拦截。
该产品面向支持、销售、营销和内部流程中的生产级语音代理部署。其控制项可以在代理设置中配置,也可以通过 API 配置;页面将其定位为企业部署中更广泛的信任与安全栈的一部分,包括 conversation analytics、可选的 zero-retention 模式,以及面向符合条件客户的通话后脱敏。
加固的系统提示提供基础政策,而 Focus Guardrail 会在整个对话中强化这些指令,以减少长时间或复杂交互中的偏离。
会检查用户输入是否存在提示注入和覆盖指令的尝试,并可选择终止构成安全风险的对话。
每条回复都会在到达用户之前接受已配置政策的评估,从而实时拦截不安全或偏题输出。
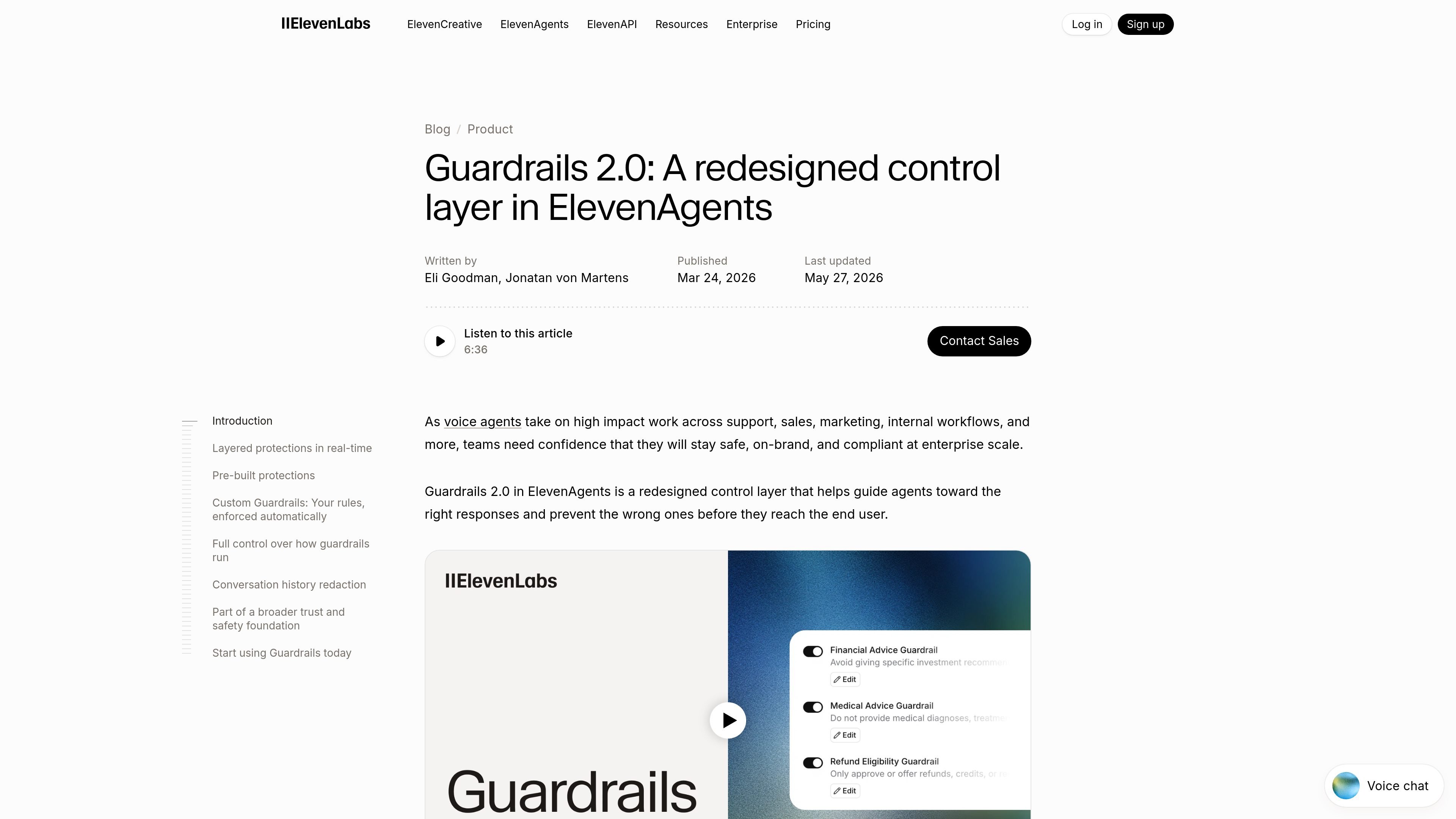
Custom Guardrails 允许团队用自然语言编写特定领域规则,并通过 block-or-allow 决策在每次通话中自动执行。
执行模式、退出策略、内容敏感度以及按 guardrail 的开关,让团队能够控制执行有多严格,以及触发后会发生什么。
触发器和动作会记录在 conversation analytics 中,敏感信息还可在通话结束后从转录、录音和 webhook payload 中脱敏。
当语音代理需要在冗长或复杂的通话中保持按脚本执行时使用 Guardrails 2.0,例如支持或入门引导对话,这类场景中的偏离可能导致错误答案。
在面向客户的工作流中应用操控和回复检查,因为用户可能尝试覆盖指令,或诱导模型进入不安全行为。
使用自定义 guardrails 来执行公司特定政策,例如升级规则、禁用话题或受监管的语言要求。
为实时语音交互配置退出策略和敏感度级别,当团队希望对低风险和高风险问题采用不同处理方式时尤其有用。
将日志记录和脱敏与通话后的 QA 流程结合,在保留转录和录音以供审查的同时,从存储产物中移除敏感细节。
Guardrails 2.0 配置在 ElevenAgents 中。页面说明,你可以在代理设置的 Security 选项卡中开启它们,或通过 API 进行配置。
页面将其描述为三个层级:系统提示加固、用户输入验证和代理响应验证。这些机制协同工作,用于强化指令、检测操控尝试,并在回复发送前拦截违反政策的内容。
页面说明,自定义 guardrails 允许你用自然语言定义特定领域的政策,并在每次通话中自动执行。一个轻量级模型会评估每个回复,并返回 block 或 allow 决策。
可以。页面说明,执行模式让你可以选择让 guardrails 与回复并行运行以实现接近零延迟,或者在回复完全通过检查前先暂存。它还提到,你可以定义退出策略,例如结束对话、转接到另一个代理、升级给人工,或使用纠正性指令重新尝试。
对话历史脱敏和 Zero Retention Mode 被描述为企业客户可用。页面引导客户联系销售获取访问权限。
Wallie 是一款开源 AI 直播助手,能观看屏幕、聆听聊天并以可配置人设生成实时解说。支持本地运行、使用自有密钥,适合无真人出镜内容、自动化直播和实时互动。
CreateOS Sandbox 是基于 Firecracker 微型虚拟机的隔离计算环境,用于运行代码和 agent 工作负载,支持私有网络、SDK、CLI 和 MCP 程序化控制。
Codex Plugins 将可复用技能、应用集成和 MCP 服务器打包为工作流,可在 Codex 应用中安装或通过 Codex CLI 使用,帮助扩展连接服务任务、复用指令和团队共享流程。
一个集成图像、视频、语音、写作和聊天工具的全能AI平台,以增强创造力和协作。
Gemma AI 是一款电话提醒应用,会按计划给你打电话提醒,而不是推送通知。支持 Google Calendar 同步与自然对话式通话交互,帮助你更直接地按时安排。
CAMB.AI Streams 可为 YouTube、Twitch、X 等直播平台提供多语言实时配音,接入现有直播流程,支持常用流媒体协议,无需后期制作。