Loading...
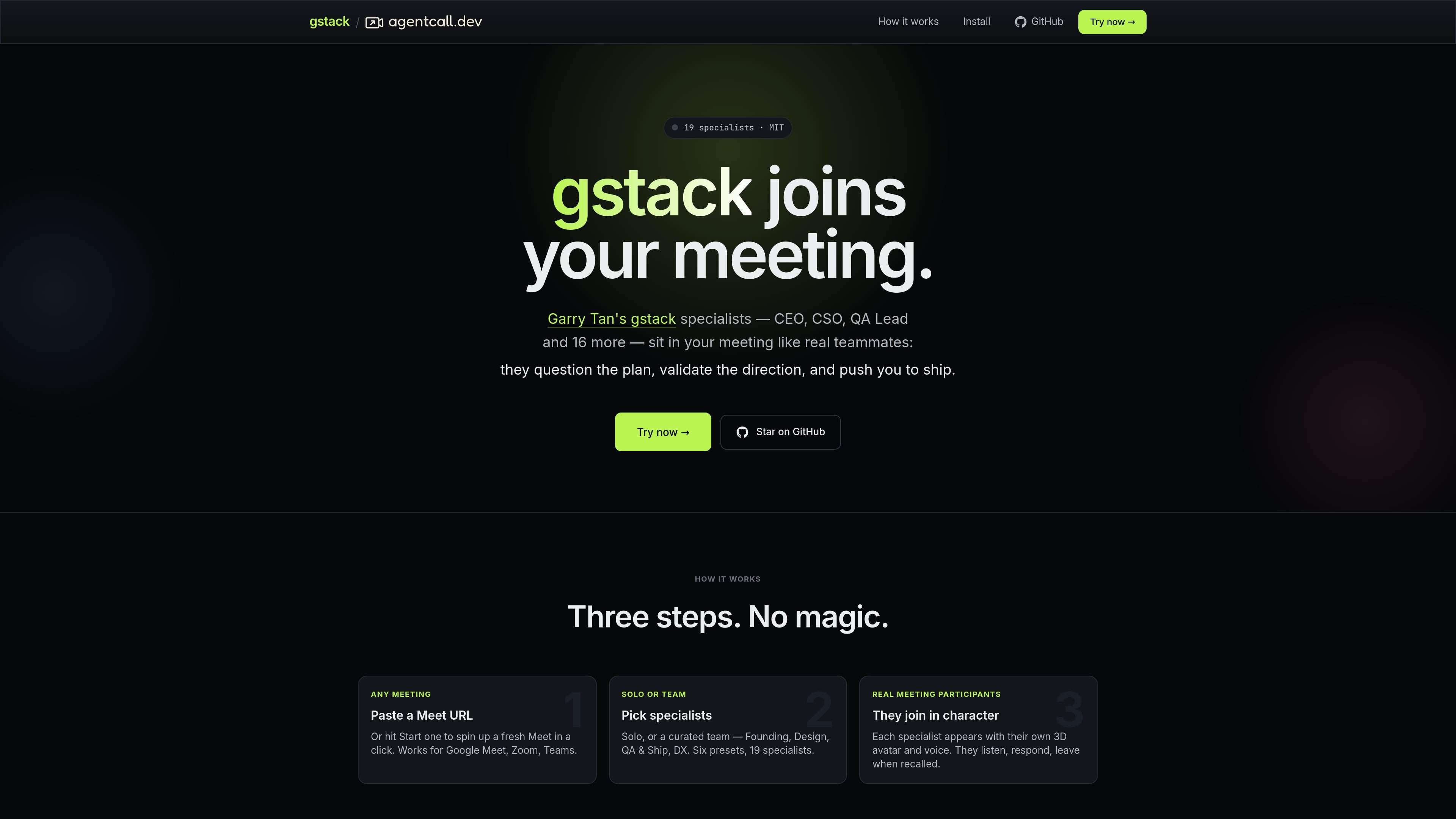
gstack 将 Garry Tan 的开源专家角色以语音机器人形式接入实时会议,支持 Google Meet,并提到可用于 Zoom 和 Teams,通过本地编码代理会话运行。

PodcastorAI 是一款 AI 播客工作室,可将内容转为播客脚本、音频节目和视频播客。支持话题、文档、URL、笔记或录音,一站式生成可发布节目,无需传统录音棚。
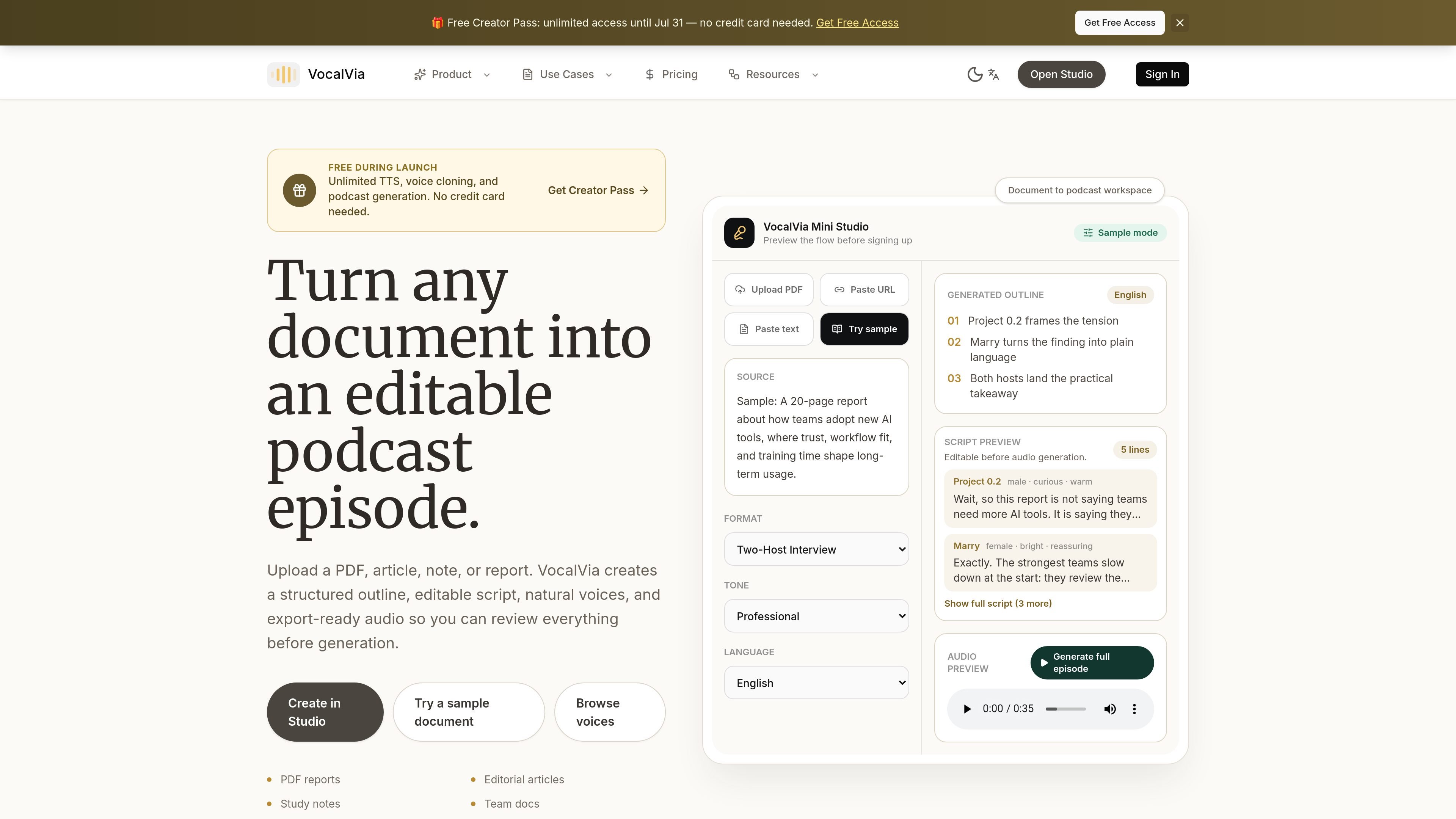
VocalVia 将 PDF、文章、笔记、Markdown 和网页内容转换为可编辑播客草稿与音频,先审阅大纲和脚本再生成最终文件。
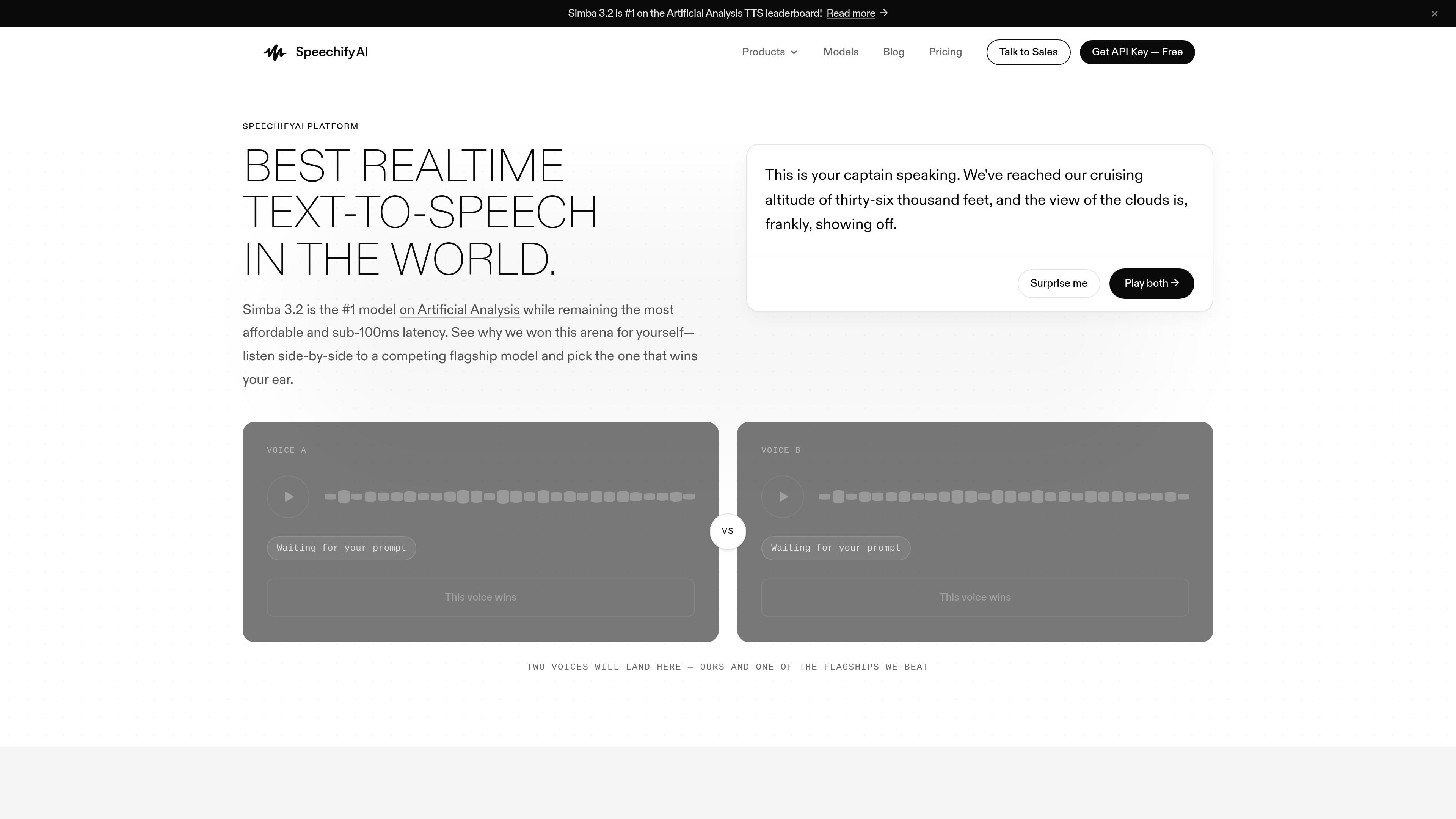
SpeechifyAI 是一个语音 AI 平台,支持语音生成、声音克隆和语音代理构建。面向开发者,通过单一 API 提供文本转语音、多语言音频和通话工作流。
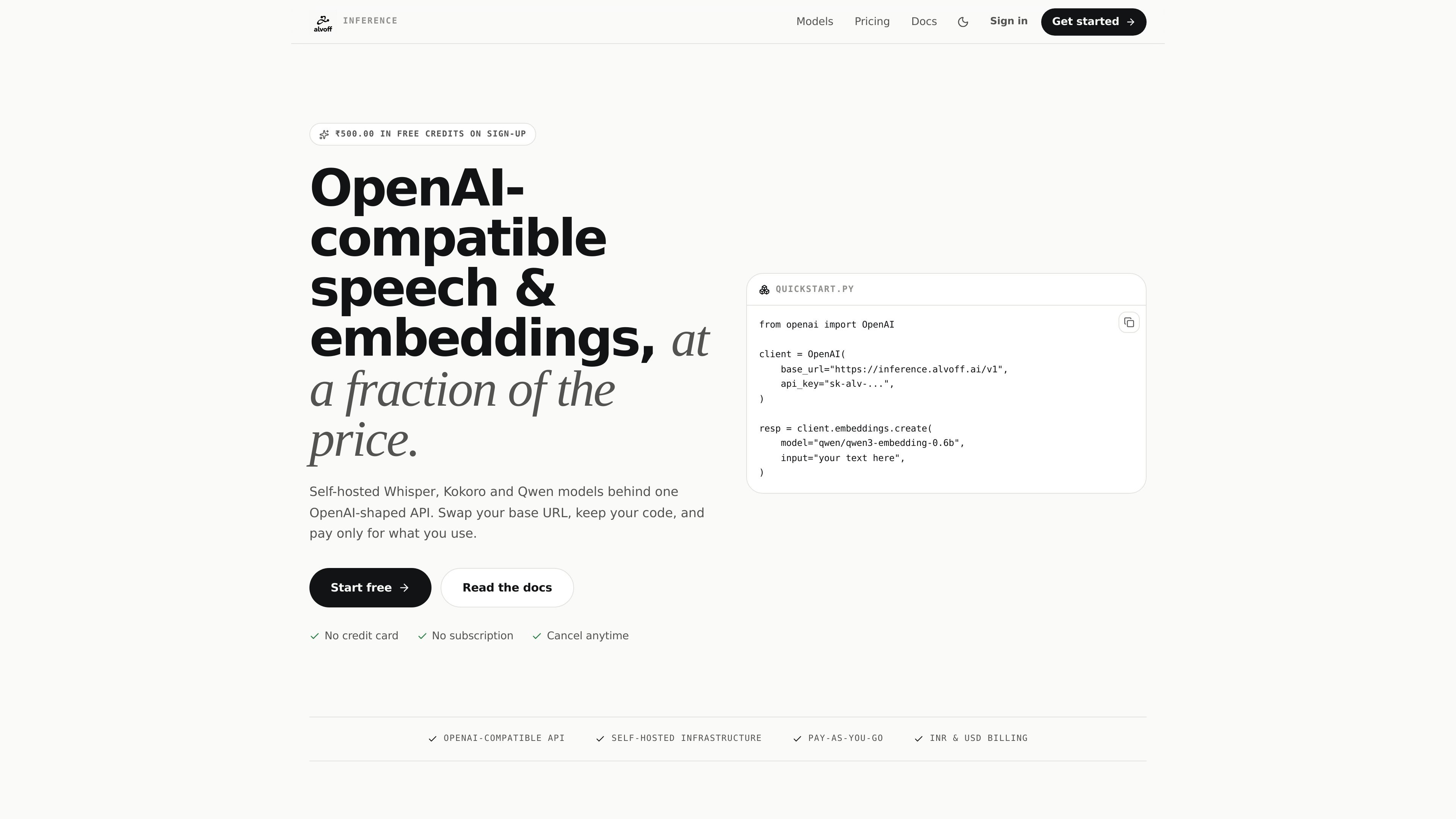
Alvoff Inference 是面向开发者的 OpenAI 兼容 API,支持语音转文字、文字转语音、embeddings 和聊天/代码生成;只需更换基础 URL,即可沿用熟悉的 SDK,按请求计费。
speech-core 是一款用于本地端语音编排的 C++17 库,支持 VAD、流式与批量 STT、说话人分离、TTS 和语音代理流水线。可本地运行,支持可选 ONNX Runtime 或 LiteRT 后端进行模型推理。

Voiser AI Voiceover 可将文本快速转为配音音频,支持多语言语音选项与风格控制,适合旁白制作、内容本地化及网页工作流。
Tico 是一款适用于 Windows 的 AI 助手,能跟随鼠标指针、识别屏幕内容并用语音引导操作。支持免费每日额度及付费方案,提供更多使用次数与优先支持。
Yeta AI 是一款基于浏览器的 AI 配音工具,可实时翻译并为公开 YouTube 视频配音,适合教程、讲座等长视频观看,支持 10 多种语言,无需字幕。

Morph 是一款基于网页的经典公版读物平台,融合文本、同步朗读和 AI 助手,支持阅读、听读切换,并可浏览精选书库和获取书籍帮助。
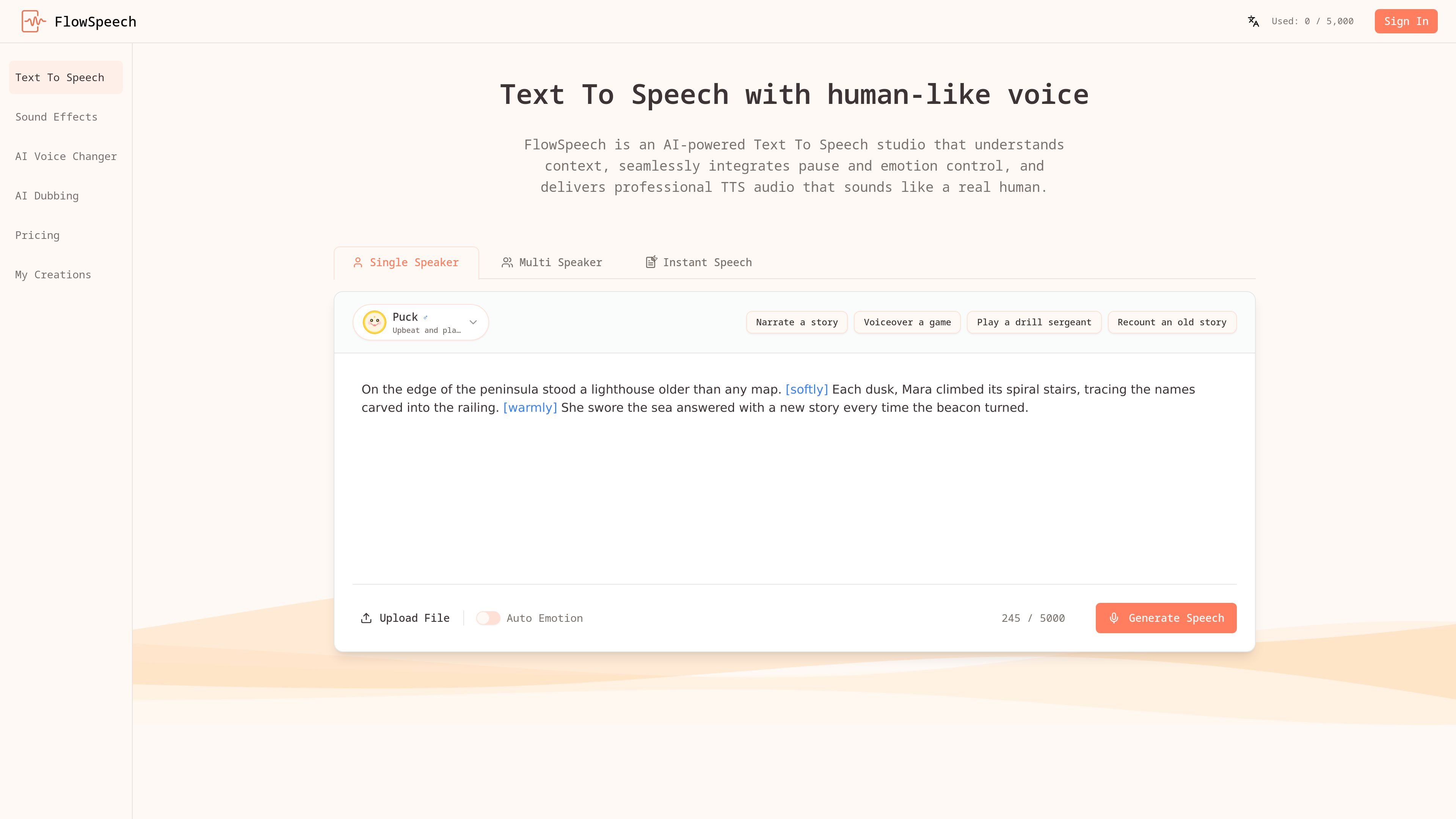
FlowSpeech 是一款上下文感知的文本转语音工作室,可将脚本和上传文件转为自然人声。支持多种生成模式、停顿与情绪控制,并提供免费方案及付费套餐。
xAI 的 Grok Speech to Text and Text to Speech APIs 为应用提供转录与语音生成,支持 REST 和 WebSocket、25+语言、自然 TTS,以及按用量计费。

Gemini 3.1 Flash TTS 是 Google 的预览版文本转语音模型,可生成富有表现力的 AI 语音,并支持对风格、语速和表达方式进行细粒度控制,适用于 Gemini API、Google AI Studio、Vertex AI 和 Google Vids。
Guardrails 2.0 是 ElevenLabs 为 ElevenAgents 提供的控制层,帮助 AI 语音代理保持话题聚焦、符合政策,并更安全地部署到生产环境,适用于支持、销售、营销、前台和内部流程团队。
HeyGen Developers 官方 API 文档,支持制作 AI 头像视频、视频翻译、口型同步和交互式视频代理会话;适合开发者通过 API、MCP 和 CLI 工作流接入。
Smallest.ai Lightning TTS 是一款文本转语音 API,可将文本快速生成语音,支持低延迟、多语言和快速声音克隆,适合开发者与产品团队构建语音代理、旁白内容和生产级语音工作流。

Voxtral TTS 是 Mistral 的文本转语音模型,可生成逼真、多语言语音,适用于语音代理与企业语音流程。支持短参考音色适配、低延迟输出,并可通过 Mistral Studio、Le Chat、API 及 Hugging Face 开放权重访问。

Gemini 3.1 Flash Live 是 Google 面向开发者、企业和消费者场景的实时语音模型,提供自然对话体验。开发者可在 Google AI Studio 预览使用,并驱动 Gemini Live 与 Search Live。
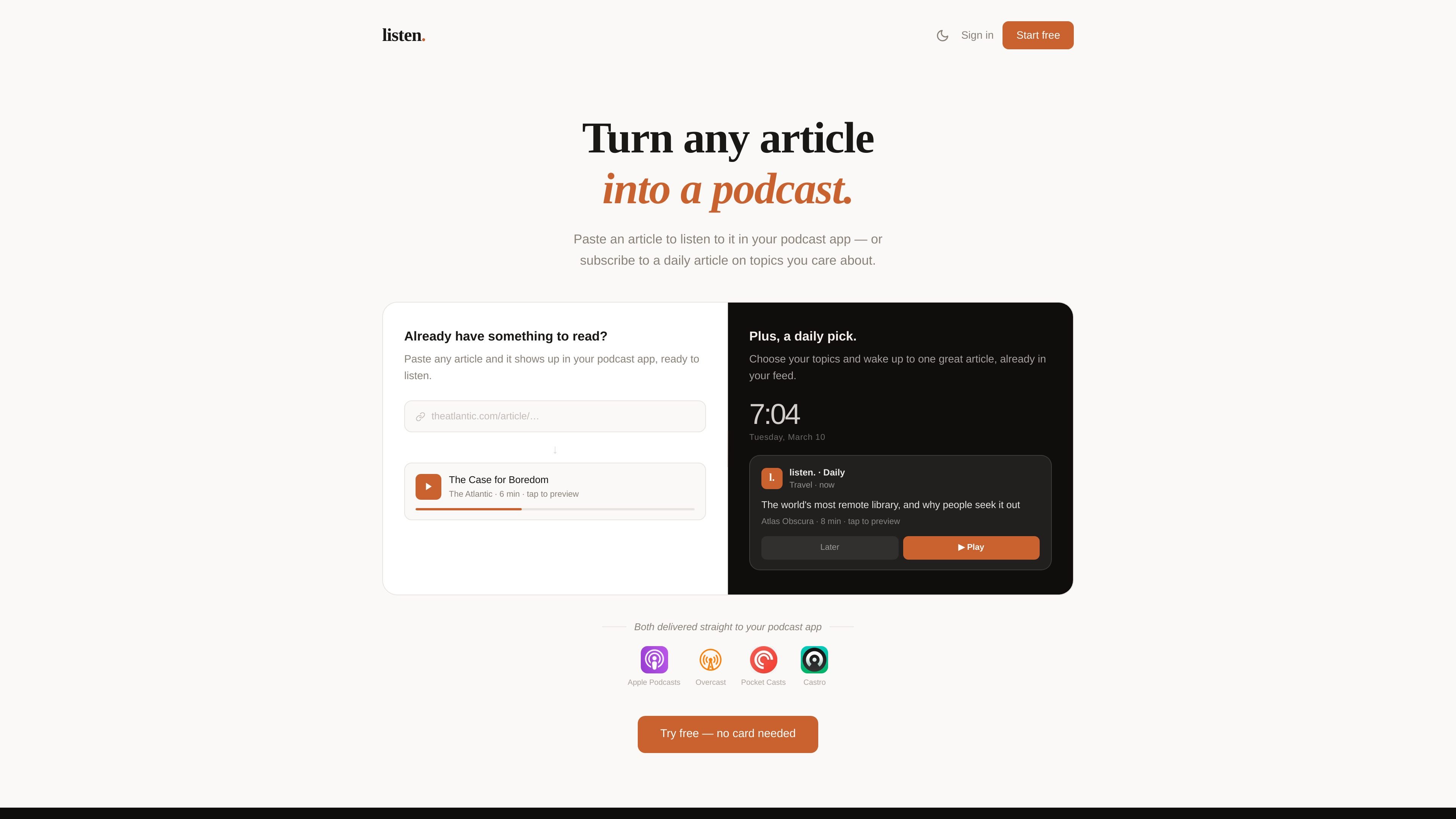
listen. 可将文章链接、PDF 或粘贴文本转为音频,在播客应用中直接收听;还提供每日精选文章流和 Chrome 扩展,方便浏览时快速保存。

Voizematic 是一款 AI 语音客服平台,可自动处理来电、外呼、预约安排和跟进,并支持无代码部署电话客服并连接 Google Workspace。