PinchBench 是什么?
PinchBench 是一个 OpenClaw LLM 模型基准测试网站,通过标准化编码任务的成功率对 AI 模型进行排名。其核心目的是帮助您使用相同的基于代理的测试设置比较多个 LLM,从而基于实测结果而非假设选择模型。
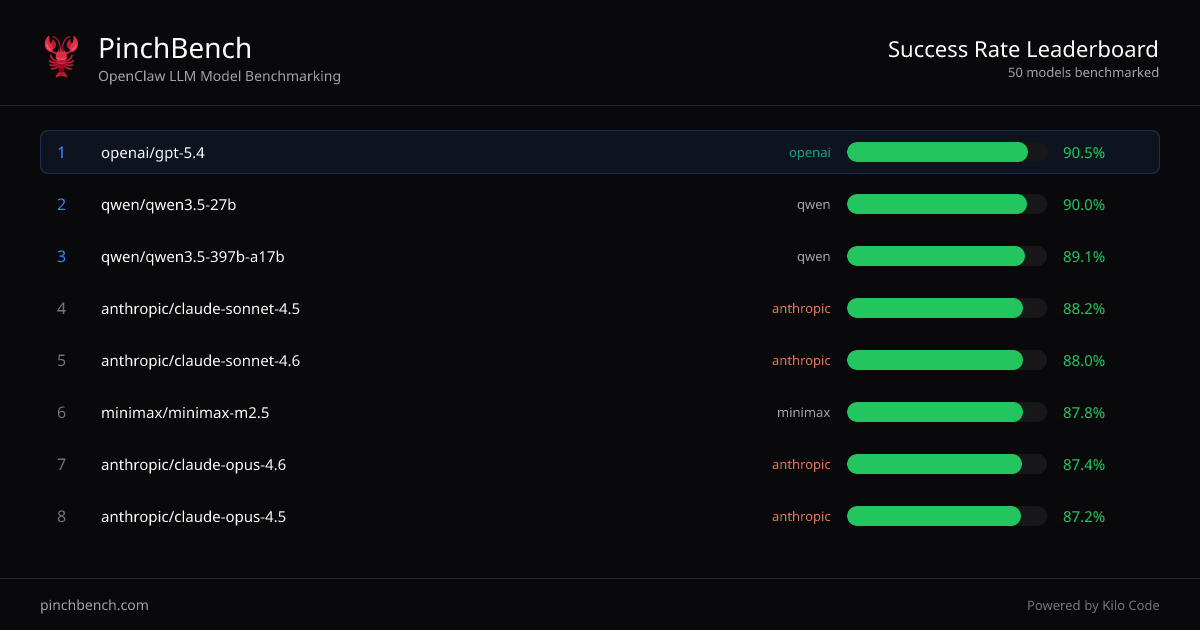
网站展示“按模型划分的成功率”排名,并允许查看更多任务和评分详情。它还标明评分和计分使用自动检查和 LLM 评判器实现自动化。
主要特性
- 跨模型成功率排名:显示按模型排序的表格,包含“Best %”、“Avg %”及相关分数列,便于一致性比较性能。
- OpenClaw 代理基准测试:专门在“OpenClaw”代理工作流上下文中评估模型,反映模型在代理驱动编码任务上的表现。
- 带检查和 LLM 评判器的自动化评分:分数来源于自动检查和 LLM 评判器,提供可重复的评估方法。
- 预算过滤(每次运行最高 $):包含标记为“Max $per run”的预算过滤器,允许您在界面显示的成本限制内聚焦比较。
- 透明测试材料和标准:注明“所有任务和评分标准均为开源”,并提供查看任务的方式。
如何使用 PinchBench
- 导航至 PinchBench,使用模型排名表格按成功率比较模型。
- 可选调整预算过滤,使用“Max $ per run”控件将结果缩小至符合您指定成本限制的模型。
- 使用任务视图和评分详情(包括开源评分标准)了解分数衡量内容,然后选择模型。
使用场景
- 为 OpenClaw 编码代理选择 LLM:通过标准化代理任务的实测成功率比较候选模型,然后挑选最适合您用例的选项。
- 评估峰值质量 vs. 平均性能:使用表格的“Best %”和“Avg %”列区分峰值表现好但一致性一般的模型。
- 成本意识模型比较:应用max $ per run过滤器,在预算上限下比较模型,同时依赖相同基准任务。
- 审视分数计算方式:检查开源任务和评分标准,验证基准中“成功”的含义,并评估是否符合您的预期行为。
- 一图比较多家提供商:使用汇总排名比较不同提供商的模型(如表格所示,例如 OpenAI、Anthropic、Qwen、Minimax 和 Google 模型)。
常见问题
-
PinchBench 如何确定模型成功率? 成功率以标准化 OpenClaw 代理测试中成功完成任务的百分比衡量,使用自动检查和 LLM 评判器。
-
我能看到基准测试包含什么吗? 可以。页面提供查看任务的选项,并声明任务和评分标准为开源。
-
排名中显示什么指标? 排名表格包含成功率相关百分比字段,如“Best %”和“Avg %”(界面中可见额外分数列)。
-
有按成本过滤模型的方式吗? 界面包含标记为“Max $per run”的预算过滤器,可用于限制显示结果。
-
PinchBench 评估通用对话质量吗? 网站专门基准测试模型在 OpenClaw 代理编码任务上的表现,显示的成功率对应该标准化基准上下文。
替代方案
- 通用 LLM 排行榜:广泛、非任务特定的排名适合快速浏览,但通常不衡量 OpenClaw 代理编码任务性能。
- 自建评估框架 / 内部基准:运行精选编码任务集并应用您的评分方式更匹配需求,但需设置和持续维护。
- 提供商特定评估和基准:部分厂商发布跨基准性能结果;这些在任务设计和评分上可能与 PinchBench 不同,比较需谨慎。
- 代理框架评估工具:允许用代理工作流测试 LLM 的工具可提供工作流对齐结果,但可能不提供 PinchBench 相同的标准化跨模型基准和开源评分标准。
替代品
AakarDev AI
AakarDev AI 是一个强大的平台,通过无缝的向量数据库集成简化 AI 应用程序的开发,实现快速部署和可扩展性。
BookAI.chat
BookAI允许您通过简单提供书名和作者与您的书籍进行AI聊天。
skills-janitor
skills-janitor 插件用于审计和跟踪 Claude Code 技能使用情况,并与九个聚焦的斜杠命令进行对比,零依赖。
FeelFish
FeelFish AI 小说写作助手PC客户端,支持人物与设定规划、章节生成与编辑,并凭上下文一致性续写剧情。
BenchSpan
BenchSpan 支持 AI agent 基准并行运行,自动记录得分与失败并整理运行历史;按提交标签复现,减少失败重跑浪费的 token。
ChatBA
ChatBA 是用于生成幻灯片的生成式 AI,可用聊天式流程快速根据你的输入创建演示内容与幻灯片。