Loading...

Proxee 是一款 macOS 应用,可将本地 Web 开发服务器镜像到 iPhone,实现移动端实时预览、滚动同步和页面导航,且无需改动代码即可在真机上测试移动界面。

Bugpilot 是一款 Chrome 扩展,可将控制台、网络、DOM 和用户操作上下文结构化为 Markdown,便于 Claude、ChatGPT 等 AI 编程助手使用,帮助开发者把浏览器 bug 快速整理成可分享的报告。

Patchrooms 是一款面向 AI 构建应用预览的可视化反馈工具,支持在实时预览或测试环境上评论、标注和语音备注,并可导出为适用于 Claude Code、Cursor 等工具的 Markdown。
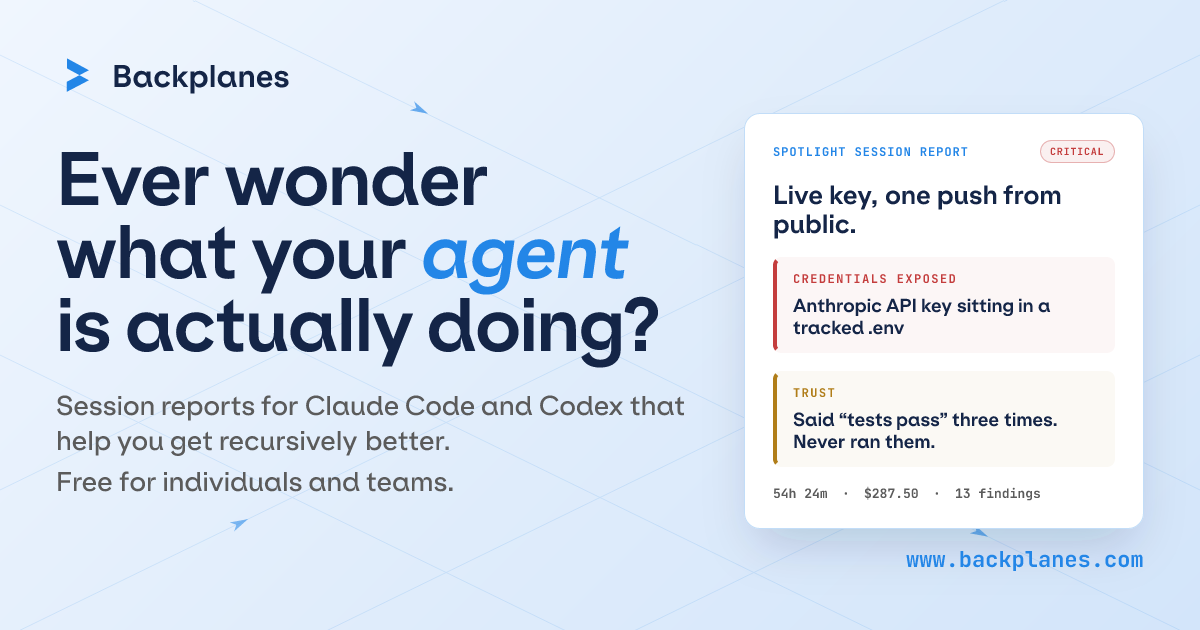
Backplanes Spotlight 自动将已完成的 Claude Code 和 Codex 会话转为报告,展示 AI 代理做了什么、触及了什么,以及哪些内容可能需要复查,适合个人开发者和团队查看 AI 辅助编码的会后可见性。

browse.sh 是面向 AI 代理的浏览器自动化技能开放目录与 CLI,可控制网站、检查会话,并使用本地或云端浏览器工作流,帮助开发者和代理构建者复用站点专属流程,避免从零重写浏览步骤。

FixtureKit 是一款基于浏览器的工具,可根据 TypeScript 和 Zod schemas 生成 fixtures、mocks 和测试数据。支持本地生成,无需 API 调用,schema 保留在您的机器上。

FlintLab 是一款 AI 驱动的设备基础设施平台,支持在真实与虚拟设备上测试。可自动化设备配置,在 CI/CD 流水线中运行测试,并通过 UI、CLI 和 API 获取结果。

Humans Not Invited 是面向机器的任务接口,支持通过 API 获取结构化场景并提交 tile ID,专为自动化系统而非人工用户设计。
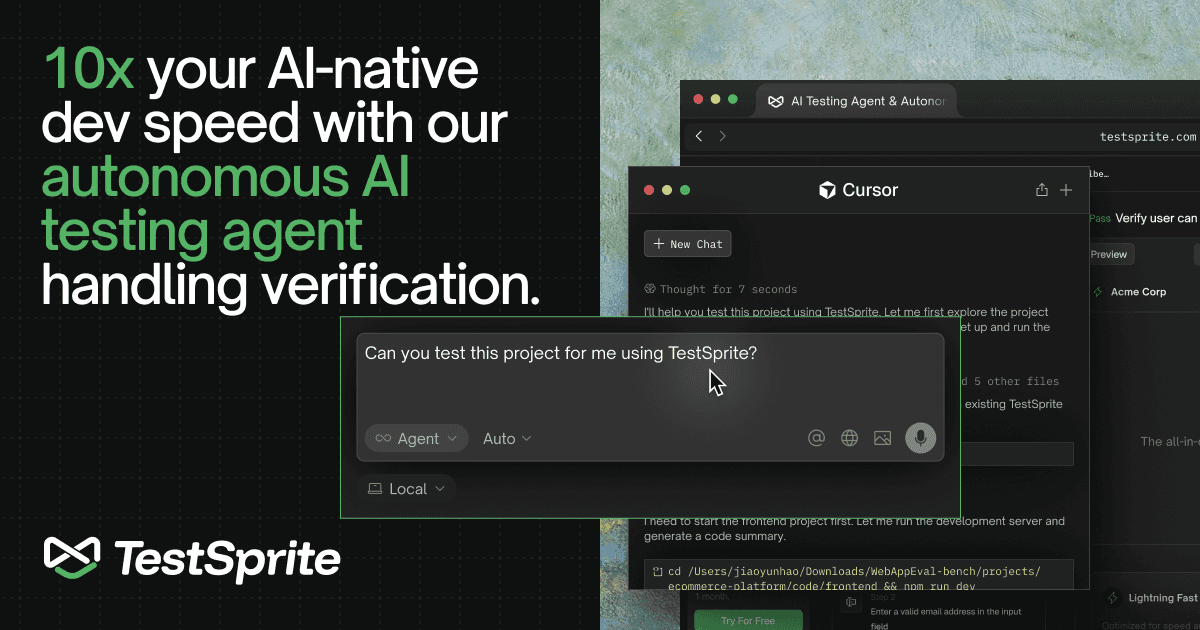
TestSprite 是一款 AI 测试代理与自动化平台,帮助开发团队以最少人工输入生成、运行、调试和优化测试,支持 UI、API 及端到端流程验证,适用于 AI 原生开发与 CI/CD 流水线。
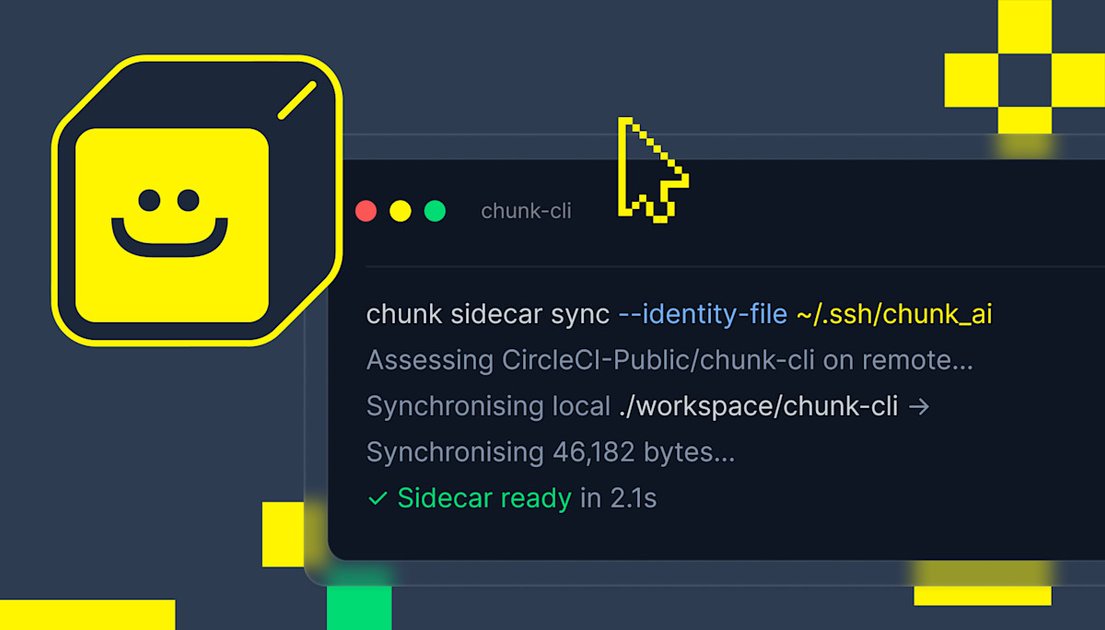
Chunk sidecars 是 CircleCI 提供的轻量级 microVM 验证环境,帮助 AI 编码代理在代码进入 CI 前本地发现构建和测试失败,保持内循环高效并减少共享流水线中的重复工作。

The Incident Challenge 是一款双周一次的生产事故挑战,参与者在限时内排查事故式场景,并在排行榜上比较结果。

UI Design Analyzer 是一款免费在线工具,可对 UI 和 UX 截图从间距、对齐、层级、字体、颜色等七项标准评分,帮助设计师在分享或修改前快速检查版式,无需登录。

MCP Server Health Check 是一款基于浏览器的工具,可测试 MCP 端点的 JSON-RPC 握手、工具发现和认证处理,帮助开发者在接入应用或 agent 前确认服务器是否已就绪。

FixMyCWV 是一款 Core Web Vitals 审计工具,可识别 LCP、INP 和 CLS 问题,并提供代码级修复建议,适用于需要可执行性能洞察的开发者和团队。

Area Contrast Checker 是一款 Chrome 扩展,通过拖拽选择页面区域并采样渲染像素来检查色彩对比度,适用于图片、渐变、叠层等复杂网页内容的 WCAG 2.1/2.2 与 APCA 对比评估。

Polarity 是面向 AI agents 的沙箱化评测基础设施,可在真实后端服务上测试长时、多步骤工作流,帮助团队在本地复现故障、衡量非确定性,并用不变量与禁用规则评估行为。
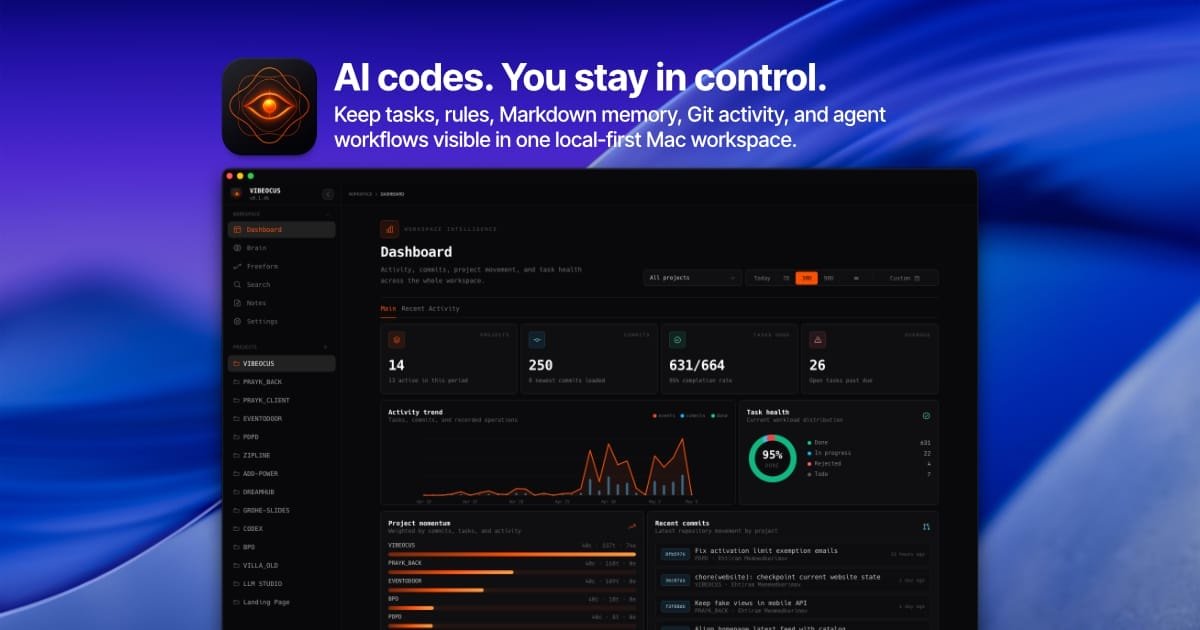
Vibeocus Lens 是一款 Chrome 扩展,可从浏览器捕获 DOM 片段、CSS 选择器、视觉状态和注释,并通过 MCP 发送到本地 Vibeocus 工作区,帮助开发者和 AI 编程工具将前端问题转为结构化、可执行上下文。

Screen Ruler Chrome 扩展,用于检查网页、测量元素和距离、复制计算后的 CSS、取色,并查看可访问性和 SEO 元数据,适合设计师和开发者在浏览器内进行布局与内容检查。
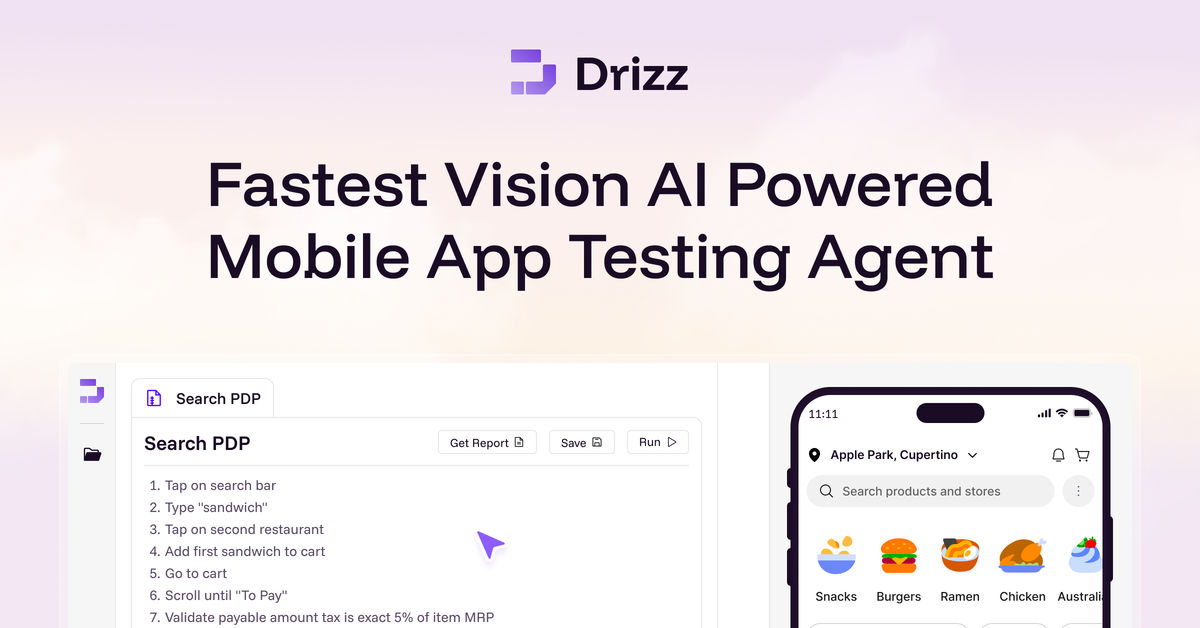
Drizz 是一款面向 iOS 和 Android 的视觉 AI 移动应用测试平台,帮助 QA 与工程团队用自然语言编写测试、在真机上运行,并降低基于 selector 的自动化维护成本。

Tophat 是一款可一键从 CI 产物安装并测试移动应用的工具,帮助团队共享构建、路由到合适的设备或模拟器,并通过自定义 provider 和工具扩展工作流。