什么是 Second Brain?
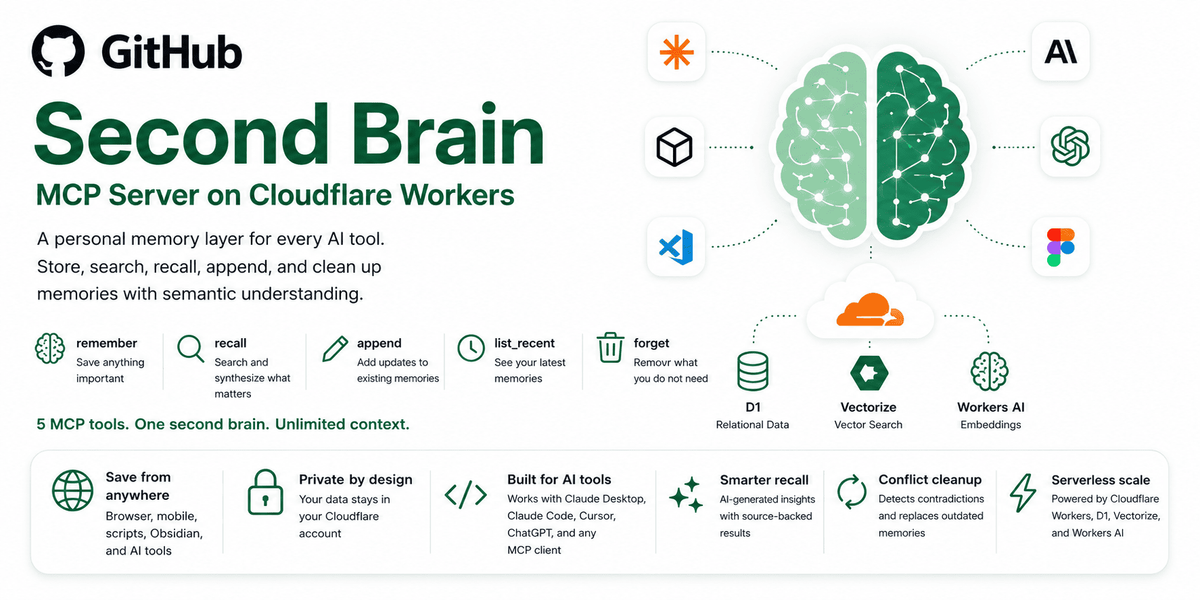
Second Brain 是面向 AI 工具的自托管记忆层。它让用户将笔记、决策、项目上下文和其他记忆一次性存储起来,然后通过已连接的客户端(如 Claude、ChatGPT、Cursor 以及其他兼容 MCP 的工具)在后续随时调用。
该项目旨在将记忆保留在用户手中,而不是存放在单一 AI 应用内。它运行在 Cloudflare 上,据称可部署到 Cloudflare 免费套餐,并支持语义回忆、条目更新和删除。
主要功能
- 跨 AI 工具共享记忆:一次保存上下文,即可在多个客户端中访问,无需在每个应用里重复输入相同信息。
- 语义回忆:按含义而非精确措辞搜索,因此即使原始表述不同,问题也能检索到相关记忆。
- 记忆管理操作:支持记住、向现有条目追加、替换内容、列出最近记忆,以及忘记条目。
- 多种采集入口:包含 CLI 命令、通过社区插件与 Obsidian 同步、iOS 快捷指令、浏览器扩展、书签脚本,以及直接在 AI 对话中使用。
- 面向浏览器客户端的 OAuth 支持:/mcp 端点支持通过浏览器认证的客户端使用 OAuth 2.0,而桌面端和 CLI 客户端仍可使用基于令牌的访问。
- Cloudflare 上的自托管部署:提供一键部署路径,仓库中注明了 AUTH_TOKEN 和用于 OAuth 的 KV 命名空间配置。
如何使用 Second Brain
将服务部署到 Cloudflare,设置 AUTH_TOKEN,并连接你要使用的 AI 客户端。之后,通过可用的采集方式保存上下文,并让已连接的工具在之后按含义回忆它。
典型工作流是先记住一个决策或笔记,然后在后续对话中取回;如果上下文发生变化,可以更新它;如果不再需要,也可以删除它。
使用场景
- 跨应用项目记忆:让 Claude、ChatGPT 和 Cursor 都能保留项目决策,无需重复撰写相同的背景信息。
- 开发者终端工作流:在聊天界面之外工作时,可通过 CLI 从命令行捕获和检索上下文。
- Obsidian 到 AI 的同步:将笔记存入本地知识库,并同步到共享记忆层,便于后续回忆。
- 从移动端或浏览器快速采集:通过浏览器扩展、书签脚本或 iOS 快捷指令保存网页、高亮文本或简短想法。
- 对话跟进与修正:向现有记忆追加新细节、替换过时内容,或在条目不再相关时将其移除。
常见问题
Second Brain 会把记忆存储在某个单一 AI 应用里吗?
不会。该项目旨在作为可跨多个 AI 工具使用的共享记忆层。
能否与 claude.ai 或 ChatGPT 这样的浏览器客户端一起使用?
可以。仓库说明 /mcp 端点支持通过托管登录页进行认证的浏览器客户端使用 OAuth 2.0。
我首先需要设置什么?
源码说明你需要在部署时设置 AUTH_TOKEN。对于基于 OAuth 的浏览器客户端,还需要 KV 命名空间,而部署流程会自动为其完成配置。
回忆是如何工作的?
仓库将回忆描述为语义搜索,也就是系统可以按含义而不是精确措辞来查找记忆。
我可以删除或更新已存储的记忆吗?
可以。文档中的操作包括 append、update、list_recent 和 forget。
替代方案
- 单一 AI 应用内置记忆:上手更简单,但仅限于该平台,无法跨工具共享。
- 个人知识库应用:笔记或 PKM 工具可以存储上下文,但通常不提供同样面向 AI 客户端的记忆 API 和 MCP 工作流。
- 自托管向量记忆或检索服务:如果你希望对已保存上下文进行语义搜索,它们在目标上类似,不过可能比本项目需要更多自定义集成工作。
- 手动提示词片段或保存的笔记:最简单,但不提供自动采集、语义回忆或集中式记忆管理。
替代品
Falconer
Falconer 是自更新知识平台,帮高速度团队在一个地方编写、分享并搜索可靠内部文档与代码上下文。
Theneo
Theneo 是一体化开发者门户,汇集 API 文档、指南、更新日志与私有客户文档,支持实时协同编辑与面向代理的工作流。
dumppp
dumppp 让手机快速捕捉想法并同步到 Notion:快速启动、轻松切换上下文,离线优先自动同步。
Lasso
Lasso 是面向电商团队的 AI 优先 PIM,可丰富商品属性与描述、处理供应商数据,并通过应用或 API 支持竞品监控。
Struere
Struere 是 AI 原生运营系统,用结构化软件替代表格流程,支持仪表盘、告警与自动化,集中管理运营数据与流程。
garden-md
garden-md 将会议转录内容整理成结构化、可互链的企业维基:基于本地 Markdown,并可用 HTML 浏览视图同步转录来源。