系統提示強化
強化的系統提示提供基礎政策,而 Focus Guardrail 會在整段對話中持續強化這些指令,以降低在長篇或複雜互動中的偏移。
Guardrails 2.0 是 ElevenLabs 為 ElevenAgents 提供的控制層,可讓語音代理與團隊指令、安全規則與營運目標保持一致。它在代理行為周圍加入多層檢查,讓團隊能降低偏移、偵測操弄嘗試,並在違反政策的回覆送達使用者前加以封鎖。
這項產品鎖定支援、銷售、行銷與內部流程中的正式語音代理部署。其控制可在代理設定中或透過 API 進行設定,頁面也將其視為企業部署更廣泛的信任與安全堆疊的一部分,包括對話分析、可選的零保留模式,以及適用客戶的通話後去識別化。
強化的系統提示提供基礎政策,而 Focus Guardrail 會在整段對話中持續強化這些指令,以降低在長篇或複雜互動中的偏移。
會檢查使用者輸入是否存在提示注入與指令覆寫嘗試,並可選擇終止具有安全風險的對話。
每一則回應在送達使用者前都會依照已設定的政策進行評估,讓不安全或偏離主題的輸出能即時被封鎖。
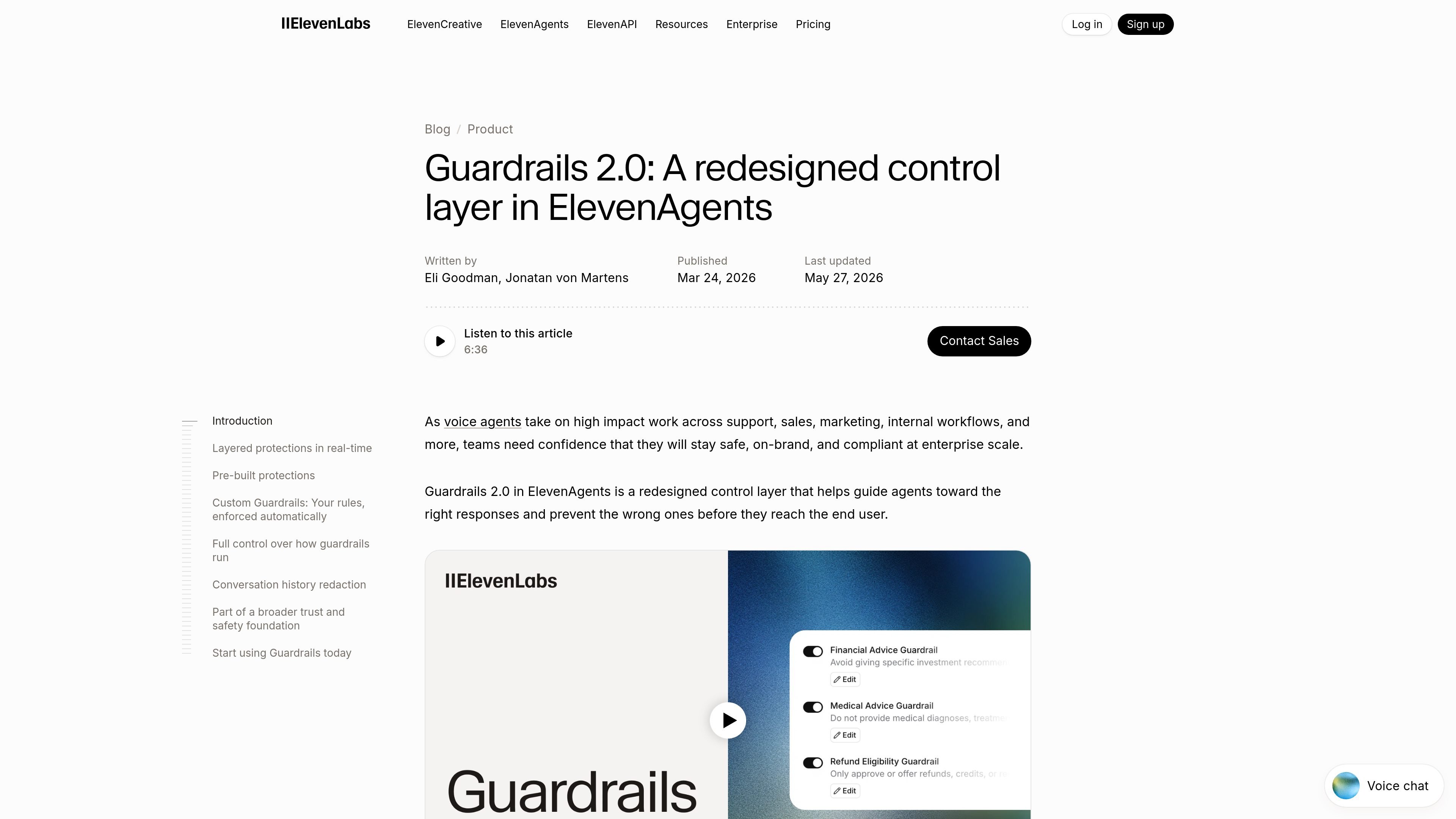
Custom Guardrails 讓團隊以自然語言撰寫特定領域規則,並透過封鎖或允許的決策,在所有通話中自動執行。
執行模式、退出策略、內容敏感度,以及每個 guardrail 的切換選項,讓團隊能控制執行嚴格程度與觸發後的處理方式。
觸發事件與動作會記錄於對話分析中,而敏感資訊可在通話結束後從逐字稿、錄音和 webhook 載荷中移除。
當語音代理在長篇或複雜通話中需要維持腳本一致時使用 Guardrails 2.0,例如支援或導入流程中的對話,因為偏移可能導致錯誤答案。
在使用者可能嘗試覆寫指令或誘使模型產生不安全行為的面向客戶工作流程中,套用操弄與回應檢查。
使用自訂 guardrails 來強制執行公司特定政策,例如升級規則、禁止主題或受監管語言要求。
為即時語音互動設定退出策略與敏感度等級,適用於團隊希望對低風險與高風險問題採用不同處理方式的情境。
將記錄與去識別化結合通話後 QA 工作流程,在需要逐字稿與錄音進行審查,同時移除儲存檔案中的敏感細節時使用。
Guardrails 2.0 於 ElevenAgents 中進行設定。頁面說明,你可以在代理設定的安全性分頁中開啟它們,或透過 API 進行設定。
頁面將其描述為三個層級:系統提示強化、使用者輸入驗證,以及代理回應驗證。這些功能共同運作,以強化指令、偵測操弄嘗試,並在回覆送達前封鎖違反政策的回應。
頁面指出,自訂 Guardrails 可讓你用自然語言定義特定領域的政策,並在每次通話中自動執行。輕量模型會評估每個回應,並回傳封鎖或允許的決策。
頁面說明,執行模式可讓你選擇讓 guardrails 與回應同時執行,以達到近乎零延遲,或是在回應完全通過檢查前先暫停回覆。它也提到你可以定義退出策略,例如結束對話、轉接給另一個代理、升級給真人,或使用修正指令重試。
對話歷史去識別化與 Zero Retention Mode 被描述為提供給企業客戶使用。頁面引導客戶聯絡銷售以取得存取權。
Wallie 是開源 AI streamer,可觀看你的螢幕、聆聽聊天室,並以可設定的人設即時生成直播評論;支援本機執行與自有金鑰,適合無真人出鏡、自治直播與即時互動。
CreateOS Sandbox 是以 Firecracker micro-VM 執行程式與 agent 工作負載的隔離運算環境,支援私有網路、SDK、CLI 與 MCP 程式化控制。
Codex Plugins 將可重用技能、應用程式整合與 MCP 伺服器打包成可安裝到 Codex app 或在 Codex CLI 使用的工作流程,方便延伸 Codex 的連線服務任務、重複使用指令與團隊共享流程。
一個集成圖像、視頻、語音、寫作和聊天工具的全能AI平台,以增強創造力和協作。
Gemma AI 是一款電話提醒 app,會依排程直接致電提醒你,不靠推播通知。支援 Google Calendar 同步與自然對話互動,讓你更直接掌握行程。
CAMB.AI Streams 可即時為直播多語配音,支援 YouTube、Twitch、X 等平台,並可透過常見串流協定無縫接入既有直播流程,免去後製步驟。