AI-driven extraction
Describe what you want in plain text and let the system adapt the scrape to the page structure, instead of relying only on fixed selectors.
Spidra is an AI web scraping API and playground for extracting structured data from websites that are hard to scrape with traditional tools. It helps developers and teams handle dynamic pages, CAPTCHAs, proxy rotation, and login-protected content with less manual setup.
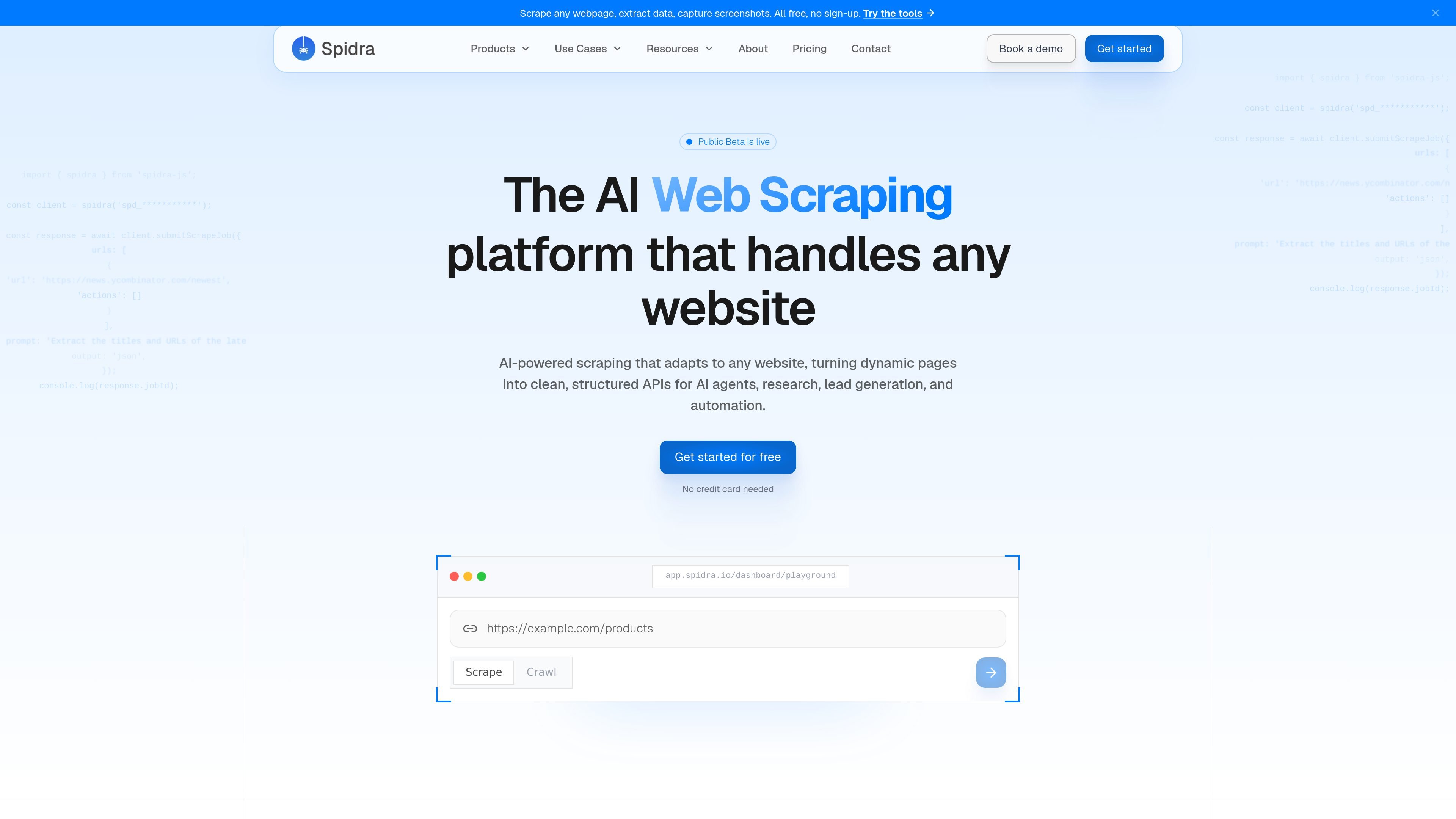
Spidra is an AI web scraping API and playground for extracting structured data from websites that are difficult to scrape with traditional, selector-based tools. It is positioned for developers and teams that need to collect data from dynamic pages, login-protected content, directories, marketplaces, and other sites that change often.
The product combines plain-text extraction instructions with crawling, CAPTCHA solving, proxy rotation, and session handling. Users can start in the Playground without writing code, or use the API and SDKs to build automated workflows that return structured output for downstream systems.
Describe what you want in plain text and let the system adapt the scrape to the page structure, instead of relying only on fixed selectors.
Find relevant pages across a domain and follow pagination or infinite scroll so multi-page workflows can be handled in one job.
Handle JavaScript-heavy sites, CAPTCHA challenges, proxies, rate limits, and anti-bot systems as part of the scraping workflow.
Save extracted data as JSON or CSV, or send it to Slack, Discord, webhooks, and databases.
Use session cookies for pages that require login, including protected dashboards or member-only content.
Build chained workflows by using output from one scrape to drive the next request through the API.
Build prospect lists from directories, event pages, Google Maps, and other public sources by extracting emails, phone numbers, job titles, and company details.
Track competitor prices, product availability, ratings, and review signals across marketplaces and retail sites to spot changes over time.
Enrich CRM records by following links from a directory or profile page to deeper company pages and collecting additional fields for each record.
Monitor listings, funding updates, and company announcements so teams can react when a target account or competitor makes a move.
Yes. The Playground lets you paste a URL and describe what you want in plain text, while the API is available for developers who want to build custom workflows.
Spidra returns clean, structured data and supports JSON and CSV output. The site also shows delivery options to Slack, Discord, webhooks, and databases.
The pricing page includes a free plan with 300 credits and paid plans starting at $19 per month. It also offers higher tiers for larger volumes and a custom plan for larger needs.
The pricing page states that results can be scheduled through presets and integrations, with options such as daily, weekly, or monthly runs.
Yes. The site says you can pass session cookies to access authenticated pages that use cookie-based login flows.
Happenstance is an AI-powered network search tool for finding people, mutual connections, and warm introductions across connected accounts. It supports individual use, shared team groups, and developer workflows through API, MCP, Slack, and other integrations.
Bardeen is a lead-sourcing and outreach automation platform that helps teams and individuals scrape leads, qualify them with AI, enrich contact details, and export results to common work tools. It is aimed at workflows where prospect research, enrichment, and outreach preparation are repetitive.
Podium is an AI lead generation and lead management platform for local businesses. It centralizes lead conversations, automated follow-up, reviews, payments, and booking, with a 24/7 AI Employee available as an add-on.
Octen is a search infrastructure product for AI applications that need live web context, structured answers, and retrieval tools for agents, copilots, and chatbots. It combines search, extraction, multimodal retrieval, and developer access paths such as API, SDKs, Skills, MCP, and CLI.
Blinked is a free Chrome extension for LinkedIn outreach that helps users research leads, draft personalized messages, and manage follow-ups inside LinkedIn. It is local first, with outreach data kept in the browser rather than on Blinked’s servers.
Skayle is a content and AI search visibility platform that researches topics before writing, publishes structured content to a CMS, and tracks whether brands are cited in AI search. It is aimed at teams that want one system for publishing, schema-rich content, and visibility monitoring.