Specialized model routing
Routes repeatable AI tasks to task-specific small and nano models instead of using frontier models for every request.
ZeroGPU is a distributed AI inference layer that routes high-volume tasks to specialized small and nano models across an edge-powered network. It helps developers lower inference costs and latency while keeping integration compatible with existing OpenAI-style API patterns.
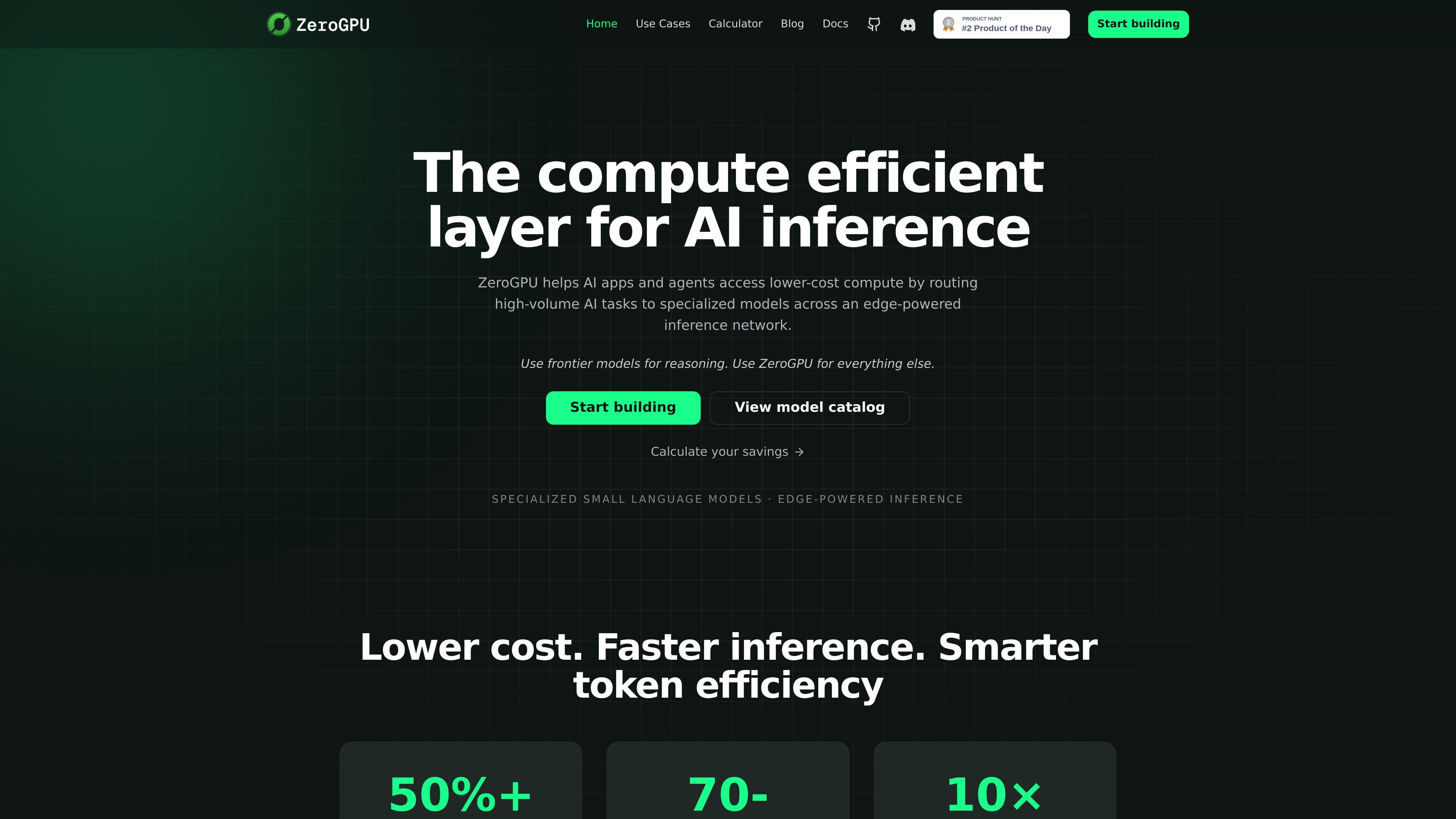
ZeroGPU is a distributed inference layer for AI applications that aims to reduce compute cost by routing high-volume tasks to specialized small and nano language models. Rather than sending every request to a frontier model, it shifts routine work such as classification, summarization, signal extraction, moderation, routing, and PII detection to cheaper models built for those jobs.
The platform combines specialized models with edge-powered execution, optimized servers, approved edge devices, and cloud fallback. It is presented for developers building production AI systems, including agents, document AI, adtech, compliance, security, and fraud workflows, and it exposes an OpenAI-compatible API so teams can integrate it into existing stacks.
Routes repeatable AI tasks to task-specific small and nano models instead of using frontier models for every request.
Runs inference across optimized servers, approved edge capacity, and cloud fallback based on performance and availability.
Exposes an OpenAI-compatible chat and responses API so teams can integrate without redesigning their application flow.
Provides project-level API keys plus usage, latency, and savings analytics for tracking operational impact.
Supports a model catalog and workload-specific outputs for tasks like classification, summarization, PII detection, moderation, and routing.
Offers a monetization path where eligible apps can turn user device idle time into paid inference capacity.
Classify intent, extract signals, and route repetitive agent tasks without sending every step to a frontier model.
Summarize documents, classify pages, extract structured fields, and detect PII in document pipelines.
Moderate content, detect policy violations, and flag risky or regulated material in real time.
Classify email intent, triage conversations, and route requests to the right team or queue.
Score fraud and risk signals, then escalate only higher-risk cases to heavier systems.
ZeroGPU is an inference layer for AI applications that routes selected workloads to specialized small and nano models instead of sending every request to frontier models.
The site says developers integrate with an OpenAI-compatible chat and responses API, project-level API keys, and a model catalog, then route suitable tasks to specialized models.
ZeroGPU is positioned for high-volume tasks such as summarization, classification, signal extraction, PII detection, moderation, routing, and similar structured AI workloads.
The site describes device-side participation for apps that integrate the SDK, but it limits eligible devices to healthy conditions and runs one inference request at a time.
ByteAsk is a terminal-first AI coding agent for C and C++ that edits repositories and verifies changes with the real compiler, debugger, sanitizers, and tests before showing a diff. It offers a free tier plus paid plans, with editor connectors and zero-retention handling described in the source.
CreateOS Sandbox is an isolated compute environment for running code and agent workloads inside Firecracker micro-VMs. It is designed for workflows that need machine-level isolation, private networking between sandboxes, and programmatic control through SDK, CLI, or MCP.
hob is an independent workspace for coding agents that keeps agent sessions, terminals, history, and follow-up work organized around the tools and providers you already use. It is aimed at developers who want local control over routing, history, and workspace structure rather than a bundled model stack.
Ably Chat is a chat API platform for building custom realtime chat applications. It supports room-based messaging, typing indicators, presence, reactions, and message updates, with usage-based pricing options for different deployment stages.
Manta AI is an autonomous web app testing tool for teams that want to map application behavior, catch regressions, and generate tests without writing scripts or maintaining selectors. It works from a URL and supports plain-English test flows, run results with screenshots, and scheduled or deployment-triggered checks.
SonOf connects to your repo and PM tool, audits the codebase and surrounding product context, and turns approved work into shipped tickets with senior engineering review. It is aimed at founders and engineering leaders who need backlog help without hiring a full team immediately.