Second Brain
Second Brain est une couche de mémoire partagée auto-hébergée pour les outils IA, pour stocker notes, décisions et contexte projet et les retrouver sur Claude, ChatGPT et Cursor.
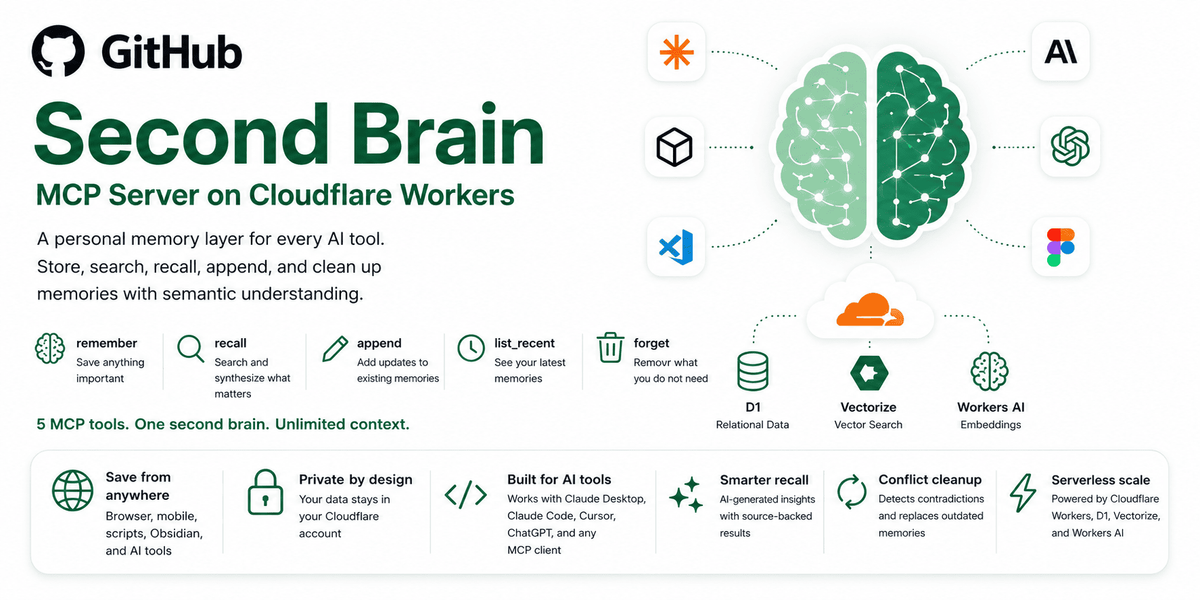
Qu’est-ce que Second Brain ?
Second Brain est une couche de mémoire auto-hébergée pour les outils IA. Elle permet de stocker une fois des notes, des décisions, du contexte projet et d’autres souvenirs, puis de les récupérer plus tard via des clients connectés tels que Claude, ChatGPT, Cursor et d’autres outils compatibles MCP.
Le projet est conçu pour garder la mémoire sous le contrôle de l’utilisateur plutôt que dans une seule application IA. Il s’exécute sur Cloudflare et est présenté comme déployable sur le niveau gratuit de Cloudflare, avec prise en charge du rappel sémantique, de la mise à jour des entrées et de la suppression.
Fonctionnalités clés
- Mémoire partagée entre outils IA : stockez le contexte une fois et accédez-y depuis plusieurs clients au lieu de ressaisir les mêmes informations dans chaque application.
- Rappel sémantique : recherchez par sens plutôt que par formulation exacte, afin qu’une question puisse faire remonter un souvenir pertinent même si le libellé d’origine diffère.
- Actions de gestion de la mémoire : prend en charge la mémorisation, l’ajout à une entrée existante, le remplacement du contenu, l’affichage des mémoires récentes et l’oubli d’entrées.
- Plusieurs points de capture : inclut des commandes CLI, la synchronisation Obsidian via un plugin communautaire, des raccourcis iOS, une extension de navigateur, un bookmarklet et une utilisation directe depuis des conversations avec l’IA.
- Prise en charge d’OAuth pour les clients web : le point de terminaison /mcp prend en charge OAuth 2.0 pour les clients qui s’authentifient via un navigateur, tandis que l’accès par token reste disponible pour les clients desktop et CLI.
- Déploiement auto-hébergé sur Cloudflare : le déploiement est automatisé avec un parcours en un clic, et le dépôt indique la configuration d’un AUTH_TOKEN et d’un namespace KV pour OAuth.
Comment utiliser Second Brain
Déployez le service sur Cloudflare, définissez un AUTH_TOKEN et connectez les clients IA que vous souhaitez utiliser. Ensuite, enregistrez du contexte via les méthodes de capture disponibles et demandez à vos outils connectés de le rappeler plus tard par le sens.
Un flux de travail typique consiste à mémoriser une décision ou une note une seule fois, puis à la récupérer dans une conversation ultérieure, à la mettre à jour si le contexte change, ou à la supprimer lorsqu’elle n’est plus nécessaire.
Cas d’usage
- Mémoire de projet entre applications : gardez les décisions de projet disponibles dans Claude, ChatGPT et Cursor sans réécrire les mêmes informations de fond.
- Flux de travail terminal pour développeur : capturez et récupérez du contexte depuis la ligne de commande avec la CLI lorsque vous travaillez hors d’une interface de chat.
- Synchronisation note-vers-IA depuis Obsidian : stockez des notes dans une base de connaissances locale et synchronisez-les dans la couche de mémoire partagée pour un rappel ultérieur.
- Capture rapide depuis mobile ou navigateur : enregistrez une page, du texte surligné ou une courte idée via l’extension de navigateur, le bookmarklet ou les raccourcis iOS.
- Relance et correction d’une conversation : ajoutez de nouveaux détails à une mémoire existante, remplacez un contenu obsolète ou supprimez des entrées lorsqu’elles ne sont plus pertinentes.
FAQ
Second Brain stocke-t-il la mémoire dans une seule application IA ? Non. Le projet est conçu comme une couche de mémoire partagée utilisable sur plusieurs outils IA.
Peut-il être utilisé avec des clients web comme claude.ai ou ChatGPT ? Oui. Le dépôt indique que le point de terminaison /mcp prend en charge OAuth 2.0 pour les clients web qui s’authentifient via une page de connexion hébergée.
Que dois-je configurer en premier ? La source indique qu’il faut définir un AUTH_TOKEN lors du déploiement. Pour les clients web basés sur OAuth, un namespace KV est également requis, et le flux de déploiement le provisionne automatiquement.
Comment fonctionne le rappel ? Le dépôt décrit le rappel comme une recherche sémantique, ce qui signifie que le système peut trouver des mémoires par leur sens plutôt que par leur formulation exacte.
Puis-je supprimer ou mettre à jour des mémoires stockées ? Oui. Les actions documentées incluent append, update, list_recent et forget.
Alternatives
- Mémoire intégrée dans une seule application IA : plus simple à démarrer, mais limitée à cette plateforme plutôt que partagée entre outils.
- Applications de base de connaissances personnelles : les outils de prise de notes ou de PKM peuvent stocker du contexte, mais ils ne proposent généralement pas la même API de mémoire orientée client IA ni le même flux MCP.
- Services de mémoire vectorielle ou de récupération auto-hébergés : proches dans l’objectif si vous voulez une recherche sémantique sur du contexte enregistré, bien qu’ils puissent nécessiter davantage d’intégration personnalisée que ce projet.
- Extraits de prompt manuels ou notes enregistrées : option la plus simple, mais sans capture automatisée, rappel sémantique ni gestion centralisée de la mémoire.
Alternatives
Falconer
Falconer est une plateforme de connaissances qui se met à jour automatiquement pour équipes rapides : écrivez, partagez et trouvez une documentation interne fiable.
Theneo
Theneo : portail développeur tout-en-un pour API, guides, changelogs et documentation client privée, avec co-édition en temps réel et workflows prêts pour agents.
dumppp
dumppp capture vos idées sur mobile et les envoie dans Notion : lancement rapide, bascule de contexte, synchronisation offline-first.
Lasso
Lasso est un PIM orienté IA pour équipes e-commerce : enrichit attributs et descriptions, traite les données fournisseurs et suit les concurrents via app ou API.
Struere
Struere est un système opérationnel natif AI qui remplace les workflows Excel par des logiciels structurés : tableaux de bord, alertes et automatisations.
garden-md
Transformez des transcriptions de réunion en wiki d’entreprise structuré et lié, via des fichiers markdown locaux et une vue HTML, avec synchronisation.