SemanticGuard
SemanticGuard è un AI gateway con cache autoverificante per API LLM di OpenAI, Anthropic e Google. Misura i risparmi e mantiene attive le richieste.
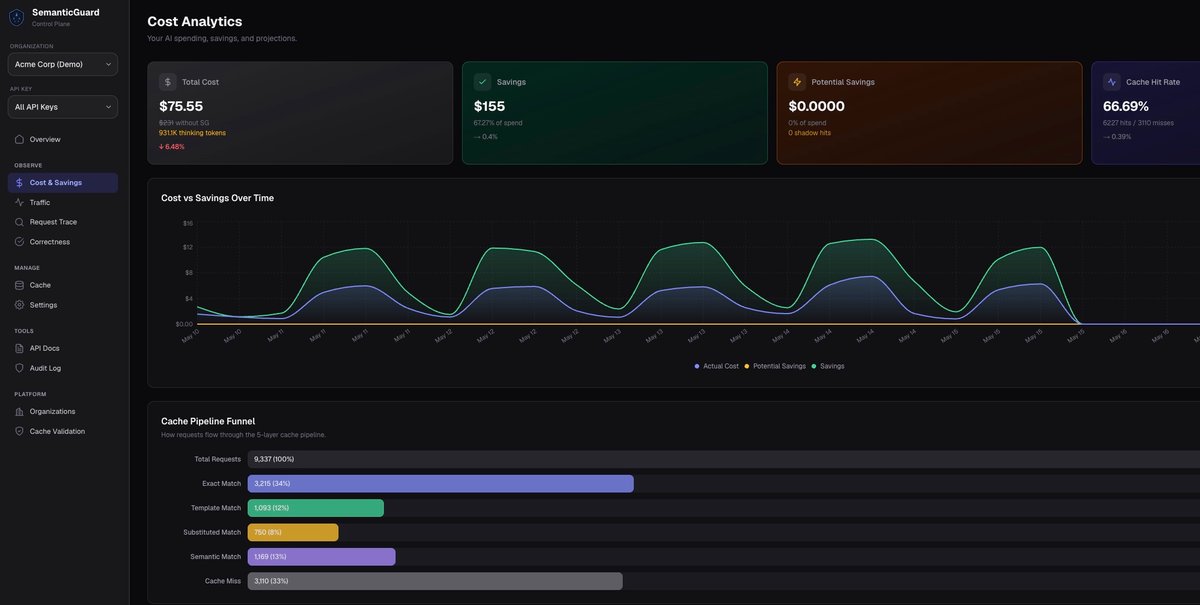
Che cos'è SemanticGuard?
SemanticGuard è un AI gateway e una cache autoverificante per API LLM. Si inserisce nel percorso delle richieste per provider come OpenAI, Anthropic e Google, memorizzando le risposte nella cache e usando una verifica multilivello per controllare se una risposta in cache è ancora corretta.
Il prodotto è progettato per ridurre la spesa per le API LLM senza costringere gli utenti a modificare i prompt o a gestire manualmente gli oggetti cache. Include anche una Shadow Mode che misura i risparmi potenziali prima che la cache venga abilitata e supporta un design fail-open, così le richieste continuano verso il provider upstream se la cache non è disponibile.
Funzionalità principali
- Integrazione SDK in un'unica riga tramite
fetch: withSemanticGuard()nell'AI SDK, che permette ai team di aggiungere la cache senza riscrivere la logica applicativa. - Misurazione in Shadow Mode che mostra il costo per richiesta, i risparmi previsti, i tipi di hit e dove il traffico verrebbe messo in cache prima di servire risposte dalla cache.
- Hit di cache autoverificati con verifica multilivello, con hit campionati giudicati anche dall'AI per correttezza e fallimenti segnalati.
- Supporto cross-provider per OpenAI, Anthropic, Google e altri provider elencati come Azure, Bedrock e Mistral.
- Comportamento della cache ottimizzato per corrispondenze semantiche, così richieste con nomi, date o ID diversi possono comunque andare in hit quando la risposta è di fatto la stessa.
- Gestione delle richieste fail-open, che invia il traffico direttamente al provider se la cache è fuori uso.
- Controlli di sicurezza indicati sul sito, tra cui crittografia in transito e a riposo, memorizzazione opzionale dei prompt e chiavi API upstream passate al momento della richiesta invece che archiviate.
Come usare SemanticGuard
Gli sviluppatori aggiungono SemanticGuard alla configurazione dell'AI SDK avvolgendo il livello fetch con withSemanticGuard() e poi inviando le richieste come di consueto. Il flusso mostrato sul sito inizia con la Shadow Mode per misurare i risparmi e osservare come verrebbe classificato il traffico.
Quando il team è soddisfatto dei risultati, la cache può essere abilitata. A quel punto, gli hit di cache vengono restituiti automaticamente e la dashboard può essere usata per rivedere risparmi, hit rate e risultati di validazione.
Casi d'uso
- Ridurre la spesa nelle applicazioni LLM ad alto volume in cui molti utenti fanno domande sovrapposte e le risposte ripetute possono essere riutilizzate.
- Misurare l'economia della cache prima del rollout, soprattutto per i team che vogliono quantificare i risparmi senza servire subito output dalla cache.
- Servire richieste semanticamente simili che differiscono in dettagli superficiali come nomi, date o ID, dove la cache del provider basata su corrispondenza byte-identica non andrebbe in hit.
- Supportare stack AI multi-provider che hanno bisogno di un unico livello di cache tra diversi vendor di modelli.
- Mantenere la disponibilità per app di produzione che necessitano di un percorso di fallback se il livello di cache non è disponibile.
FAQ
SemanticGuard richiede modifiche ai prompt? No. Il sito descrive un'integrazione SDK in un'unica riga e dice che non sono necessarie modifiche ai prompt.
Posso testare i risparmi prima di abilitare gli hit di cache? Sì. SemanticGuard include la Shadow Mode, che misura quanto risparmieresti prima che vengano servite risposte in cache.
Funziona con più di un provider di modelli? Sì. La pagina elenca OpenAI, Anthropic, Google e menziona anche la compatibilità con altri provider come Azure, Bedrock e Mistral.
Cosa succede se la cache non è disponibile? Il prodotto è descritto come fail-open, cioè le richieste vanno direttamente al provider.
Il prodotto è solo per il caching exact-match? No. La pagina presenta SemanticGuard come semantic caching, pensato per richieste che significano la stessa cosa anche quando dettagli come nomi, date o ID cambiano.
Alternative
- Prompt caching nativo del provider, come il caching integrato di OpenAI o di vendor simili. Di solito è limitato al riuso esatto o quasi esatto di prefissi all'interno del sistema del provider ed è più adatto a segmenti statici del prompt.
- Livelli di cache manuali integrati in un'applicazione o proxy. Possono essere personalizzati, ma di solito richiedono più lavoro di engineering per definire le chiavi di cache, gestire l'invalidazione e verificare la correttezza.
- Gateway AI generici senza validazione semantica. Possono gestire routing, osservabilità o enforcement delle policy, ma non si concentrano necessariamente sulla cache con controlli di correttezza.
- Uso diretto del provider senza un livello di cache. È la configurazione più semplice, ma non aggiunge riuso tra richieste simili né un flusso di misurazione dei risparmi prima del lancio.
Alternative
AakarDev AI
AakarDev AI è una piattaforma potente che semplifica lo sviluppo di applicazioni AI con integrazione fluida dei database vettoriali, consentendo un rapido deployment e scalabilità.
Ably Chat
Ably Chat è un’API e SDK per chat realtime: crea applicazioni personalizzate con reazioni, presenza e modifica/eliminazione dei messaggi.
BookAI.chat
BookAI ti consente di chattare con i tuoi libri utilizzando l'IA semplicemente fornendo il titolo e l'autore.
DeepMotion
DeepMotion è una piattaforma AI di motion capture e body-tracking per creare animazioni 3D da video (e testo) nel browser, con Animate 3D API.
skills-janitor
skills-janitor esegue audit, traccia l’uso e confronta le tue skill per Claude Code con 9 azioni slash mirate, senza dipendenze.
Arduino VENTUNO Q
Arduino VENTUNO Q è un edge AI computer per robotica: unisce inferenza AI e microcontrollore per controllo deterministico, con sviluppo in Arduino App Lab.