Schema-driven extraction
Define the JSON shape you need and send a URL. Tabstack enforces the schema on the server side and returns output that matches it, even when the source page changes.
Tabstack’s Structured Data Extraction API turns a URL into schema-matched JSON, with a related instruction-based generation flow for outputs that require reasoning. It is aimed at teams that need structured web data without maintaining parsing, browser, or LLM orchestration layers.
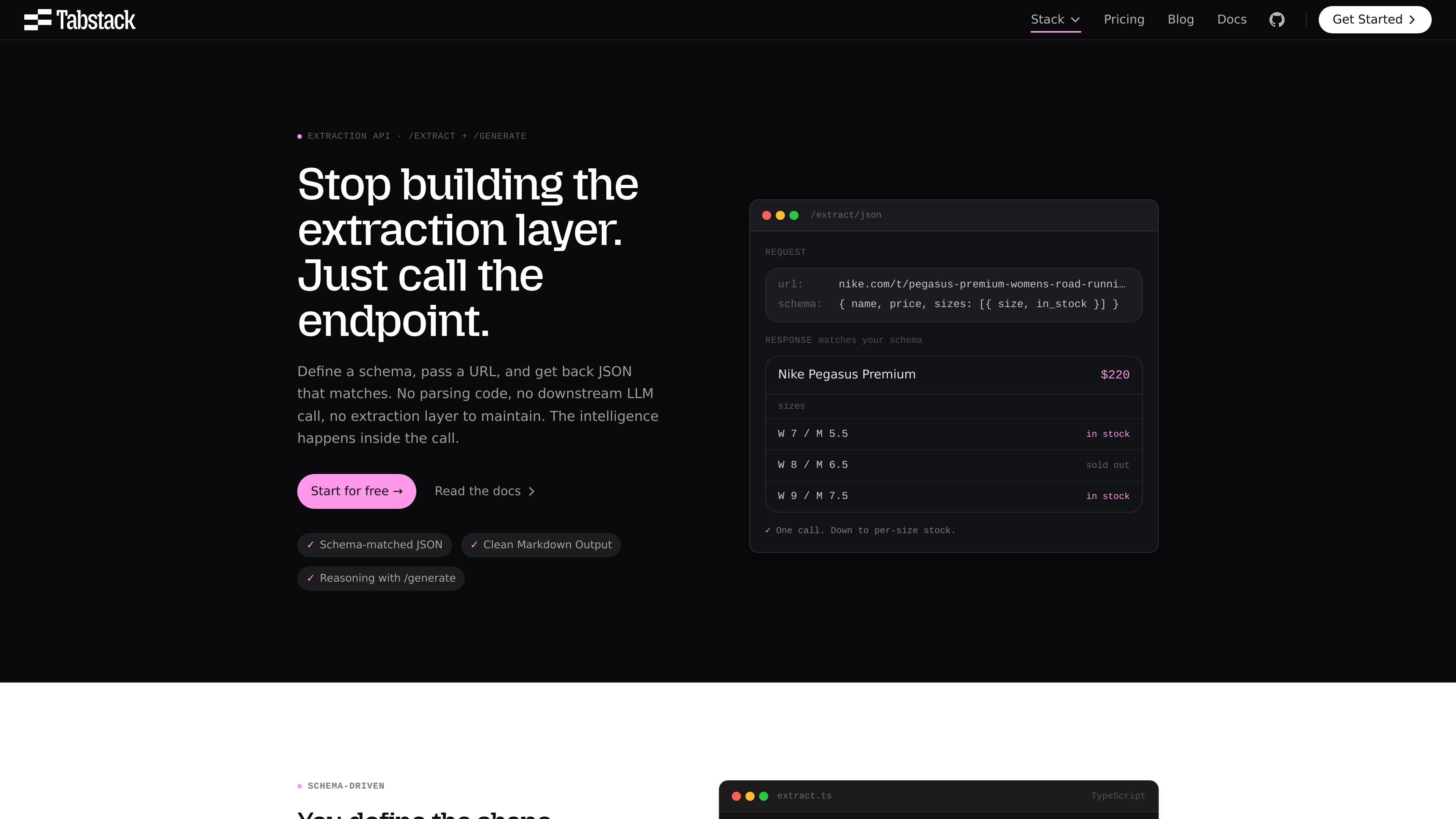
Tabstack’s Structured Data Extraction API turns a URL into JSON that matches a schema you define. The product is built for teams that need consistent structured output from web pages without maintaining their own parsing logic, browser pipeline, or downstream LLM orchestration.
The pages on the site show two closely related workflows: `/extract/json` for direct schema-matched extraction, and `/generate/json` for cases where instructions and reasoning are needed on top of the page content. The same platform also exposes Markdown output, research with citations, and browser automation, but this page is focused on the structured extraction use case.
Define the JSON shape you need and send a URL. Tabstack enforces the schema on the server side and returns output that matches it, even when the source page changes.
Use `/extract/json` for fixed-shape data, `/extract/markdown` for page text, and `/generate/json` when you want instructions layered on top of the source page.
The site says extraction works on server-rendered, client-rendered, and JavaScript-heavy pages, so the workflow is not limited to static HTML.
`/generate/json` adds instructions to the URL-based workflow, making it useful when the task requires interpretation rather than a direct field pull.
Control freshness and retrieval behavior with `nocache`, `effort`, and `geo_target`, including fresh fetches and country-specific views.
A TypeScript SDK is shown in the product examples, and the pricing page also lists Python SDK, MCP, and CLI as access options for the broader platform.
Pull pricing tables, product specs, inventory states, or other page data into a fixed JSON shape for dashboards and downstream systems.
Turn a domain or product page into normalized company, product, or contact data for enrichment pipelines.
Feed product pages, docs, and articles into retrieval or indexing pipelines using structured JSON or Markdown instead of custom scraping code.
Use `/generate/json` when the page alone is not enough and the result needs a structured interpretation, such as explaining what a pricing page implies about segmentation.
For teams that need adjacent workflows, the same platform also supports cited web research and browser automation on live pages.
Yes. The source pages show a TypeScript SDK and example calls for the extraction and research endpoints, along with API endpoints documented for `/extract/json`, `/extract/markdown`, `/generate/json`, `/research`, and `/automate`.
The structured extraction workflow is designed for a URL plus a JSON schema. Tabstack returns JSON that matches the schema, and the site also shows a related `/generate/json` flow for instructions-based structured output.
The home page shows extraction working on server-rendered, client-rendered, and JavaScript-heavy pages. It also mentions clean Markdown output when needed.
Pricing is shown publicly on the site: there is a free trial with 10,000 credits, an Individual plan, Team and Pro plans with included credits, and an Enterprise plan with custom pricing.
The source materials do not describe a published list of SDKs, authentication methods, or output formats beyond the examples shown on the pages. The clearest documented outputs are schema-matched JSON, clean Markdown, cited research answers, and completed browser tasks.
Happenstance is an AI-powered network search tool for finding people, mutual connections, and warm introductions across connected accounts. It supports individual use, shared team groups, and developer workflows through API, MCP, Slack, and other integrations.
Geekflare Web Scraping API is a developer-focused web scraping service that extracts content from dynamic pages and returns Markdown, HTML, JSON, or plain text. It is aimed at teams that need browser rendering, CAPTCHA handling, and proxy support without building that infrastructure themselves.
nolainocr is an AI OCR tool that extracts structured data from PDF invoices, receipts, forms, contracts, and bank statements. It helps teams move document data into Excel, Google Sheets, JSON, or CSV without manual entry.
Octen is a search infrastructure product for AI applications that need live web context, structured answers, and retrieval tools for agents, copilots, and chatbots. It combines search, extraction, multimodal retrieval, and developer access paths such as API, SDKs, Skills, MCP, and CLI.
Skayle is a content and AI search visibility platform that researches topics before writing, publishes structured content to a CMS, and tracks whether brands are cited in AI search. It is aimed at teams that want one system for publishing, schema-rich content, and visibility monitoring.
司马阅是一款面向企业的AI文档智能体平台,帮助团队把分散在文档中的知识转成可用于问答、检索、写作和审查的结构化能力。它适合对准确性和数据安全要求较高、且有大量文档工作流程的企业。