HyperAPI - Financial Document Intelligence
Hyperbots Inc.による、数百万の財務文書からの高精度でスケーラブルな処理とインテリジェンス抽出を実現する、本番環境対応API群。
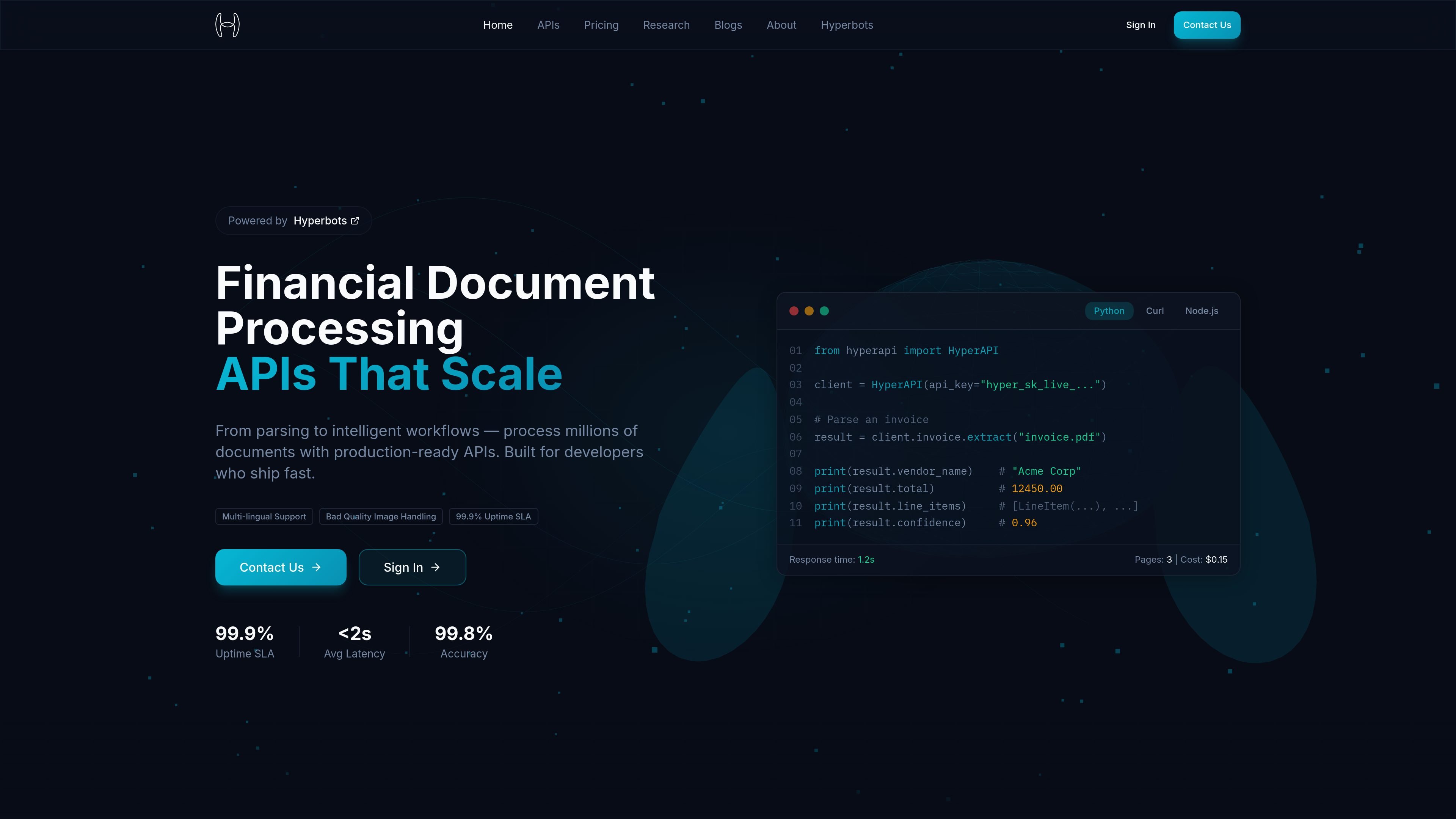
Hyperbots Inc.による、数百万の財務文書からの高精度でスケーラブルな処理とインテリジェンス抽出を実現する、本番環境対応API群。
HyperAPI - Financial Document Intelligenceの代替品
Masari
Masari is an AI expense tracker for iPhone that lets you log spending by snapping receipts or typing plain-language entries, then ask questions about your finances in chat. It also keeps a searchable expense history with filters by date, merchant, and category.
nolainocr
nolainocr is an AI OCR tool that extracts structured data from PDF invoices, receipts, forms, contracts, and bank statements. It helps teams move document data into Excel, Google Sheets, JSON, or CSV without manual entry.
Timebook
Timebookは、フリーランスや1人合同会社向けの時間記録、請求書発行、帳簿管理アプリです。作業時間、請求書、基本的な会計を1つにまとめ、Plaid連携とAIエージェント対応も選べます。
司马阅
司马阅是一款面向企业的AI文档智能体平台,帮助团队把分散在文档中的知识转成可用于问答、检索、写作和审查的结构化能力。它适合对准确性和数据安全要求较高、且有大量文档工作流程的企业。
Capso
Capsoは、macOS向けのネイティブなスクリーンショット・画面録画アプリ。キャプチャ、注釈、録画、OCRまで1つでこなす無料・オープンソースのCleanShot X代替です。
Finchum
Finchum is a personal finance planning tool that aggregates accounts and forecasts future balances for users in the US and Canada. It supports secure sync without sharing bank passwords, with OAuth where available and file-based imports as a fallback.