複数のデータモデルを1つのエンジンに統合
NodeDBは、リレーショナル、ベクトル、グラフ、ドキュメント、カラム型、科学配列データを1つのRustベースエンジンに統合するものとして説明されています。
NodeDBは、リレーショナル、ベクトル、グラフ、ドキュメント、カラム型、科学配列データを1つのRustバイナリで統合するユニバーサルデータベースエンジン。PostgreSQLクライアント互換と、ベクトル検索とグラフ展開を1回のクエリで融合するGraphRAG風ワークフローに対応。
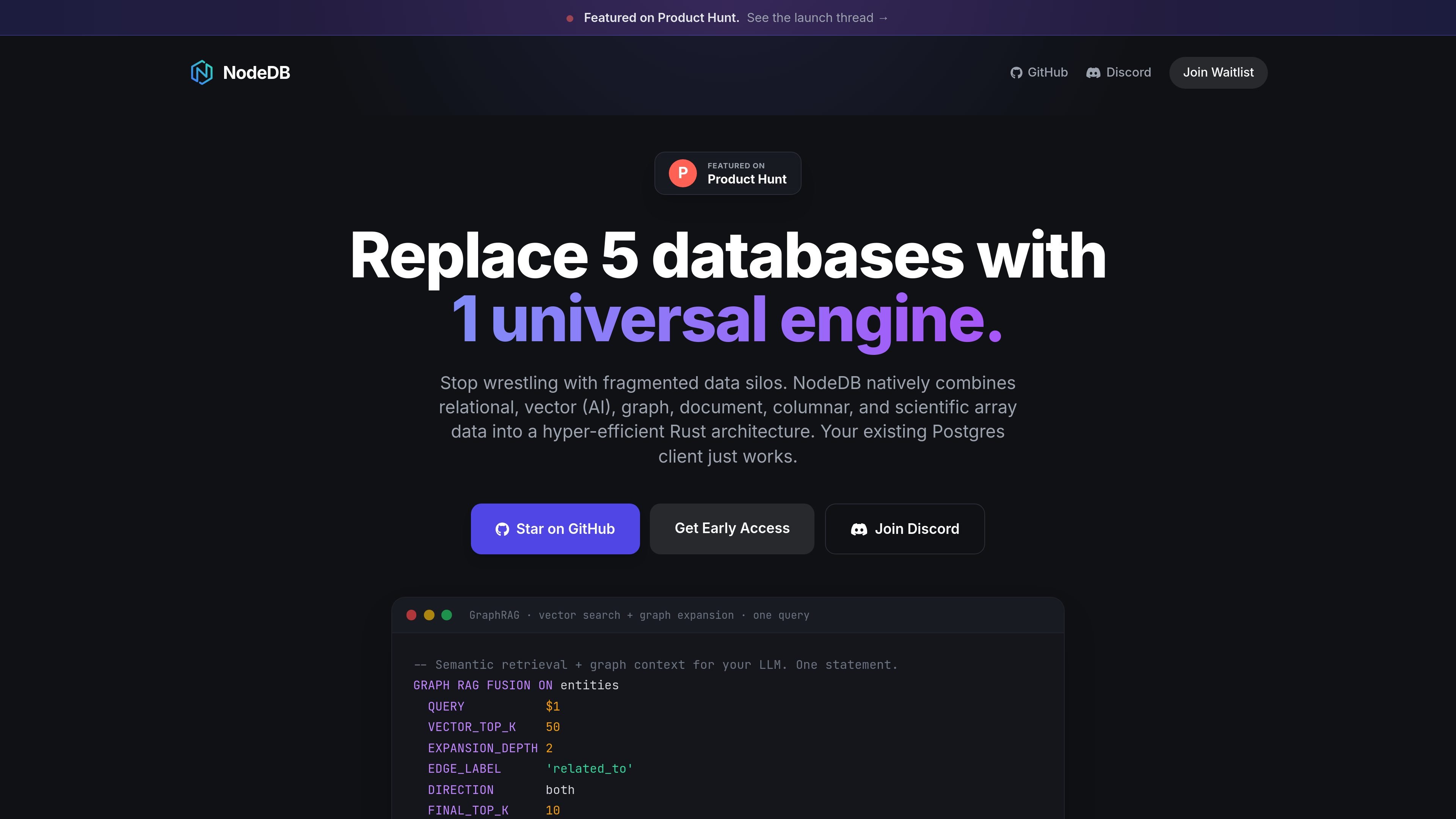
NodeDBは、リレーショナル、ベクトル、グラフ、ドキュメント、カラム型、科学配列データを1つのRustバイナリで統合するユニバーサルデータベースエンジンとして紹介されています。ホームページでは、複数の専用データベースを別々のストア間でデータを移動する代わりに、単一のシステムで置き換える方法として位置づけられています。
製品ページでは、PostgreSQLクライアント互換性も強調されており、ベクトル検索とグラフ展開を1回のクエリで融合するGraphRAG風の例が示されています。提供されたページに基づくと、NodeDBは混在ワークロード向けに1つのデータベース層を求めるチーム、特に意味検索とグラフ文脈の両方を必要とする検索ワークフローを対象としています。
NodeDBは、リレーショナル、ベクトル、グラフ、ドキュメント、カラム型、科学配列データを1つのRustベースエンジンに統合するものとして説明されています。
ホームページでは既存のPostgresクライアントがそのまま動作するとされており、新しいクライアントの操作フローを必要とせずにPostgreSQLクライアントインターフェースとの互換性があることを示しています。
GraphRAGの例では、ベクトル検索とグラフ展開を1つの文で実行し、クエリ時にランク融合が適用されています。
この製品はRustバイナリとして紹介されており、複数サービス構成ではなく単一実行ファイルでのデプロイを示唆しています。
サイトは、断片化したデータサイロを避け、検索ワークフローのために個別のパイプラインやPythonの接続コードを減らすことを中心に製品を位置づけています。
意味検索とグラフ近傍展開を別々のベクトルシステムとグラフシステムで調整する代わりに、1回のクエリで実行したい場合にNodeDBを使用します。
リレーショナルレコードに加えて、ベクトル、グラフ、ドキュメント、カラム型データ、または科学配列を1つのエンジンで扱う必要があるアプリケーションに使用します。
すでにPostgres指向のクライアントを持っていて、そのクライアントのワークフローとの互換性を主張するデータベース層がほしい場合に使用します。
複数のデータベースとサービス間の接続コードを調整するのではなく、単一のRustバイナリを求める場合に使用します。
NodeDBは、リレーショナル、ベクトル、グラフ、ドキュメント、カラム型、科学配列データを1つのRustバイナリで統合するユニバーサルエンジンとして紹介されています。ホームページでは、既存のPostgresクライアントがそのまま動作すると説明されています。
ホームページでは、ベクトル検索とグラフ展開を1回のクエリで組み合わせるGraphRAG風の検索を強調しています。融合クエリの例を示し、このワークフローを別々のパイプラインを使わずにデータベース層で実行するものとして説明しています。
ソースでは既存のPostgresクライアントが動作すると述べていますが、特定のドライバ、API、コネクタは列挙されていません。こうした互換性の主張以外に、提供されたページには詳細な統合一覧はありません。
価格ページのURLはありますが、提供された証拠では現在404を返しています。そのため、利用可能なページからはプラン、価格、または試用の詳細を確認できません。
garden-mdは、会議の文字起こしをローカルの社内Wikiに変換するオープンソースのNode.js CLIです。本文を保持したまま、文字起こし同士のエンティティをリンクして閲覧しやすいWikiを生成します。
Sciteは、論文の検索、引用文脈の確認、学術文献に基づく回答取得に役立つAI研究プラットフォームです。全文ソース、特許、関連研究資料を横断してエビデンスを評価できます。
DrDroidは、クラウド・コード・テレメトリを接続してスタック全体の知識グラフを構築するAI SREエージェント。インシデント調査と根本原因分析を支援し、共有調査や自社ホスト導入にも対応。
Metabase Data Studioは、Metabase内で再利用可能なデータを整備・定義・公開するためのセマンティックレイヤー兼分析ワークベンチです。メトリクス、依存関係、厳選データセットを一貫して保ち、セルフサービス分析や埋め込み分析を支援します。
Datixはスプレッドシート向けAIデータ分析ツール。CSV/ExcelのアップロードやGoogle Drive・Supabase接続で英語の質問に構造化回答・要約・チャートを生成。
Mindspaseは、リンク保存、Spacesでの整理、AI支援ワークフローによる再発見に対応したWebベースのナレッジオーガナイザーです。共同編集、ブックマークのインポート、表示モードのカスタマイズも可能です。